这是一篇讨论Node.js在无需修改任何代码从单核垂直扩展到多核,再水平扩展到多台集群和消息集成的分布式系统,展示了Node.JS在无缝扩展性方面要强于Java。其主要架构是Node.js微服务 + 消息Messaging + 集群Clustering 。翻译如下:
当使用微服务创建一个复杂的分布式系统时,关键问题是提供服务之间的通信,微服务一般使用REST API,你一般会缓存远方的状态,但系统是在不断地变化,也许你状态已经过期了,你可以通过轮询刷新你的拷贝,但这是不可扩展的,增加系统压力,很多重复的请求通常反而得不到最新的状态( ‘不,还没有新的消息。别再重复问了。”)
更好的方式是反转信息流,让服务拥有数据当发生变化时主动告诉你。这是来自微服务为基础的消息系统,这需要某种消息代理。
另一个重要的特点是可扩展性Scalable。你可能需要迅速提高你的处理能力,垂直或水平伸缩扩展微服务能力是关键。
水平和垂直扩展
通常认为从Java迁移到Node.js的开发人员其实并不真正理解水平扩展的含义,因为在JEE容器中线程池实现了魔术的处理,增加真实或虚拟的服务器其实不需要软件这边做出什么修改,举例,如果你为你的JVM增加CPU核数,JEE容器会扩展利用它们,如果你增加更多内存,你就需要微调JVM参数才能充分利用扩大的内存,否则它像以往一样工作,这时你可能需要重新启动多个JVM, 在这点上你发现你的JEE应用实际并不是以集群方式编写的。
在Node.js这里,增加更多CPU核数其实也不难做到,使用PM2如下命令:
pm2 start app.js -i max
无论如何,对于Node.js水平或垂直扩展是不管你编写代码的方式,你只需要通过集群利用在同一台机器上所有CPU内核,不用像Java那样需要在多个独立的服务器或虚拟机实现负载均衡。
我真的喜欢Node.js这个特性–它迫使你从一开始就要考虑集群,阻止你在请求之间持有数据,迫使你存储状态到一个共享的数据库中,这个数据库能够被所有正在运行的实例访问。这使得从垂直到水平的扩展性切换,根本不影响你。这里没什么新的东西,只是基本的share-nothing的好处。
然而,使用PM2加载多个Node.js或使用Node的集群模块与使用Nginx代理作为负载平衡器之间是有重要区别的:使用Nginx 作为代理服务器时,我们有一个独立的绑定到一个机器上的一个端口服务器,负载平衡和URL代理同时已经完成。在Nginx中是这样配置:
|
如果你试图在单台机器上启动多个Node服务器时,除了第一个都将失败,因为它们(srv1. srv2. srv3.)不能绑定到同一个80端口上,然而,如果你使用Node的集群模块或使用PM2,会有一点魔法发生,主进程有一段代码会激活Socket在多个工作进程之间共享,使用了一种共享策略(或者使用操作系统定义 或者Node 0.12的’round-robin’),这非常类似于Nginx在不同服务器之间为你做的事情,Nginx也有负载平衡的选项(round-robin, 最少连接, IP-hash, weight-directed重导向等).
消息
下面我们将消息和集群两个概念放在一起。
为了让事情变得更具体生动,让我们看一个真实世界的例子。我们已经编写的活动的流微服务。它的工作是收集活动流规范2草案中的活动,并将它们存储在cloudant数据库,这样它们以后可以作为一种活动流检索。这项微服务做一件事情,并且做得很好–它聚集来自系统任何地方的活动–然后发射一个活动到一个专用的MQTT主题。
我们使用mqtt作为MQTT客户端,RabbitMQ作为我们的多语种消息代理,Node.js作为我们的活动微服务,这已经是我们不止第一次这么架构了。
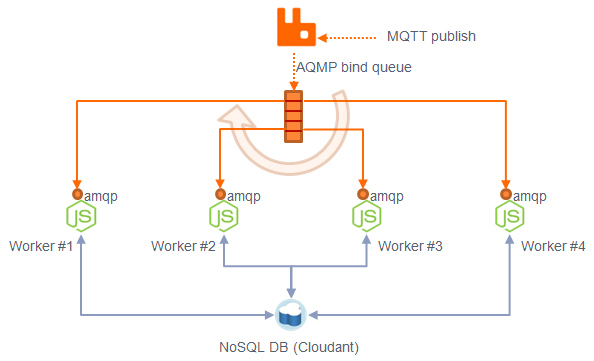
当前面谈的集群加入其中时,MQTT是一个pub/sub协议.为了让每个订阅者从队列中读取消息, RabbitMQ为集群中每个Node实例开设一个单独队列实例。

但这并不是我们需要的,每个实例都将收到一个“新活动”消息,并试图将它写入数据库,数据库这里需要避免竞争。即使数据库可以阻止其他Node保证只有一个Node节点成功写入记录,这也是一种浪费,因为所有的Node节点都在执行同一个任务。
这里的问题是,用于集群模块“白魔法”来处理HTTP / HTTPS服务器请求但并没有延伸到MQTT模块。
我们解决这个问题原始想法是,如果我们迁移消息客户端到主实例,它会对进来的消息响应,然后传递他们到后面的从工作实例,以round- robin方式,这似乎是合理的,但需要调整一个ICK参数,因为需要我们自己实施自己的负载平衡,它会阻止我们使用PM2(因为我们必须对从工作实例进行控制),如果我们使用多个虚拟机和Nginx的负载平衡,我们将回到原点(Nginx并不支持单机同一个端口的负载平衡)。
幸运的是,我们发现RabbitMQ已经可以处理这部分,如果我们放弃持久,并且确认我们是MQTT抽象下运行AMQP。RabbitMQ的pub / sub拓扑方式是:发布者提交到 “主题”交流,然后被绑定到一个使用路由作为Key的队列上(事实上,在AMQP路由key和MQTT主题topic有直接映射)。
原来使用MQTT客户端使得每个群集实例接收自己的队列。现在通过迁移到AMQP客户端和将所有实例绑定到同一个队列,我们让RabbitMQ对客户端使用round-robin实现基本负载平衡。
下面是使用Eclipse PAHO Java客户端发布MQTT消息给主题Topic代码,使用Node.js或•Ruby等其他客户端几乎一样:
|
上面是发出消息到‘activities’主题,下面是接受消息,然后将队列使用匹配的路由key(还是‘activities’)和缺省的AMQP主题交换(topic exchange (“amq.topic”))绑定,队列的名称不重要,只要所有Node的服务器都使用同一个即可,实际上名称在它们之间会相互复制。
|
[该贴被banq于2014-04-24 12:27修改过]