卷积神经网络CNN入门理解
卷积神经网络如今已经得到广泛应用,其最流行的用法是用于图像处理。本文我们来看看如何使用这些卷积神经网络进行图像分类。
图形分类是对输入图片进行分类识别,对于人来说,这是我们出生后的首要技能,不用再次思考,我们会一眼辨识周围环境中事物,这是一种从先验知识中快速识别模式的能力。
当计算机看到一幅图片时,它只是看到像素数组,依赖于图片大小和分辨率,比如看到32x32x3数字数组,这里的3代表RGB颜色表值。每个数字都是从0-255之间取一个值描述某个点。计算机看到这些数字数组输入后,它能给出这个图片属于哪个类别的可能性,比如80%是猫,15%是狗,5%是鸟。
我们人类看到一幅图片时, 会根据图中特征识别,比如爪子或四只腿,而计算机也是从这种低级别特征比如边和角开始,通过一系列卷积层建立起一个抽象概念,这就是CNN所做的。
CNN是参考视觉皮层的生物启发的,视觉皮层有一个小区域的细胞,对于特定视野区域比较敏感,这个想法被胡贝尔和魏塞尔在1962年扩展:大脑中的一些个别神经元细胞只对一定方向的边缘敏感有反应。比如一些神经元对垂直角度有反应,而一些神经元对水平或斜边有反应,他们发现所有这些神经元都是以状形结构放在一起,他们能够产生视觉感知。
在视觉皮层的神经元细胞寻找特定的特性,进一步抽象这个概念为:系统中特殊组件都有其特殊指定任务,这也是CNN的原理。
一个CNN是将图片输入,通过一系列卷积层传递,非线性,pooling池和充分连接层,最后得到输出,也就是说,输出能够是一个单个类别或图片最可能的类别,最难的是理解这每个层做什么。
第一层 数学部分
CNN中第一层总是一个卷积层,首先我们输入的是一个32x32x3的像素数组,解释一个卷积层最好的办法是想象一个手电筒照在图像的左上角。我们假设这个手电筒的光照覆盖了一个5×5区域。现在,让我们想象这个手电筒在输入图像的所有区域滑动。用机器学习中的术语,这个手电筒称为filter过滤器,有时也作为神经元或核,光照过的区域称为感受区域,现在这个过滤器也有一个数字数组,这个数字称为权重或参数,一个重要点是,这个过滤器深度是和输入的深度一样的,所以,过滤器的维度是5x5x3,现在,我们获得了案例中首个过滤器位置,它是左上角,当这个过滤器在输入图像上滑动,或者称为convolving卷动时,是用图像的原始原始像素值乘以过滤器中的值,这些乘法最后加起来,这里是75结果,这样我们有一个单个数值了,记住,这个数字只是代表过滤器在图像左上角位置值,下一步我们会一个单元一个单元移动过滤器,每个唯一位置都会产生一个数字,在过滤器滑动完所有位置后,你会发现你得到是一个28x28x1的数字数组,称为activation map 或 feature map.
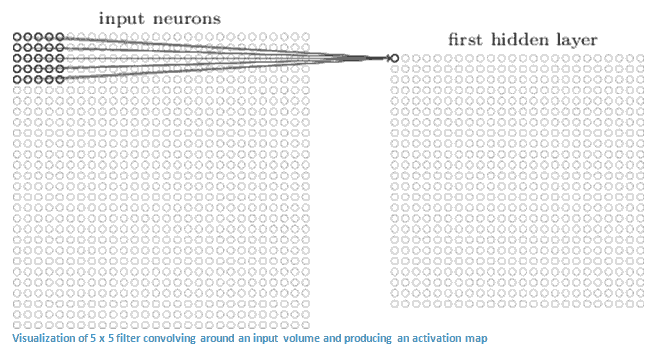
之所以得到28x28x1是因为:对于32x32图像以5x5过滤器一个个移动,有784个不同位置,这784个同位置对应28x28数组。
现在如果我们使用两个5x5x3过滤器,那么输出将是28x28x2,用更多过滤器,我们能保有更好的空间维度,从数学上看,这是卷积层。
第一层:高级视角
让我们从高级别看看卷积是什么,这些每个过滤器被看成是特征标识器,这些特征包含直角 简单颜色和曲线,最简单特征是指所有图像都彼此有共同特点。
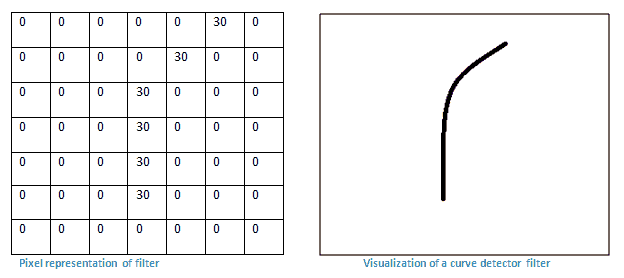
假设我们第一个过滤器是7x7x3,这是一个曲线探测器,沿着曲线在像素数字上会有更高的数值:
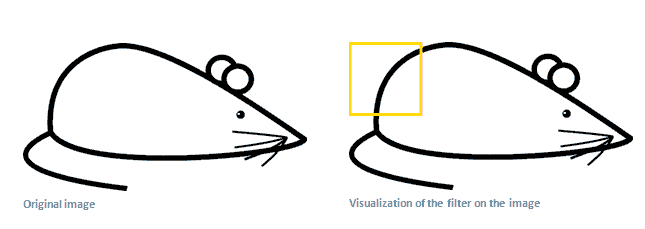
让我们回到数学可视化。当我们的过滤器在输入图像的左上角时,它会获得该区域也就是感受区域receptive field的曲线:
我们需要做的是将过滤器中值和图像原始值相乘:

当我们移动过滤器时,碰到曲线会得到如上6600很大的值,如果我们移动到其他区域,如下图:
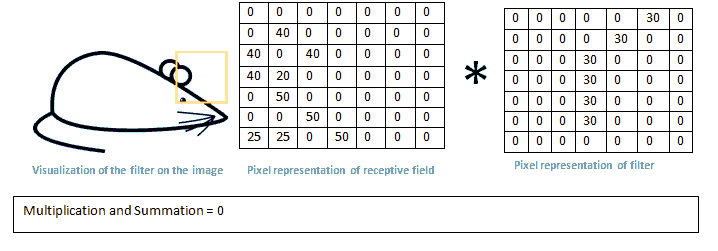
这个值非常小,这是因为在过滤器所在的图像部分没有曲线。记住,这个卷积层输出是一个activation map。因此,在简单的情况下,一个过滤器的卷积activation map大部分代表图像中曲线,左上角28x28x1的activation map是6600,这个高值意味着该区域存在曲线引起了过滤器有反应,右上角值activation map却是0。因为该区域没有任何激活过滤器的因素。
目前只是一个过滤器,我们可以有更多侦测线条比如直边的,向左弯曲的曲线等等,更多过滤器意味着activation map的深度,会得到更多输入图像的信息。
更多其他层详细讲解见:
A Beginner's Guide To Understanding Convolutional Neural Networks