无堵塞的并发编程
顺序编程非常普及,可以说是大多数程序员编程范式,只不过可能他们没有意识到,如今已经进入并发编程时代,顺序编程和并发编程是两种完全不同的编程思路,堵塞Block是顺序编程的家常便饭,常常隐含在顺序过程式编程中难以发现,最后,成为杀死系统的罪魁祸首;但是在并发编程中,堵塞却成为一个目标非常暴露的敌人,堵塞成为并发不可调和绝对一号公敌。
因为无堵塞所以快,这已经成为并发的一个基本特征。
过去我们都习惯了在一个线程下的顺序编程,比如,我们写一个Jsp(PHP或ASP)实际都是在一个线程
下运行,以google的adsense.Jsp为例子:
|
以上JSP中4步语句实际是在靠一个线程依次顺序执行的,如果这四步中有一步执行得比较慢,也就是我们所称的是堵塞,那么无疑会影响四步的最后执行时间,这就象乌龟和兔子过独木桥,整体效能将被跑得慢的乌龟降低了。
过去由于是一个CPU处理指令,使得顺序编程成为一种被迫的自然方式,以至于我们已经习惯了顺序运行的思维;但是如今是双核或多核时代,我们为什么不能让两个CPU或多个CPU同时做事呢?
如果两个CPU同时运行上面代码会有什么结果?首先,我们要考虑两个CPU是否能够同时运行这段逻辑呢?
首先,上面代码中第二步是不依赖第一步的,因此,第一步和第二步可以交给两个CPU同时去执行,然后在第三步这里堵塞等待,将前面两步运行的结果在此组装。很显然,由于第三步的堵塞等待,使得两个CPU并行计算汇聚到这一步又变成了瓶颈,从而并不能充分完全发挥两个CPU并行计算的性能。
我们把这段JSP的第三步代码堵塞等待看成是因为业务功能必须要求的顺序编程,无论前面你们如何分开跑得快,到这里就必须合拢一个个过独木桥了。
但是,在实际技术架构中,我们经常也会因为非业务原因设置人为设置各种堵塞等待,这样的堵塞就成为并行的敌人了,比如我们经常有(特别是Socket读取)
While(true){
……
}
这样的死循环,无疑这种无限循环是一种堵塞,非常耗费CPU,它也无疑成为并行的敌人。比如JDK中java.concurrent.BlockingQueue LinkedBlockingQueue,都是一种堵塞式的所谓并行包,这些并行功能必须有堵塞存在的前提下才能完成并行运行,很显然是一种伪并行。
由于各种技术上的堵塞存在,包括多线程中锁机制,也是一种堵塞,因为锁机制在某个时刻只允许一个线程进行修改操作,所以,并发框架Disruptor可以自豪地说:无锁,所以很快。
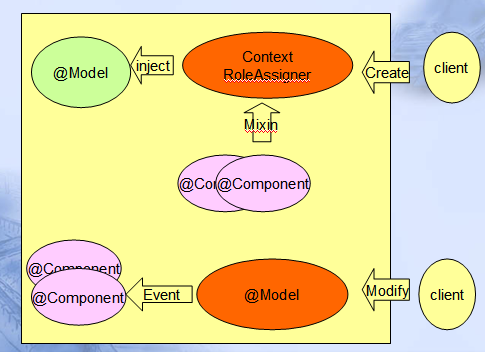
现在非常流行事件编程模型,如Event Sourcing或Domain Events或Actor等等,事件编程实际是一种无堵塞的并行编程,因为事件这个词语本身有业务模型上概念,也有技术平台上的一个规范,谈到事件,领域专家明白如同电话铃事件发生就要接,程序员也能明白只要有事件,CPU就要立即处理(特别是紧急事件),而且事件发生在业务上可能是随机的,因此事件之间难以形成互相依赖,这就不会强迫技术上发生前面Jsp页面的第三步堵塞等待。
因此,在事件模型下,缺省编程思维习惯是并发并行的,如果说过去我们缺省的是进行一个线程内的顺序编程,那么现在我们是多线程无锁无堵塞的并发编程,这种习惯的改变本身也是一种思维方式的改变。
在缺省大多数是并发编程的情况下,我们能将业务上需要的顺序执行作为一种特例认真小心对待,不要让其象癌细胞一样扩散。我们发现这种业务上的顺序通常表现为一种高一致性追求,更严格的一种事务性,每一步依赖上一步,下一步失败,必须将上一步回滚,这种方式是多核CPU克星,也是分布式并行计算的死穴。值得庆幸的是这种高一致性的顺序编程在大部分系统中只占据很小一部分,下图是电子商务EBay将他们的高一致性局限在小部分示意图:
由此可见,过去我们实现的顺序编程,实际上是我们把一种很小众的编程方式进行大规模推广,甚至作为缺省的编程模式,结果导致CPU闲置,吞吐量上不去同时,CPU负载也上不去,CPU出工不出力,如同过去计划经济时代的人员生产效率。
所以,综上所述,以事件编程为范式的无堵塞并发是一种趋势,下面关键问题是哪种事件编程范式更简单,更易于被程序员理解掌握了。
相关话题:
为什么要用Event Sourcing?