分布式系统的逻辑时钟
任何计算系统都可以被描述为一系列执行动作Action的序列,一个动作有关系统中状态改变。例如,读取一个文件到内存中,修改内存中的文件内容,或者将新的内容写入文件中,这些都是一个文本编辑器软件系统的相关操作。
在分布式系统中会在多个地方执行动作Action;这种情况下动作Action通常被称为事件。在分布式系统中事件包括发送或接收消息,或在一个节点中更改某些状态。并非所有的事件都是彼此有关的,但确实有一些事件会前后彼此影响,例如,回复收到邮件的这个事件,也许和因为之前接受邮件的事件有关,也就是说,如果没有接受邮件的事件,就没有回复这个邮件的事件,彼此有因果关系。
在分布式系统中事件能发生在最近的地方,比如同样机器上不同的流程中,或者在数据中心的节点中,或者地理横跨全球,事件之间潜在的因果影响是分布式系统算法设计基础。
为了理解这些因果影响关系,首先研究一种分布式系统自己的内部因果一致性—internal causality. 自然地,一个分布式系统和外界世界实现交互,也必然有一些因果效果. 举例,考虑这样一个情况,一对夫妻计划晚上外出,使用一个软件系统预订晚饭和电影,一个预订了晚餐打电话让另外一个人知道, 接受到电话以后,第二个人到这个系统并预订了电影,一个分布式系统没有办法知道第一次晚餐预订和第二次电影预订存在因果关系。外部因果external causality不能被系统探测,仅仅能使用物理时间估算,本文立足于内部因果关系,这种类型是可以被系统跟踪的。
Happened-before 关系
在1978年, Leslie Lamport定义一种部分次序partial order, 简称为happened before在之前发生, 也就是说,在分布式系统中的事件存在潜在地因果关系,一个事件C是另外一个事件E的因,或者称C发生在e之前(c happened before e),具体情况可能是: 当且仅当两个事件都在同一个节点服务器生,C首先执行,或者两个事件在不同节点上发生,e通过接受消息也知道了c发生。如果事件之间彼此不认识,那么称它们为同时发生。
使用上面晚餐和电影预订案例,下图1显示分布式系统的节点,节点之间箭头代表一个消息的发送和传递,Bob接受了来自Alice的晚餐建议,而Chris稍后请求加入的消息是受到Alice初始计划晚餐的影响。

在这个分布式计算中, 简单检查一个事件c是否是事件e的原因的办法是:至少发现一个连接c到e的路径. 如果这样的连接被找到,这种部分次序关系就会标注为c→ e ,这表示潜在因果的happened-before 关系. 图1中有一个a1 → b2 和 b2 → c3 (由此可得出 a1 → c3, 因为因果是可传递的). 事件a1 和 c2 是并发(标记 a1 ∥ c2), 这是因为在任何方向上都没有因果路径,注意 x ∥ y 意味着当且仅当 if x ↛ y 和 y ↛x. Chris的无聊bored既不受Alice的有关晚餐问题影响,也不受任何其他原因影响。
这样,事件x和y之间有三个可能关系, 如果 x → y; y 也许被x影响, 如果又 y → x; 那么没有办法知道x和y之间的影响关系,将它们看成是并发一起发生:x ∥ y.
因果关系历史
因果律能使用因果历史进行跟踪,系统能本地分配唯一名称给每个事件(节点名称和本地累计计数器) ,一系列能够捕获已知过去的事件切换集合。
对于一个新事件,系统创建一个新的唯一名称,因果历史就是由这些名称组成,以及节点中过去事件的历史,举例, 在节点C中第二个事件被分配名称为c2, 它的因果历史是Hc = {c1, c2}(如下图). 当一个节点发送一个消息,发送事件的因果历史将随消息一起发送,当这个消息被接受时,远程的因果历史就和本地历史融合,举例,从节点A到B的第一个消息融合了远程因果历史 {a1, a2}和本地历史 {b1},新的唯一名称 b2, 将导致因果历史是 {a1, a2, b1, b2}.
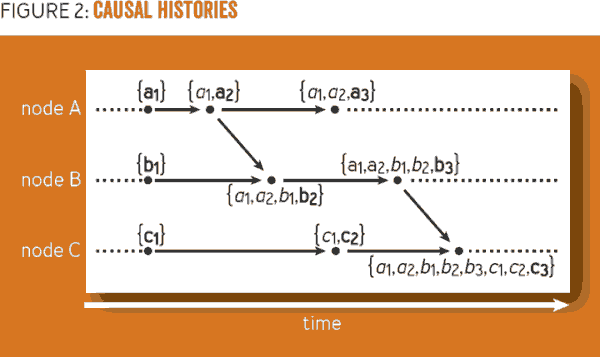
检查事件x和y之间的因果关系只要通过集合是否内含简单实现,:如果 Hx ⊊ Hy.则 x → y , 一个事件的因果历史被包括在其后事件的因果历史中,可以断定这两个事件是因果关系。或者如果 x ∈Hy ,则x → y,比如图中因为a1 ∈ {a1, a2, b1, b2},则a1 → b2,。因为a1属于集合{a1, a2, b1, b2},则a1和b2是因果关系。
Vector Clock向量时钟/矢量时钟
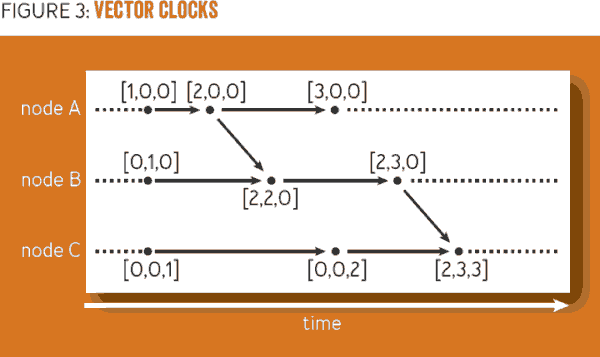
因果历史虽然很简单易懂,但是体量大,不小巧,需要节点存储大部分完整的因果历史。其实只要保存来自每个节点的最近事件即可,比如因果历史完整是 {a1, a2, b1, b2, b3, c1, c2, c3}可被压缩简化为 {a ⟼ 2, b ⟼ 3, c ⟼ 3} 或者简单的向量 [2, 3, 3].
现在使用因果历史的规则已经被切换到新的压缩向量来表达。
为了确认 x → y成立,需要检查是否Hx ⊊ Hy.也就是x的因果历史是否属于y的因果历史,这可以在每个节点验证,如果唯一名称包含Hx,也包含在Hy,至少在Hy中有一个没有包含在Hx中,这样就立即可翻译成检查x向量每个项目是否小于或等于y向量相应项目, 如果 Vx < Vy,则x →y .
对于一个新唯一名称的创建新事件等同于累计事件被创建节点服务器中的向量项目,比如在节点C中第二个事件就有向量 [0, 0, 2], 代表因果历史事件c2的创建。
最后,创建两个因果历史Hx 和 Hy 的联合等同于只取Vx 和 Vy中最大值,逻辑告诉我们,对于每个节点产生的唯一名称,只需要保留计数器最大值即可。
当一个消息被接受,为了融合因果历史,一个新事件被创建,这些步骤的向量表示能被看到,比如当来自a的第一个消息被b接受,那么后者会取得最大值[2, 1, 0],新的唯一名称将导致[2, 2, 0]:
除了基本的向量时钟,还有更多演化版本,如Dotted向量时钟 、版本向量、Dotted版本向量等
总之,在分布式系统中,跟踪因果关系不能被忽视,这是设计分布式算法很重要的一点,不遵循因果将导致用户发现不可思议情况发生。经常跟踪因果的方式是向量时钟和版本向量。可以简单优化因果历史,能够易于理解。