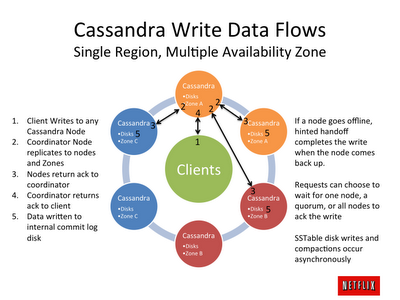
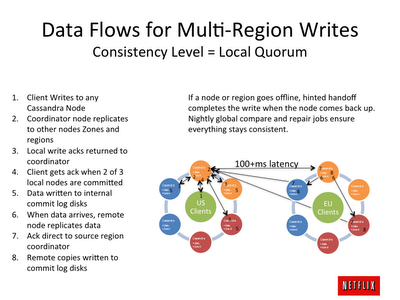
NetFlix测试Cassandra:-每秒百万次写
测试云产品的工具也需要云,Netflix最近使用Amazon的云计算对云存储NoSQLCassandra进行了一次性能测试:
The Netflix Tech Blog: Benchmarking Cassandra Scalability on AWS - Over a million writes per second
Netflix已经使用Apache Cassandra NoSQL作为生产环境数据存储已经六个月了,他们测试部门决定对其进行一次全面的性能测试。通过这次测试帮助开发队伍更加有效地使用Amazon的Aws。
这次测试是基于Amazon的云计算平台AWS进行的,他们把Cassandra部署在Amazon的EC2服务器中,一共创建了288个实例,分散在美国东部三个地方,每个地方96个实例,另外使用60实例用户客户端测试,运行每秒1.1百万的压力程序,三个不同数据中心之间以每秒3.3百万写操作进行数据复制。整个测试在两个小时内完成,花费几百元。
测试时是从48 96 144到288实例逐步增加的,测试显示吞吐量也是线性增加,测试软件使用Cassandra 0.8.6,完全是生产环境配置,EC2创建288个用了15分钟,共66分钟,剩余时间启动Linux和Tomcat JVM已经在其上运行自动测试程序,启动Cassandra JVM等等。
配置是使用EC2的m1.x1规格服务器,四个中速CPU 15G内存,4个400G硬盘,也有使用m2.4xl规格 八CPU 68G和两个800G硬盘,网络环境都是每秒1G带宽,操作系统是CentOS 5.6和XFS,Cassandra的commit日志和数据文件保存在磁盘文件系统。60测试客户端是使用m2.4xl服务器。
所有测试实例创建都是使用EC2的ASG(auto-scale group ()创建,创建三个ASG,EC2创建他们并且维护管理,一旦ASG发现一台崩溃,就立即使用备份服务器,而NetFlix的工具是负责这时的Cassandra集群在新服务器上的启动。下面是ASG配置缩图:
[该贴被admin于2011-11-19 10:35修改过]
[该贴被admin于2011-11-19 10:36修改过]