Twitter的分布式日志DistributedLog
Twitter的开源DistributedLog是一款高性能复制日志服务,能提供持久的可复制的强一致性(分布式事务机制),可以作为基础构建设施用于创建可靠的分布式系统,例如可复制的状态机(replicated-state-machine)、一般的pub/sub系统、分布式数据库和分布式队列等。是Kafka的竞争产品。
分布式系统一般使用日志来构建可靠的复制性系统有两种范式,如下图:

pub-sub范式通常是一种active-active模型,保留进来请求的日志,而每个复制者(reader)读取这个日志处理每个请求,而主-从Master-Slave范式是选举一个复制者作为一个主服务器来处理请求,记录导致状态改变的日志,其他复制者作为从服务器读取日志,按照主服务器状态改变次序改变自己的状态,从而实现与主服务器的同步,并时刻准备在主服务器失败时接管。如果当前主节点服务器因为网络分割导致无法与其他从节点服务器连接,这些从节点服务器会选举一个新的主服务器继续当前进程,一个fencing围栏机制是用于发现旧的主服务器和其他成员失联,并在它恢复联系以后阻止它再修改状态(因为失联期间已经有新的主服务器接过它的大旗继续向前,它恢复后不能再做相同工作了)。
这两种不同范式代表两种不同的次序需求:Write Ordering 和 Read Ordering,Write Ordering 需要所有作为日志写入者的写操作都以严格的次序写入日志,而Read Ordering仅仅需要任何读取日志的读操作者只要从指定的位置开始都能看见相同的次序,有可能日志记录不是以相同次序写入的。可复制的日志服务应该都支持者两种用例。
分区Partitioning (也称为sharding分片或 bucketing) 是一种水平扩展,分区方案依赖应用的特点,也和应用的次序保证紧密相关,比如,分布式key/value存储可以使用DistributedLog 作为它的事务日志,每个分区代表一致性的一个单元,在每个分区内部的修改操作都需要严格的次序。如果是一个实时分析系统则就不需要严格的次序,可以使用round-robin分区策略,在所有分区中均匀分配所有读操作和写操作。这些都是依赖应用的特点灵活选取合适的分区策略。
在处理语义方面,一般应用会在至少一次at-least-once 和精确一次exactly-once之间选择。
at-least-once能够保证应用处理所有的日志记录,当应用从失败中恢复,先前处理过的记录如果没有被确认也许会重新再被处理。而exactly-once处理是稍微严格的保证应用必须看到精确一次处理每个记录的效果,exactly-once语义能够通过维持读操作者读取日志的位置以及对应的应用状态实现,会原子性地同时更新读操作者的日志读取位置和对应的日志记录,比如:对于在分布式key/value存储中强一致性更新,读操作者的读取位置必须和对应的日志记录一起原子性同时持久存储,当从失败中重新恢复时,读取者会继续从上次持久保存的读位置再次继续开始,这样保证每次变动都是只有一次。
使用at-least-once语义,应用将存储读者的读位置在外部存储中,定期地更新,而不像exactly-once那样和读操作一起同时原子更新,当失败恢复后,应用会重新处理失败前最后保存的那个读取位置。
架构
DistributedLog类似一个大型队列Queue,其中维持中日志记录顺序,也成为日志流,写操作专门负责将写入记录,读操作专门从记录流中读取日志。如下图:
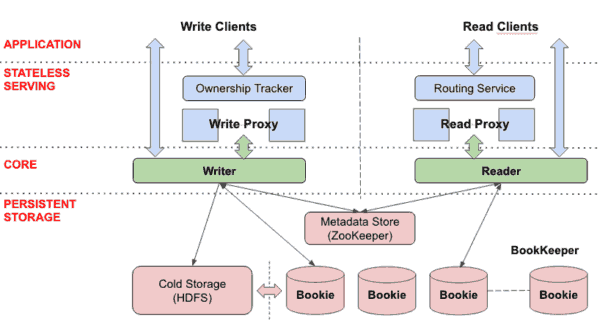
与CQRS架构的读写分离是一致的。
DistributedLog日志是一种有次序的不可变的记录顺序,日志记录是顺序地写入日志流,每个日志记录分配一个唯一顺序号称为DLSN(DistributedLog Sequence Number),除了DLSN,应用也可以在构建日志记录时分配它自己的顺序号码,应用自己定义的顺序号码称为TransactionID (txid),无论DLSN 或 TransactionID都能被用于读操作进行位置定位,从而从某个指定的日志记录开始读取。
每条日志还切分段segment,每个日志段包含其日志的子集,日志段是可分布的,能够存储在日志段存储中,比如Apache BookKeeper,日志段基于配置生成,称为rolling policy,包含定期时间比如每2小时,和最大大小比如每个128M。这样,日志数据被切分为同等大小的日志段,跨多个存储节点分布,这就能让超过特定大小的日志也能适合单个服务器保存,在集群之间减少读取的流量。
详细介绍:
Considerations — DistributedLog 1.0 documentation