以正好一次(Exactly-Once)方式传递数十亿消息
所有数据流水线的唯一要求是它们不能丢失数据。可以延迟或重新排序,但不能丢失。
为了满足这一要求,大多数分布式系统实现至少保证一次(least-once)传递。实现至少一次传递的技术通常等于:“重试,重试,重试”。直到在收到消费者的确认之前,否则永远不会认为发送消息已经成功。
但作为一个用户,“至少一次传递”并不是真的想要的。我希望消息只被传送一次。而且只有一次(精确一次)。
不幸的是,实现任何接近于一次交付的设计都需要考虑防弹防故障设计。每个故障情况都必须作为架构的一部分认真考虑 - 但是只有在其发生成为事实之后,才能被“锁定”进而才能采取对策,融入现有的实现。即使这样,只有一次传递消息还是不可能的。
在过去三个月中,我们构建了一个全新的重复数据删除系统,以便在面对各种故障模式时尽可能接近交付。
新系统能够跟踪旧系统的消息数量,增加可靠性,只需一小部分成本。就是这样。
问题
Segment系统的大部分内部系统都是通过重试、消息重新发送、锁定和两阶段提交来处理通常故障。但是,有一个特别的例外:将数据直接发送到我们公共API的客户端。
客户端(特别是移动客户端)有频繁的网络问题,可能在发送数据时错过了我们API的响应。
想象一下,您乘坐公共汽车,使用HotelTonight从iPhone预订房间。该应用程序开始将使用数据上传到Segment的服务器,但您突然通过隧道并失去无线信号与连接。您发送的某些事件却是已被处理,但客户端从未收到服务器响应。
在这些情况下,即使服务器在技术上已经收到了这些确切的消息,客户端也会重试并将相同的事件重新发送到Segment系统的API。
从我们的服务器指标来看,每四周大约有0.6%事件是重复的。
这个错误率可能听起来不重要。但是,对于一个产生数十亿美元收入的电子商务应用程序,0.6%的差异可能意味着利润和数百万美元的损失。
删除重复消息
所以我们了解问题的症结 - 我们必须删除发送到API的重复消息。但是会怎么样呢?
通过高级API对任何重复数据的删除都很简单。在Python(也称伪伪代码)中,我们可以将其表示为:
|
对于我们流中的每个消息,我们首先检查我们是否看到了由其id(我们假设是唯一的)唯一指定的消息。如果是,表示重复了就丢弃它。如果是新的,我们会重新发布消息并以原子方式提交消息。(这样做引入一个新问题,需要存储过去的消息)
为了避免存储所有的消息,我们会将“删除重复数据窗口”定义为key的存储时间,过了这个窗口时间就自动失效这个键值。消息在掉在这个窗口期外面,我们也将它们老化失效。我们要保证在窗口期内只发送一个指定ID的唯一的单个消息。
这种解决问题的方式虽然很容易用语言描述,但实际中有两个方面需要特别注意:读/写性能和正确性。
我们希望我们的系统当面对数十亿次消息时消除够重复事件,并以低延迟和低成本的方式来实现。
更重要的是,我们希望确保我们看到的哪些事件能够被持久写入,以便我们可以从崩溃中恢复,并且也不会在这种恢复输出中产生重复的消息。
架构
为了实现这一点,我们创建了一个“两段two-phase”架构,它读取卡夫卡,并且在四周的窗口时间内将所有重复事件删除。
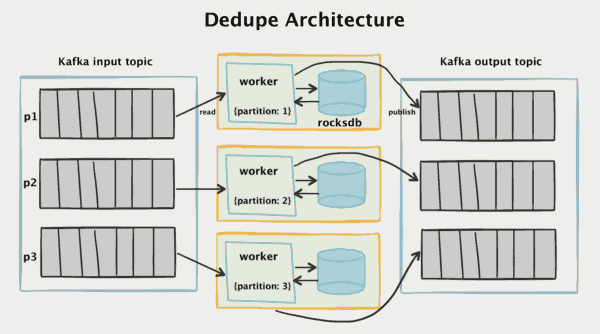
要了解该架构是如何工作的,我们可以首先看看Kafka流拓扑。所有传入的API调用都将分离为单独的消息,并读取Kafka输入主题。
首先,每个传入的消息都被一个由客户端生成的唯一ID标记。在大多数情况下,这是一个UUIDv4(尽管我们考虑切换到ksuids)。如果客户端不提供messageId,我们将在API层自动分配一个。messageId
我们不使用向量时钟或序列号,因为我们想减少客户端的复杂性。使用UUID可以让任何人轻松地将数据发送到我们的API,因为几乎所有的主要语言都支持它。
|
单个消息被卡夫卡的耐久性和重播能力记录下来。它们由MESSAGEID分隔,这样确保同一messageId总是由相同的消费者进行处理。
这对于我们的数据处理来说是一件很重要的事情。我们可以通过路由到正确的分区来缩小搜索空间的数量级,而不是搜索中央数据库在数百亿条消息中寻找key主键。
重复数据删除“工作者”是一个Go程序,它读取Kafka输入分区。它负责阅读消息,检查它们是否是重复的,如果它们是新的,将它们发送到Kafka输出主题。
根据我们的经验,工作者程序和Kafka拓扑结构非常容易管理。我们不再需要一组有发生故障时进行副本切换的大型Memcached服务器系统了。相反,我们只使用零协调需要的嵌入式RocksDB数据库,并以非常低的成本获得持久存储。
RocksDB工作者
每个工作者Job在本地的EBS硬盘上存储一个本地的RocksDB数据库。RocksDB是由Facebook开发的嵌入式键值数据存储,经过优化,性能非常高。
每当输入主题的事件进来时,消费者查询RocksDB来确定是否看到过该事件messageId。
如果RocksDB中不存在该消息,我们将其添加到RocksDB中,然后将消息发布到Kafka输出主题。
如果消息已存在于RocksDB中,则工作者Job根本就不会将其发布到输出主题,并更新输入分区的偏移,并确认已处理该消息。
性能
为了从数据库获得高性能,对于每个事件我们必须满足的三个查询模式:
1.检测随机进来的Key是否存在,但可能不会只在我们的数据库中,可以在我们的Key空间的任何地方找到。
2.以高写入吞吐量编写新key
3.失效旧key,这是指对于那些超过“删除重复数据窗口”时间的消息。
实际上,我们必须不断地扫描整个数据库,追加新的key,并失效老化旧key。理想情况下,这些数据库存储key方式只会以同一数据模型存在。

一般来说,性能的大部分取决于数据库性能,所以值得了解RocksDB的内部性能。
RocksDB是一个日志结构合并树(LSM)数据库,这意味着它会不断地将新的key附加到磁盘上的预写日志write-ahead-log中,以及将排序的多个key作为memtable的一部分进行存储内存中。
写入key是非常快速的过程。新数据以追加append方式(为了直接持久性和故障恢复)直接记录到磁盘,并且数据条目在内存中排序,以提供快速搜索和批量写入的组合。
每当向memtable写入足够多条目时,它将作为SSTable(排序的字符串表)持续存储到磁盘。由于字符串已经在内存中排序,所以可以将它们直接flush到磁盘。
以下是我们的生产日志中flush的示例:
|
每个SSTable是不可变的 - 一旦创建,它永远不会改变 - 这就是为什么写入新的键key会这么快原因。没有文件需要更新,没有写入扩展。相反,在out-of-band压缩阶段,同一级别的多个SST可以合并成一个新的文件。
当在同一级别的单个SSTables被压缩时,它们的key被合并在一起,然后将新的文件升级到下一个更高的级别。
查看我们的生产日志,我们可以看到这些压缩作业的示例。在这种情况下,作业41正在压缩4级0文件,并将它们合并为单个较大的1级文件。
|
压缩完成后,新合并的SSTables将成为数据库记录的确定记录集,旧的SSTables将被取消链接。
如果我们登录到生产实例,我们可以看到正在更新的预写日志以及正在写入,读取和合并的单个SSTable。
日志和最新的SSTable主导了I / O
如果我们来看看生产中的SSTable统计数据,我们可以看到我们共有四个文件级别,每个级别都有更大和更大的文件。
RocksDB保留SSTables本身存储的特定的索引和布隆bloom过滤器,并将它们加载到内存中。然后查询这些bloom过滤器和索引以便确定能查找到指定的key。然后将完整的SSTable作为LRU基础的一部分加载到内存中。
在绝大多数情况下,我们看到新的消息 - 这使得我们的删除重复数据系统成为了bloom过滤器的教科书经典用例了。
bloom过滤器会告诉我们一个键key是否“可能在集合中”,或者“绝对不在集合中”。为了做到这一点,bloom过滤器保留了已经看到的任何元素的各种哈希函数设置位。如果一个哈希函数的所有位都设置了,则过滤器将返回“该元素可能在集合中”。
如果响应“可能在集合中”,则RocksDB可以从SSTables查询原始数据,以确定该项目真的是否在该集合中实际存在。但在大多数情况下,我们可以避免查询任何SSTables,因为过滤器将返回“绝对不在集合”响应。
当我们查询RocksDB时,我们会发布一个MultiGet查询我们想要查询messageIds的所有相关内容。能够提升性能,同时避免许多并发锁定操作。它还允许我们批查询来自卡夫卡的数据,并且通常顺序操作的方式可以避免随机写入。
接下页