YugaByte DB:高性能的分布式ACID事务的开源数据库
在分布式数据库领域中,高性能 + 强一致性事务是代表数据库水平高低的重要象征,这个领域最高水平的数据库是Google Cloud Spanner和Azure Cosmos DB以及Apple最近开源的FoundationDB,YugaByte DB是这个领域的另外一个开源数据库,虽然知名度不高,也没有经过生产实践检验,但是相比google大公司把这种技术当成看家本事不示于人的做派相比,YugaByte DB设计思想可以通过源码共享与世人。下面是原文翻译:
在开发面向用户的关键业务应用程序时,使用ACID事务是一个基本的构建技术。它确保了数据完整性的同时又支持能高度并发操作的复杂任务。尽管ACID事务被认为是关系数据库中理所应当具备的特性,但分布式的NoSQL /非关系数据库目前采取的策略是:要么完全抛弃ACID事务,要么只支持有严格限制性的单行风格(single-row flavor具体描述 参见下面的部分)。Nosql数据库通常以牺牲这种ACID属性换得性能的提升(以低延迟和/或高吞吐量来衡量)。
YugaByte DB是一个高性能的分布式数据库,支持任意规模的多行、多个分片和多个节点上的完全分布式ACID事务。YugaByte DB的开放API层支持NoSQL(Cassandra QL&Redis)和SQL(PostgreSQL as Beta)API。这篇文章重点介绍了今天分布式数据库中ACID事务的状态,并解释了YugaByte DB如何使分布式ACID事务在不影响高性能的情况下实现有效工作的。
定义ACID事务
事务有四个关键属性 - Atom原子性,Consistency一致性,Isolation隔离性和Durability耐久性 - 通常缩写为ACID。
原子性是指事务中的所有工作都被视为一个原子单位 - 要么全部是被执行的,要么都不执行。
一致性确保数据库始终处于一致的内部状态。例如,对于存在二级索引的表,主表和所有索引表在更新后应保持一致。
隔离是确定一个事务所做的更改如何/何时对另一个事务可见。从严格的角度来看,Serializable和Snapshot Isolation是最严密的两个隔离级别。
耐久性是确保交易结果永久存储在系统中。即使在断电或系统故障的情况下,修改结果也必须能够保存。
在分布式数据库的情况下,ACID事务可以在内部分为以下3种类型。
1.单行ACID(Single-Row ACID)
所有操作仅影响数据库一个记录行(single row 又称aka key)的事务称为单行ACID事务。由于单行数据通常只限定在分布式数据库中单个节点的边界内,因此在分布式数据库领域中更容易实现单行ACID事务。但是,大多数NoSQL DB都不支持这种事务,因为它们的最终一致性存储引擎对数据读取的正确性没有固有的保证。值得注意的例外是MongoDB,它声称支持单行事务。
2.单片ACID(Single-Shard ACID)
单行ACID只限定在单个服务器节点内,对其改进的方式是单片ACID,其中涉及需要事务操作的所有数据记录行都位于分布式数据库的单个分片中。由于单个分片总是位于单个服务器节点内部,因此这种风格也不涉及跨多个节点协调事务操作,因此更容易在分布式数据库中实现。例如,MongoDB最近宣布他们希望在将来版本中支持单片交易。
3.分布式ACID
像YugaByte DB,Google Cloud Spanner和Azure Cosmos DB这样的自动分片分布式数据库中,通过设计创建集群,数据会分散在集群的多个节点上。这种跨多个节点实现多片和多行数据记录的事务称为分布式ACID事务 。在可以横向扩展的DB中实现分布式ACID事务需要使用事务管理器,该事务管理器可以协调各种操作,然后根据需要提交/回滚事务(2PC 两段事务)。
流行的NoSQL数据库旨在避免这种额外的复杂性,因为他们担心这会在性能上有所牺牲(表现为写延迟增加和线性可伸缩性降低)。正如我们下面所看到的,这种担心其实并非真正基于现实,通过一个分布式ACID事务和高性能的分布式数据库确实可以提高应用程序的开发灵活性。Apple最近开源的FoundationDB遵循类似的设计理念,他们也认为这种担心是多余的,他们的数据库通过使用事务检查器( transactional authority)处理事务。(banq注:设立一组事务检查器,检查当前事务是否会发生冲突,如果是则拒绝执行事务,要求客户端重试。)
4. YugaByte DB中的分布式ACID事务
YugaByte DB拥有先进的设计,支持分布式事务以实现高性能而不影响正确性。它可以有效检测和优化处理涉及单行,单片和分布式ACID事务的不同场景。但为了简单起见,我们将看看分布式事务如何在遍布多个节点的运行情况。
以下步骤概述了YugaByte DB中事务的生命周期。
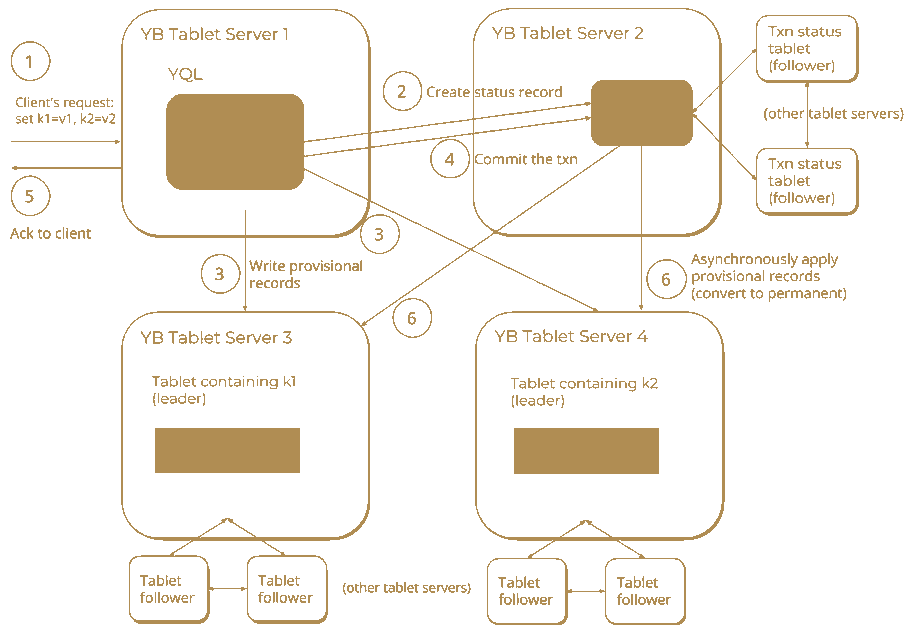
上图展示了YugaByte DB中的分布式ACID事务 - 写入路径
具体步骤如下:
第1步、选择一个事务管理器
YugaByte DB有一个内置的事务管理器来管理事务的生命周期。事务管理器在集群中的每个节点上运行(作为所在服务器进程的一部分。),并随着节点的添加而自动扩展。
由于事务管理器是无状态的,所以传入事务可以路由到管理器的任何节点上。集群中的任何事务管理器都可以管理传入的事务。为了优化事务的性能,YugaByte查询层(YQL) 尝试在那些拥有事务所需大部分数据的服务器上安排进行事务。
第2步、在事务状态表中创建一个条目
事务需要以可靠和容错的方式进行跟踪。这很重要,因为事务可能会尝试更新多条记录,但这个过程会发生任何失败或中止。
为了跟踪事务,在事务状态表中为事务创建一个新状态条目。比如以下信息是该状态条目的一部分。
1.事务ID是唯一标识,事务的UUID。
2.状态,可以是待处理pengding,已提交commited或已中止aborted这三种状态之一。所有事务都以待处理状态开始,并进入提交或中止状态,并会持久存储这些状态直至被清理。
3.提交混合时间戳,它是事务的提交时间戳。这是用于多版本并发控制(MVCC)的最终时间戳,用于在事务提交时处理事务所做的各种更新。
4. 参与事务的服务器的ID列表,这是事务最后写入的那组服务器。在步骤#6中阅读更多关于此的内容,其中描述了如何清理临时写入。
第3步、编写临时provisional记录
从事务的生命周期的这个角度观察,也无法预测任何操作是否会与另一个事务的操作发生冲突。因此,YugaByte DB将临时记录写入所有与事务数据记录有关的服务器。这些记录是临时的,因为在事务提交之前它们对查询是不可见的。(banq注:有点类似event sourcing的事件集合)
除了存储事务中正在发生的更新操作数据之外,临时记录还可以作为持久性的可撤销锁。这些由临时记录代表的锁可以被另一个冲突事务撤销。冲突解决子系统会确保对于任何两个相冲突的事务,至少其中一个事件必须被中止。
此外,还会存储事务元数据记录以便有效地查找指定事务的以下信息:
事务协调员
事务优先级,决定中止哪个冲突交易
所有在此参与事务的服务器上的的临时记录
下面步骤4b中将讨论如何提高事务的提交性能。
步骤4a、处理冲突
当多个事务同时运行时,他们可能会尝试更新同一组数据(用数据key标识)。发生这种情况时,除非检测到并处理冲突,否则这些更新可能会违反正在运行的事务的隔离保证。这组冲突的更新放行与否取决于操作(读取和写入)和隔离级别保证(可串行化与快照隔离)设置。
下表列出了必须检测和解决的冲突的简单视图。解决方案通常是在冲突解决以后的稍后时间,内部重新启动之前的一个冲突事务。
YugaByte DB当前会自动检测并处理快照隔离级别的写入冲突。其他冲突的操作从Serializable隔离级别角度进行自动处理和解决。
步骤4b、提交事务
一旦事务管理器已成功写入所有临时记录,它就通过向事务状态服务器发送一个RPC请求来提交事务。只有在事务尚未因冲突而中止时,事务的提交操作才会成功。提交操作本身的原子性和持久性由事务状态服务器的Raft协议保证。一旦提交操作完成,所有临时记录立即变得对客户端可见。
当将事务提交条目追加到其Raft日志的那个时间作为提交时间戳,然后将其用作正式记录的最终MVCC时间戳,这个正式记录形成后,就要清理临时记录,从而替代临时记录。
第5步、将确认发送回客户端
一旦交易被提交,交易管理者向客户端确认交易成功。
第6步、清理临时记录
交易状态服务器向每个参与事务的服务器发送清除请求。这可以高效完成,因为参与服务器的ID列表已经为事务条目的一部分存储。
清理请求包含具有事务标识和提交时间戳的特殊应用记录 。收到清理请求后,服务器将删除属于该事务的临时记录,并使用正确的提交时间戳写入永久记录。
一旦所有参与事务服务器都成功处理这些了应用记录,它们就可以删除事务状态记录。状态记录的删除是通过在服务器的Raft日志中写入一个特殊的applied everywhere 条目来实现的。在此之后不久,属于此次事务的Raft条目将从所在服务器的Raft日志中清除,并作为旧Raft日志成为常规垃圾回收的一部分了。
现在数据已准备就绪,如事务性读取可见这里。
在分布式事务中实现高性能
在YugaByte DB中使用了许多技术来实现高性能,同时保留分布式ACID事务保证。其中几个概述如下。
1.将正在进行的事务进行缓存
某个特定的正在进行的事务可能希望查找自己的元数据(例如它已更新的服务器)。其他事务也可能希望查找有关冲突事务的信息,并根据相对优先级将其中止。YugaByte DB将缓存正在进行的事务的信息,以便快速高效地进行查找。
2.细粒锁定
YugaByte DB支持细粒度锁定以执行冲突解决。这对于面向文档的数据库(这是YugaByte DB核心)高性能处理分布式事务是至关重要。没有细粒度的锁,更新文档中非重叠属性的事务可能最终会彼此竞争。
下图显示了YugaByte DB已经实现的细粒度锁的类型。
在YugaByte DB中进行细粒度锁定以进行事务处理
例如,如果一个事务修改表中一行内的某列,则可能会采用以下细粒度锁:
一个弱锁将锁住行(文档根目录),以确保它不能同时被另一个事务删除,但允许其他事务继续并行更新列数据。
一个强锁将锁住列,以保证列更新的一致性。
3.安全的时间
YugaByte DB中的每个读取请求都会分配一个特定的混合时间(对于MVCC) - 称为读取混合时间戳。这允许对同一key的数据组的写操作与读取并行发生,从而确保高性能。
然而,至关重要的是,数据库视图的读取混合时间戳不会被同时发生的写操作进行更新。这样做是为了确保在重试读取操作时,在特定时间戳处连续读取数据不会看到不同的结果。为了实现这一点,YugaByte DB使用混合时间领先租约(hybrid time leader leases)的概念。YugaByte DB处理以下操作之间错综复杂的依赖关系,以确保正确性:
针对某个key数据的单行更新
在事务完成前为这个key数据编写的临时记录
从数据库中读取对应key的值
4.自动检测并优化单行ACID与分布式ACID
YugaByte DB专门设计用于在不影响正确性的情况下检测两个模式(banq注:根据CAP定理,下面两个方式是在C和A之间进行选择):
(1)在没有冲突的操作时,单行ACID事务被优化为具有较低的延迟。
(2)如果存在冲突的操作,或者查询尝试进行需要写入临时记录的分布式/多行事务操作,则YugaByte DB会自动切换到保持正确性的模式,即使这意味着更高的延迟。
因此,YugaByte DB允许使用单行ACID语义批处理写入操作,以实现流式处理的非常高的性能,同时它允许事务性地一致性地更新某个key的一组数据。
概要
在开发面向用户的Web /移动应用程序时,事务处理是一个重要功能。通常,这种应用程序中的大部分工作负载需要高性能的单行ACID保证,而一小部分工作负载需要具有极端数据完整性的分布式ACID事务。YugaByte DB旨在在解决这两种情况方面取得良好的平衡。最终目标是通过统一数据平台大幅简化应用程序开发,不仅在API层将NoSQL与SQL结合在一起,而且还在核心数据库层将ACID事务与高性能结合在一起。
如果我们的数据库设计方法听起来令人兴奋,那么试试YugaByte DB--它是Apache 2.0的开源!GitHub项目:http://github.com/YugaByte/yugabyte-db
Yes We Can! Distributed ACID Transactions with Hig
[该贴被banq于2018-05-31 18:08修改过]