全新角度总结Twitter Facebook和LinkedIn业务模型与架构
本文从流处理、事件溯源Event Sourcing、Reactive和EDA/CEP角度总结Twitter Facebook和LinkedIn的业务模型与架构设计特点。
通常一个网站系统的架构设计取决于其业务特点,Twitter Facebook和LinkedIn业务特点是:大量不断动作事件写入的同时,需要实时更新各种不同汇总页面。属于并发编程中大量并发写和大量并发读同时存在的场景。
Stream processing, Event sourcing, Reactive, CEP… and making sense of it all一文对这种业务模式进行了总结,并指出了流处理、事件溯源Event Sourcing、Reactive和EDA/CEP内在的逻辑一致性。
在普通数据库范式下,比如一个博客系统,用户发出一篇博文,其他用户可从时间线浏览该用户的发表的博文。通常我们会设计一个博文的数据表结构,其中字段有:博文内容 发布时间等,用户发出的博文写入存储到这个数据表中,而其他用户阅读这个用户的博文列表则通过"select * from 博文 where useId=xxx"这样SQL语句实现。
因为博文比较长,不太可能同时有大量用户发表长文,所以,可能不存在大量写操作,但是如果是微博系统,有大量用户经常发布微博,这就存在大量动作事件写入;同时,又有大量粉丝不断查询读取该用户的微博列表,包括其他各种信息。
这种业务模型特点在Twitter Facebook和LinkedIn存在很明显:
Twiiter
最普通的Twitter设计是将用户发布的微博存储到关系数据库中,一个微博很简单:一些内容,时间戳和ID,用户只要点击"发布"这个按钮就会引起数据库的一个写操作。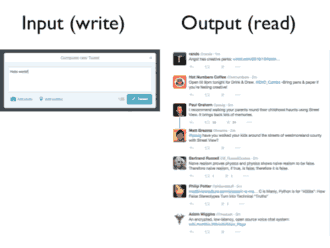
另外一个方面,阅读者是从时间线读取Twitter数据库,如上图的Output(read)。这两个方式的数据结构也是完全不同的,如下图:
阅读时,对于每条微博Tweet,不只是有微博的基本内容,而且有用户的名称,照片和发布信息,以及粉丝数量等等。
那么你如何从简单的输入转变到这种更加复杂的输出呢?当然,普通方式使用关系数据表设计一个数据表结构,然后将微博数据插入其中,再用下面SQL读取:
这是以时间先后查询最近100个Tweet,当然,更有甚者,会通过存储过程等语句提高性能,但是这种查询却无法伸缩扩展,而且给数据库带来非常大的负载。
当一个用户浏览他的时间线时,遍历他关注的那些人的Tweet也是很昂贵的,SQL查询是非常耗时的,开始,Twitter是提前计算用户的时间线,然后缓存结果,这样用户查看时会很快,为了这样做,他们需要一个处理过程来将适合写操作的单个事件翻译成适合读操作的汇总聚合,称为fanout service.
Facebook
它有许多按钮比如like让你写些什么然后保存到Facebook的数据库中,当你点按Like时,就产生一个事件,数据结构很简单:用户ID以及所喜欢的条目ID。
如果从输出方面看,也就是从Facebook读取,这时会意想不到的复杂,不只是有喜欢的内容,还有作者名称和照片,然后显示有160216个人喜欢,有6027分享和12851评论,输入和输出数据结果如下:
这种输入到输出的翻译过程大概是这样:将简单的一个个事件作为输入,产生复杂的个性化的数据结构,你不能想象有什么数据库能够在一边更新一边输出这么多信息。也就是说,对于这样一个有100000个喜欢不断产生,而你要实时不断输出这些喜欢的输出内容,这种大量动态更新和大量读取同时操作的场景使用缓存和数据库都是很难实现的。
从以上Twitter和Facebook案例我们能发现一个重复出现的模式:输入事件,对应用户界面某个按钮,而且非常简单,不可变的,我们只是简单地存储它们,我们将它们看成是真相来源source of truth。
从网站上看到的每个内容都是从这些原始事件读取,有一个处理进程专门从原始事件产生汇总结果,当新的事件不断进行,不断更新缓存,这个处理进程是确定的,可以重新启动。你可以将网站上发生的每件事都喂给这个进程,你甚至可以重构任何时刻的缓存,这是一种cached view of the event log.。
LinkedIn
以LinkedIn为案例,每个人发布自己的当前工作情况,这些事件写入数据库,而读取页面有各种各样,这里以搜索为例,当你输入一些关键词,比如公司名,那么在这个公司的所有人员都应该出现在提示框中。
为了实现搜索,你需要搜索索引,这个索引其实是另外一种聚合结构,当有新的数据事件加入,这个结构也需要跟随新数据变化。
总结
总结以上Twitter Facebook LinkedIn的模式如下: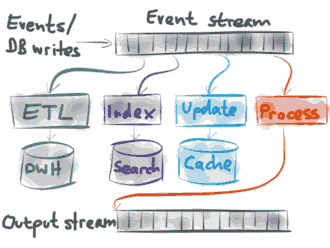
大量持续不断的单个事件写入数据库中,这也就是一种事件流,根据这个持续不断的事件流,你能够构建不同的聚合结构,如View视图 缓存和搜索索引,你还能设置一个独立的Process处理过程,翻译转换到输出流output stream;总之,有了事件流,你能依据这个流做很多事情。
1.你能将所有事件转换到一个大数据仓库,在那里可以进行数据分析和查询。
2.你能更新完整文本搜索索引,这样当用户点击搜索框时,能够搜索到实时的数据。
3.你能使用事件对缓存进行更新,这样缓存能够方便快速读取最新数据。
4.最后,你可以将一个事件流转换到另外一个输出流,作为其他系统的输入,这样能够串联起一个复杂的事件驱动大型系统。
不管怎样,传统数据库也采取这种事件处理方式进行读写,比如像PostgreSQL, MySQL's InnoDB 和Oracle, 和 append-only B-trees of CouchDB, Datomic 和LMDB 等MVCC数据库都是相同类似思想。这里我们是将数据库引擎内部机制作为应用程序架构来实现。
总之,大量事件写操作伴随同时大量读操作发生的这种互联网新模型催生了新的解决方案,在简单读写场景下可以使用关系数据库直接完成,但是这种复杂大数据量并发场景关系数据库已经不能胜任,只能打开数据库这个盒子,将数据库引擎实现的模型搬出盒子,迁移到服务层或微服务中实现,从而能够保证高可用性和高一致性。当然,由于涉及到分布式系统,虽然横向扩展伸缩非常好,但是也需要结合CAP定理进行设计权衡。
更详细对原文解释可见:
如何理解Stream processing, Event sourcing, Reactive, CEP?
[该贴被admin于2016-08-14 16:41修改过]
[该贴被admin于2018-09-07 15:27修改过]