深度学习教程之受限玻耳兹曼机
下一个逻辑步骤是看 限制玻耳兹曼机Restricted Boltzmann machines (RBM) :一个可生成的随机神经网络,它能学习对其一组输入的概率分布 。
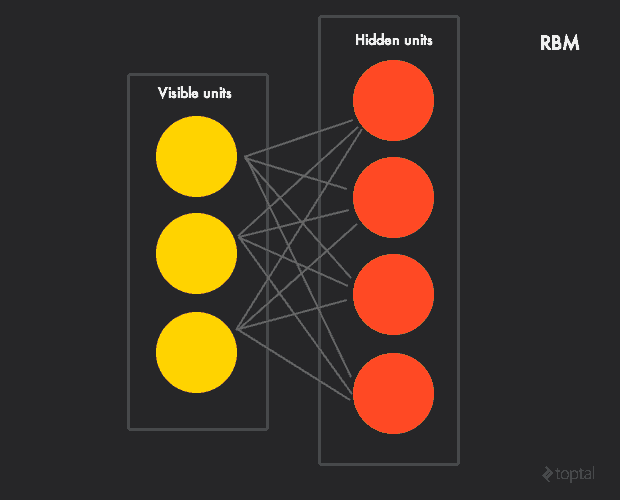
RBM是由一个隐藏的,可见,偏见层组成,不像前馈网络,可见和隐藏层之间的连接是无向的(值可以在visible-to-hidden和hidden-to-visible两个方向之间传播),并且是完全连接的(从给定层的每个单元连接到下一个层的每个单元,前提是如果我们允许任何层的任何单元能够连接到任何层,那么我们就有一个波尔兹曼机Boltzmann,但是不是受限的波尔兹曼机Boltzmann机器。
标准的BPM有一个二进制隐藏和可见单元,也就是,单元的激活值在伯努利分布 下是0或1,但没有与其他non-linearities的变种。
虽然研究人员已经知道BPM有一段时间了,最近推出的 对比差异(对比分歧) contrastive divergence 无人监督的训练算法重新燃起人们的兴趣。
对比差异Contrastive Divergence
contrastive divergence 又称对比散度、对比分歧,简称CD,单步执行对比差异算法(cd 1)是这样运作的:
- 正相 :
- 一个输入样本 V 被夹放到输入层。
- V 以前馈网络类似的方式传播到隐层。 隐藏层激活的结果 h 。
- 负相 :
- 传播 h 回到可见层,并带有结果 v" (可见和隐藏层之间的连接是无向,从而允许在两个方向运动)。
- 传播的新 v" 回到隐层,同时带有激活的结果 H" 。
- 权重更新 :
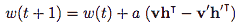
a是 一个 学习速率,V , v" , h , h" , W 是矢量。
算法背后的直觉是:正相(h由v定义)反映的是网络内部真是世界数据的表示,同时负相代表视图重新创建基于内部表示(h定义v' )的数据。主要目标是生成的数据 要尽可能接近 现实世界, 这是反映在权重更新公式。
换句话说,网络对已经感知到一些输入数据是如何表示的,因此基于这种看法再次试图复制数据。 如果其繁殖不足以接近现实,它会调整并再次尝试。
回到流感案例
为了演示对比差异,我们将使用相同的症状数据集,测试网络是一个有六个可见和两个隐藏单元的RBM,我们将培训网络使用对比差异,将症状v 夹送到可见层,在测试过程中,症状又再次在可见层存在,然后,数据被传播到隐藏层,隐藏单元代表病人/健康状态,非常类似autoencoder的架构(从可见层传播数据到隐藏层)
经过几百个迭代后,我们可以观察到与autoencoder相同的结果:一个隐藏的单元当任何"生病"样本出现时有更高的激活值,另一个在"健康"的样本出现时总是更积极。
案例源码可见:in the testContrastiveDivergencemethod.
下一页:深度学习教程之深层网络