多线程并发编程中的初始化问题
本文主要是讨论一下在多线程编程环境中特别需要注意的初始化问题,以及一些常见的代码写法可能在多线程环境下造成数据错乱的现象,特别介绍了如何模拟真正多线程并发竞争环境对这些代码进行测试,因为通常线程执行比较快,使用通常的多线程代码有可能只在一个CPU核上执行,而不能真正利用CPU多核潜力,通过引入Fork/Join这样并发计算库包,能够迅速模拟真正多核并发竞争环境,它如同一面照妖镜,能够一下子就能发现我们代码的运行漏洞。
我们通常编程思路是按照单线程顺序执行来假设我们代码的运行方式,而实际运行可能是在多线程环境,除非使用JTA事务机制或同步锁强行将代码运行变成类似单线程方式,这种为获得数据正确性以及一致性的做法其实是不灵活的,没有良好的拓展性,我们可以做得更好,不牺牲数据正确性前提下充分利用硬件性能。
比如经常要对Map/List集合进行初始化,如果Map第一次访问时,如果其中不存在键/值,我们就会键/值put放入其中,比如下面代码:
public Object getObject(int key) {
Object value = map.get(key);
if (value == null) {
value = ….; //初始化value
map.put(key, value);
}
return value;
}
}
这种代码在日常编程中经常会出现,我们可能理所当然认为这没有问题,其实这段代码如果在多线程并发环境下是会有错误的。口说无凭,我们通过引入Fork/Join模拟多线程并发环境来发现其运行问题。
Fork/Join是从JDK 7以后提供的新型并发库包,它基于divide-and-conquer算法,适合将一个大任务划分为多个小任务,让多个CPU执行,然后再合并结果。fork/join类似MapReduce算法,两者区别是:Fork/Join 只有在必要时如任务非常大的情况下才分割成一个个小任务,而 MapReduce总是在开始执行第一步进行分割。看来,Fork/Join更适合一个JVM内线程级别,而MapReduce适合分布式系统。
总之,Fork/Join能够充分发挥CPU的多核威力,立即发挥多线程同开的威力。下面我们来使用Fork/Join准备多线程并发测试环境。
测试案例:我们假设有一个集合,集合中都是随即的26个字母,我们试图统计这个集合中字母A的个数。
private static List<String> letters = new ArrayList<String>(ARRAY_SIZE);
static {
final char key = 'A';
// fill the big array with A-Z randomly
for (int i = 0; i < ARRAY_SIZE; i++) {
char t = (char) (Math.random() * 26 + 65);
letters.add(String.valueOf(t)); // A-Z
Random r = new Random();
// System.out.println(Math.random()*letters.size()+"="+String.valueOf(t));
}
System.out.println("初始化p" + letters.size());
}
这是初始化letters集合,然后我们使用Fork/Join分别启动多个线程在这个集合中查找。首先我们需要对这个集合进行切分分片,比如这个集合有800个元素,我们切成八个100集合分别交给几个线程去查找。切分逻辑代码大致如下:
public class BusinessCompTaskSharding extends RecursiveTask<BatchComputeResult> {
….
private final char key;//需要寻找的字母
private final List<String> letters; //随机字母集合
private final SharedParameter sharedParameter;//被测试的方法
public List<BusinessCompTask> sharding(BusinessCompTask task) {
List<BusinessCompTask> tasks = new ArrayList<BusinessCompTask>();
if (task.getLetters().size() <= minUnitCount) {
//如果集合切分到最小数目,运行业务方法,运行被测试方法,
//这里委托给BusinessCompTask执行。
BusinessCompTask one = new BusinessCompTask(key, task.getLetters(), sharedParameter);
tasks.add(one);
} else {//如果集合没有切分到最小数目,进行一分为二反复切分
int mid = task.getLetters().size() / 2;
BusinessCompTask left = new BusinessCompTask(key, task.getLetters().subList(
0, mid),sharedParameter);
BusinessCompTask right = new BusinessCompTask(key, task.getLetters().subList(
mid, task.getLetters().size()), sharedParameter);
tasks.addAll(sharding(left));//再次嵌套调用本方法切分,直至切分到最小数目
tasks.addAll(sharding(right));//左右两个分支再次切分。
}
return tasks;
}
….
}
当其中集合最小数值minUnitCount为100,当包含800个元素的集合切分到元素个数小于等于100时,就直接执行我们的真正业务逻辑,这里是委托给BusinessCompTask执行,核心代码如下:
protected BatchComputeResult compute() {
int count = 0;
List<String> lettersresult = new ArrayList<String>();
for (String s : letters) {
count++;
if (String.valueOf(key).equals(s)) {
//调用被测试方法
//调试时,可以在这里打断点,能够发现四个线程同时暂停在这里
//说明四线程同时开启了。 ((AtomicInteger)sharedParameter.getCount(key)).incrementAndGet();
lettersresult.add(s);
}
}
BatchComputeResult batchComputeResult = new BatchComputeResult(
lettersresult, count);
return batchComputeResult;
}
}
其中被测试代码:
if (String.valueOf(key).equals(s)) {
((AtomicInteger)sharedParameter.getCount(key)).incrementAndGet();
lettersresult.add(s);
}
就是发现A字符时,调用sharedParameter.getCount方法,这个方法内容就是前面我们需要测试的集合初始化方法,具体内容:
public AtomicInteger getCount(char modelKey) {
Object model = map.get(modelKey);
if (model == null) {
model = new AtomicInteger(0);
map.put(modelKey, (AtomicInteger) model);
}
return (AtomicInteger) model;
}
至此,我们的多线程并发测试环境已经准备好了,为了亲眼确证这事情,可以在上面被测试代码处打上断点调试,调试运行时会在这个断点处暂停,暂停截图如下:
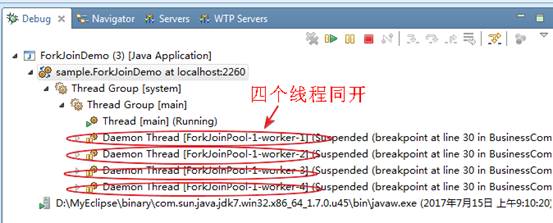
点击其中一个暂停线程如下图:
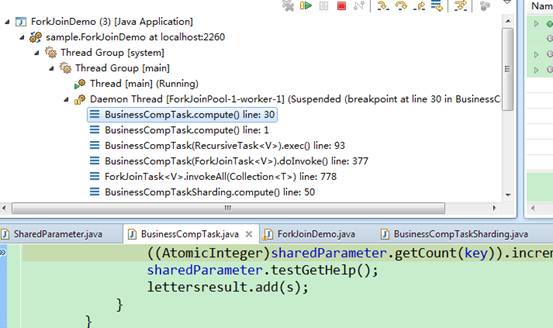
确实四个线程都是运行getCount这个方法时暂停,这说明同时有四个线程调用getCount这个方法,也就是我们被测试的初始化方法getCount能在并发四线程下同时运行,下面看看运行结果哦。
多次运行这个并发测试案例,随机两次结果:
16 Using ForkJoin, found 800 27
map size=27
第一行是正常输出,使用Fork/Join在800个集合中发现字母为A的有27个,第二行map size=27就是我们被测试的初始化方法的运行结果,也是27个,这与第一行的27是吻合的。
15 Using ForkJoin, found 800 26
map size=25
这是第二次以后再运行的结果,这时我们被测试的初始化方法只统计出25个,比26少一个了,数据不正确了。
如果多次运行这个测试案例,会发现不正确的比率还是比较高的,这说明我们的代码在多线程并发环境下确实有问题,
有人可能说,这大概使用的是HashMap,不支持并发环境,其实在这个测试案例中,我们使用的正是Map的并发集合包ConcurrentMap。下面我们做些改进,使用ConcurrentMap提供的原子化初始方法putIfAbsent替代原来的put方法:
public AtomicInteger getCount0(char modelKey) {
Object model = map.get(modelKey);
if (model == null) {
model = new AtomicInteger(0);
map.putIfAbsent(modelKey, (AtomicInteger) model);
}
return (AtomicInteger) model;
}
结果运行三次结果:
8 Using ForkJoin, found 800 25
map size=25
13 Using ForkJoin, found 800 35
map size=34
12 Using ForkJoin, found 800 18
map size=18
第一行代码正常测试结果:Using ForkJoin使用ForkJoin在800个中发现18个字符为A。第二行map size=18 表示我们要测试的map初始化方法的结果。你会发现,中间结果是在800个发现35个,但是map方法统计却是34个,还是少了一个。
那么正确的多线程集合初始化方法怎么写?难道要在这个方法上加上同步锁吗?这是最差的做法,最佳做法是不用锁,但是能够获得正确的运行结果:
public AtomicInteger getCount2(char key) {
AtomicInteger existo = (AtomicInteger) map.get(key);
AtomicInteger newo = null;
if (existo == null) {
newo = new AtomicInteger(0);
existo = (AtomicInteger) map.putIfAbsent(key, newo);
}
return existo != null ? existo : newo;
}
这里有一句特别的:
existo = (AtomicInteger) map.putIfAbsent(key, newo);
map.putIfAbsent的意思其实等同于下面复杂语句:
if (!map.containsKey(key))
return map.put(key, value);
else
return map.get(key);
也就是map中如果没有key/newo这对键值就放入,如果有了,就不放入,直接返回已经有了那个值,这段逻辑在多线程同时访问这段方法时,能够防止多个线程各自把自己的key/newo放入集合。然后通过语句:
return existo != null ? existo : newo;
进行判断返回,如果existo != null就返回existo,表示map中已经有,返回旧值,否则返回新值。
这段代码经过Fork/Join代码多次测试后,没有出现查询结果不同问题,证明是符合多线程初始化方式的,而且不需要同步锁。
本文主要讨论了常见的集合Map懒初始化赋值在多线程中的问题,并介绍使用Fork/Join能够重现其在多线程的这个问题。也清楚知道,Fork/Join可以为我们多线程并发并行编程提供强大的测试工具,从而能让我们的代码能真正健壮地在多线程
环境下驰骋,也不再担心似似而非的各种陷阱了。
最后提出一个思考问题,著名双重检查锁定Double-checked_locking问题是不是也能得到优雅地解决呢?
private Helper helper;
public Helper getHelper() {
if (helper == null) {
synchronized(this) {
if (helper == null) {
helper = new Helper();
}
}
}
return helper;
}
本文涉及的完整代码见: https://github.com/banq/articles/tree/master/LazyInit