数据库缓存的几种方式
引入缓存可以提高性能,但是数据会存在两份,一份在数据库中,一份在缓存中,如果更新其中任何一份会引起数据的不一致,数据的完整性被破坏了,因此,同步数据库和缓存的这两份数据就非常重要。本文介绍常见的缓存更新的同步策略。
预留缓存Cache-aside
应用代码能够手工管理数据库和缓存中数据,应用逻辑会在访问数据库之前检查缓存,在数据库更新以后再更新缓存:
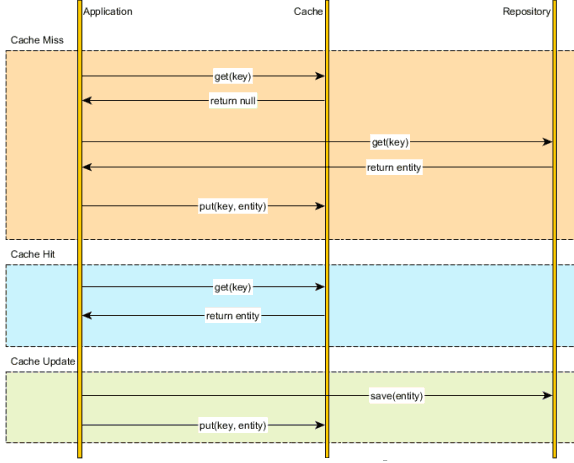
上图中Cache update缓存更新时,通过手工编码分别对数据库save(entity)和缓存(put(key,entity))做更新,将这种琐碎的缓存管理和更新夹杂在应用逻辑中并不是一种好方式,可以采取AOP面向方面拦截器等方式实现缓存操作,减轻缓存操作泄漏到应用代码中,同时确保数据库和缓存都能正确同步。
Read-through
相比上面同时管理数据库和缓存,我们可以简单委托数据库同步给一个缓存提供者,所有数据交互通过这个缓存抽象层完成。

图中CacheStore是我们的缓存抽象层,当我们应用通过其抓取一个缓存数据时,这个缓存提供者确认缓存中是否有该数据,如果没有,从数据库加载,然后放入缓存,下次以后再访问就可以直接从缓存中获得。
Write-through
类似于Read-through的数据抓取策略,缓存能够在其中数据变化时自动更新底层数据库。
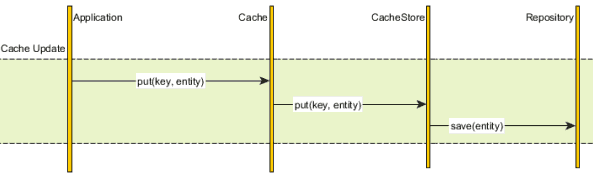
尽管数据库和缓存同步更新了,但是我们也可以按照我们自己的业务要求选择事务的边界:
- 如果需要强一致性,,并且缓存提供者提供了XAResource ,这样我们可以在一个全局事务中完成缓存和数据库的更新,这样数据库和缓存更新是在一个原子单元:single atomic unit-of-work
- 如果只需要弱一致性,我们可以先后更新缓存和数据库,不必使用全局事务,这会让我们提升快速响应性与性能,通常缓存首先被更新,如果数据库更新失败,缓存可以通过补偿动作实现回滚当前事务所做的改变。
Write-behind
如果强一致性不是必须的,我们可以简单将缓存的更新放在队列中,然后定期批量地去更新数据库。
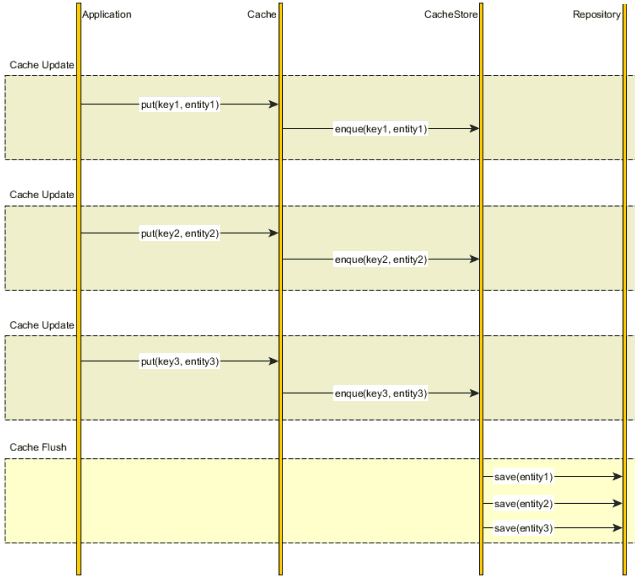
这种策略虽然打破了事务保证,但是性能要远远超过write-through,因为数据库能够快速批量更新,事务机制不再需要。