领域模型实例分析之-论坛
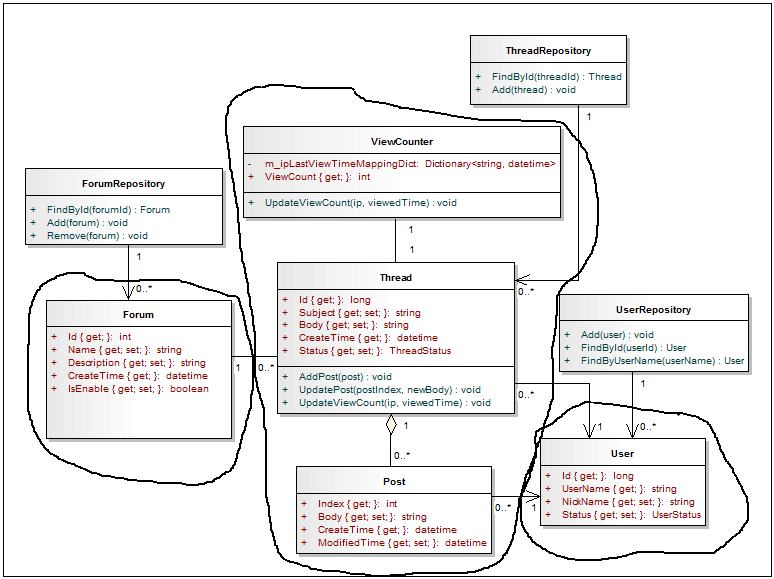
说明:
1)上面的领域模型在设计时借鉴了DDD和CQRS的思想;
2)利用DDD的思想来设计实体、值对象、聚合、聚合根;图中有三个聚合根,分别是Forum、Thread、User;其中Thread聚合根聚合了Post和ViewCounter两个对象;Post是Thread的回复,显然Post离开Thread没有意义,但是Post在Thread聚合内有一个本地标识,即只要在当前Thread下唯一即可,不需要全局唯一。
3)由于CQRS思想的引入,可以确保我们在设计领域模型时不必考虑由于对象关联而产生的统计信息该如何存放,从而让领域模型更精简明了;如帖子的总回复数、最新回复时间、最新回复人,等等,这些信息只是统计信息,只用于在界面上显示,即我们只有在查询时才需要这些信息,因此可以在CQRS的Q端实现。
4)由于CQRS思想的引入,也可以让仓储更精简,不需要提供用于查询领域对象并在界面上显示结果的接口,而只需要提供用于查询单个聚合根或Add以及Remove的操作;
5)上面的领域模型只关注一个标准论坛的基本功能;
希望大家能多给些意见。之前学了很多的理论知识,现在是该通过一些建模例子锻炼一下的时候了。
[该贴被tangxuehua于2011-10-27 00:53修改过]