深度学习教程之Autoencoder
大多数介绍机器学习课程倾向于在前馈神经网络停止了。 其实可拓展的空间还很多。
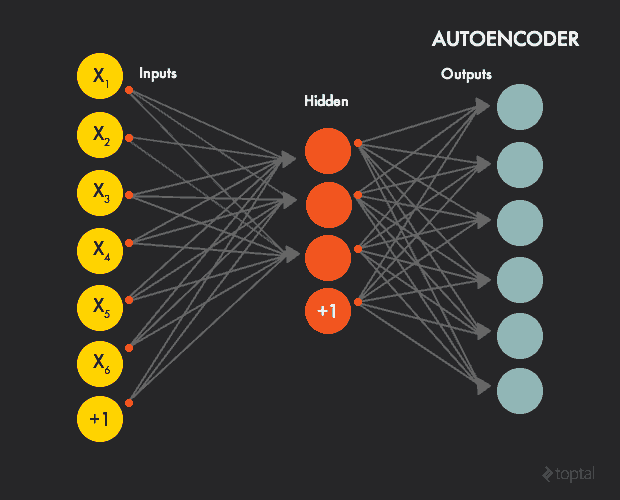
一个autoencoder通常是一个前馈神经网络,目的是学习一个压缩、分布式的数据集表示(编码)。
从概念上讲,网络被训练为输入的"再现",输入和目标数据是相同的,换句话说:对于同样的你输入你要输出同样的事情,但是在某种程度上进行压缩,这是非常令人困惑的,让我们看看一个例子。
压缩输入:灰度图像
训练数据由28 x28灰度图像组成,每个像素的值被摄入一个输入层神经元(,输入层有784个神经元)),输出层如同输入层具有相同数量的单位(784),每个输出单元的目标值是图像的一个像素的灰度值。
此架构背后的直觉是网络不会学习训练数据及其标签之间的"映射",但是取而代之会学习数据自己的内部架构和特征(因此,隐藏层也成为特征检测器),通常,隐藏单元的数量小于输入/输出层,强迫网络只学习最重要的特性和实现降维。
我们要在中型规模中一些小节点在概念层学习数据,产生压缩的表示。
这种产生的压缩紧凑表示,能够在某种程度上抓住了输入的核心特征。
流感案例
为了进一步证明autoencoders,让我们看看一个应用程序。本例中,我们将使用一个简单的数据集组成流感症状(来自这个 blog post 的idea),如果你感兴趣,代码可以在in the testAEBackpropagation method中发现。
下面是数据集分解:
- 有六个二进制输入特征。
- 前三个是疾病的症状。 例如, 1 0 0 0 0 0 表明该病人的高温,而 0 1 0 0 0 0 表明咳嗽, 1 1 0 0 0 0 表明咳嗽 和 高温等。
- 最后三个特性是"计数器"症状;当病人只有其中的一个症状,不太可能证明他或她生病了。 例如, 0 0 0 1 0 0 表明该病人已经有流感疫苗。 两个特征可以组合的有: 0 1 0 1 0 0 表明疫苗病人有咳嗽症状,等等。
我们将考虑他或她生病时是否是病人,如至少有前三个特征的两个称为病人,如果有后三个中两个是健康的。
- 111000, 101000, 110000, 011000, 011100 = sick
- 000111, 001110, 000101, 000011, 000110 = healthy
我们将六个输入和六个输出单元培养一个autoencoder(使用反向传播),但是 只有两个隐藏单元。
经过几百个迭代后,我们观察到当每个"生病"样本提交给机器学习网络时,两个隐藏的单元(每个"生病"的同一单位样本)中一个总是展示高于其他的激活值,相反,当一个"健康"样本展示时,其他隐藏的单元有更高的激活。
回到机器学习
从本质上讲,我们两个隐藏单元已经学会了 数据集的流感症状的紧凑表示,为了看看这深度学习的关系,我们回到过度拟合的问题,通过培训网络学习数据的紧凑表示,我们将能支持一个简单的表示而不是基于训练数据的高度复杂的假设。
在某种程度上,通过使用这些简单的表示,我们试图在一个更真实的感觉上了解数据。
下一页:深度学习教程之受限波尔兹曼机