Apache Helix让分布式管理更方便
在NoSQL和大数据领域,随着爆炸式的数据增长,分布式系统的数量有了显着增长。 多年来,我们在LinkedIn已经建立了一个分布式系统,该系统上运行多台服务器的集群并保证容错性 - 保证在出现服务器故障和网络问题情况下系统是可用的 - 这是任何分布式系统的关键。 这样才能通过水平的横向扩展性和无缝的集群扩展处理日益增加的工作量。
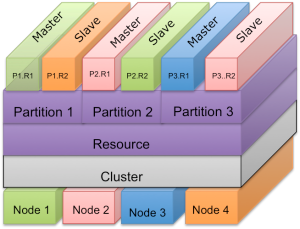
在一组自治的过程中的每一个被称为一个实例instance,共同构成一个集群。 与参与者共同执行或支持一个任务,这被称为资源resource。 资源是一个逻辑实体,可以跨越许多实例。 例如,数据库,主题topic,索引或任何计算/服务的任务可以被映射到一个资源。 资源可以进一步细分成子资源或子任务,被称为分区partitions。 分区是和一个实例相关的资源的最主要组成部分,因此不可能跨越多个实例,的一个实例,这意味着一个分区不能跨越多个实例,分区可以有多个副本以支持容错和/或可扩展性,每个副本都称为复制replica。
上述的术语是很通用的可以映射到任何分布式系统。 但是,在具体不同的分布式系统,它们的功能和行为显著不同。 例如,一个搜索系统,用于支持查询的行为肯定和读取可变数据行为是不同的。 因此,为了有效地描述一个分布式系统的行为,我们需要定义资源和分区的各种状态,用来捕捉各种有效状态和状态转换。 Helix使用一个有限状态机 (FSM)实现这个功能。
如下图:
FSM本身描述所有系统中的不变量是不够的 - 我们仍然需要一种方法来捕捉所需的系统的行为时,集群拓扑结构的变化。 例如,当一个节点出现故障时,我们可以选择创建新的副本,更改现有副本的状态。 当新节点添加到集群中,我们可以重新立即或逐步地分区分配到新节点。 这些都是常见的问题,但是对于人工维护来说对付所有可能出现的情况是困难的。
Helix可以通过约束constraints 和目标Objectives,状态机中每个状态可以定义为约束,你可以指定约束的不同粒度,比如分区,资源,实例,集群。
下面是约束和目标的一些举例:
状态约束State constraints:
分区周期Partition scope: 1 Master, 2 Slave
实例周期Instance scope: 每个节点最多10个分区
状态切换约束Transition constraints:
在cluster=5的状态切换最大bootstrap(通过网络拷贝数据)的数目是多少。
目标Objectives:
分区的均匀分布
在不同节点之间复制。
以最小运行对一个节点进行failure/addition/removal发布
基于这些概念,集群管理的定义如下:
对于一组实例和资源,并带有系统的状态约束,这种情况下,计算满所有足约束的实现分区到实例的分配方式。
Helix就是这样一个用户简化管理分布式系统的集群管理框架。
Distributed Systems Get Simpler with Apache Helix
[该贴被banq于2013-10-17 12:28修改过]