Martin Fowler厌倦ORM了
Martin fowler几年前曾经非常推崇ORM(对象/关系数据库映射框架),特别是Hibernate和Ruby的Active Record,现在他面对大家越来越多对ORM责难和怀疑。他写了这篇新的文章:ORM的厌倦(OrmHate),下面大概谈谈他这篇文章大意。
首先,MF为ORM带来的复杂性做了辩解,对象和关系数据库存在天然阻抗,试图调和总是带来复杂性。他也认为:The object/relational mapping problem is hard,试图在对象和关系数据库之间进行映射是很难的,因为你需要处理两种不同角度视图中的数据,一个是关系数据库中,还有一个是内存中in-memory,这两者常常是由ORM实现,这里一点和对象没有关系,准确地说,ORM实际是在进行内存(in-memeory)和关系数据库之间映射,内存数据结构比关系模型要更灵活,大多数人更愿意使用这种内存数据结构,然后将其再保存持久到数据库中。
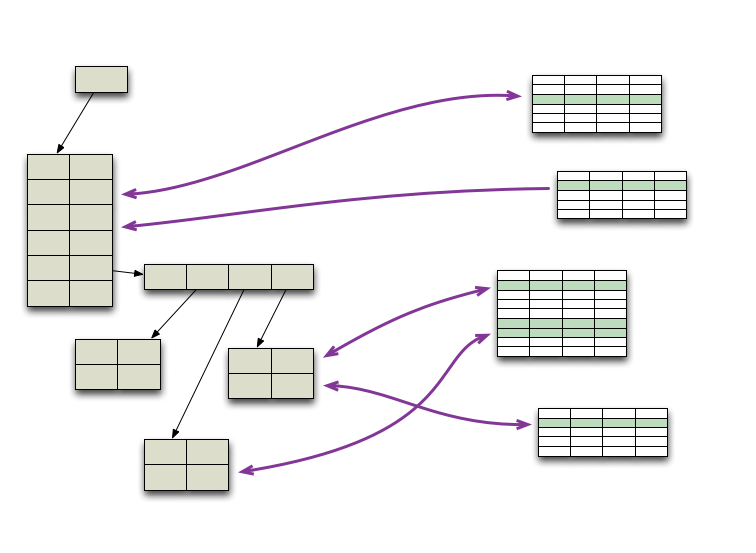
这种映射要比我们想象复杂得多,因为你一旦在内存改变数据结构,就必须映射同步到另外一边,如果有多个操作同时并行修改数据库就更复杂,ORM得处理这种并发,这种情况下你不能依赖事务机制,因为当你摆弄内存中数据,你是不能hold住事务的(通常通过数据库锁hold住)。
那么有没有ORM的替代呢?
MF提出两个解决方案:MF认为Hibernate 和 Active Record 已经是一个膨胀化软件,他看到很多人开始做自己系统的ORM,这是非常厉害的,但是他们没有意识到已经掉入泥潭,MF认为对象和关系数据库的映射如同计算机科学中的越战。
虽然很多ORM框架如 iBatis, Hibernate, 和 Active Record做了很多努力解决了很多问题,但是关键问题还是存在,ORM能够解决80%-90%的问题,但是剩余的问题就必须理解ORM和关系数据库内部工作机制才能解决。
MF认为这实际就是正确使用ORM的方式,他以Ruby中Active Record创造者David Heinemeier Hansson的话为例子,ORM帮助你处理掉了大部分无聊垃圾代码,但也提供了一个管道和沙井,让你直接处理SQL语句。
但是人们常常抱怨,为了使自己的对象模型更适合ORM,屈就ORM,只能变得更加具有关系化,MF认为这是使用关系数据库的必然结果,你要买使你的内存模型更加关系化,要么复杂化你的映射代码,为了简化你的对象和关系数据库映射,你最好哦让你的领域模型更加具有关系化,但是并不意味着你得按关系模型设计领域模型。
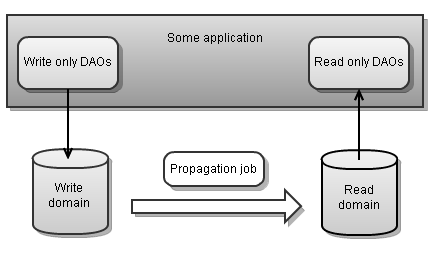
ORM是复杂的,因为它得处理双向映射,如果只有单向映射,问题复杂性也许就会解决,前提是你感觉SQL不复杂,这就是CQRS(读写分离)。