选择NoSQL的几种理由
来自NoSQL Ecosystem选择NoSQL的几种种理由:
1.Scalability
有两种理由寻求一种分布式数据库:
1)支持多个数据中心
2)可以透明在线为你的应用增加新服务器。
下面是NoSQL数据库支持这两点列表: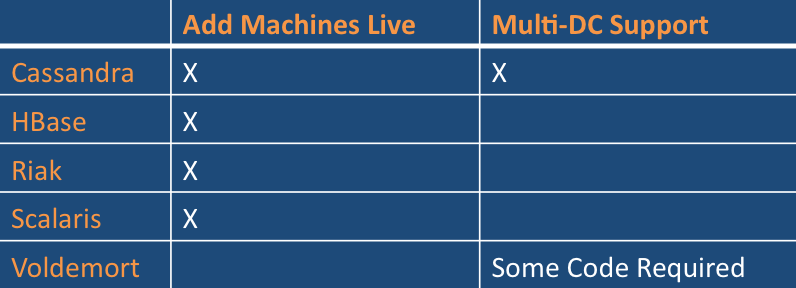
非分布式的NoSQL数据库包括有 CouchDB, MongoDB, Neo4j, Redis, and Tokyo Cabinet. 当然他们可以为分布式的持久层架构服务,MongoDB 提供有限的划分碎片sharding支持, 正如 CouchDB分离的Lounge项目一样, Tokyo Cabinet能用于作为Voldemort存储引擎.
2.Data and Query Model
NoSQL 支持各种数据类型数据模型,图片 视频 等等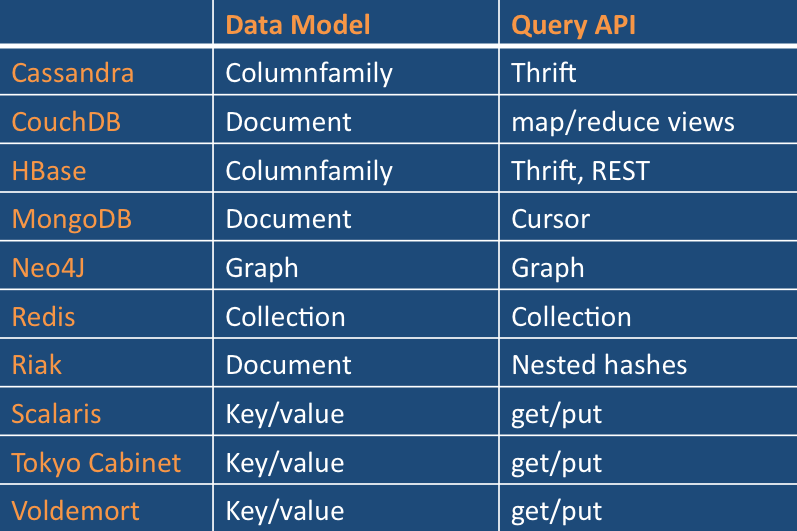
当你需要查询或更新一个值的一部分时,Key/value模型是最简单有效实现。
面向文本数据库是Key/value的下一步, 允许内嵌和Key关联的值. 支持查询这些值数据,这比简单的每次返回整个blob类型数据要有效得多。
Neo4J是唯一的存储对象和关系作为数学图论中的节点和边. 对于这些类型数据的查询,他们能够比其他竞争者快1000s
Scalaris是唯一提供跨越多个key的分布式事务。
3.Persistence Design(内部数据是如何保存的?)

内存数据库是非常快的,(Redis在单个机器上可以完成每秒100,000以上操作)但是数据集超过内存RAM大小就不行. 而且 Durability (服务器当机恢复数据)也是一个问题
Memtables和SSTables缓冲 buffer是在内存中写(“memtable”), 写之前先追加一个用于durability的日志中.
但有足够多写入以后,这个memtable将被排序然后一次性作为“sstable.”写入磁盘中,这就提供了近似内存性能,因为没有磁盘的查询seeks开销, 同时又避免了纯内存操作的durability问题.(个人点评 其实Java中的Terracotta早就实现这两者结合)
B-Trees提供健壮的索引,但是性能很差,一般和其他缓存结合起来。