使用Disruptor实现并发编程 PPT文档
2012年Qcon伦敦大会3月7日到9日在伦敦召开,所谓实践出真知,Qcon英文大会可谓是世界上战斗在实践探索第一线的顶尖高手分享大会,也是一次软件创新大会。
这次大会除了云计算架构之外,有三个具体领域:移动 Scala和Java平台,而在Java平台中,比较令人关心的是LMAX所做的Disruptor报告,DDD推动者gregyoung在其Twitter微博上说,很想去听LMAX报告,可惜挤不进去了,由此可见LMAX架构的热度。
LMAX的报告主题是:
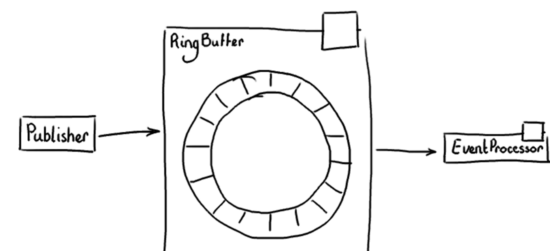
Concurrent Programming Using The Disruptor使用Disruptor实现并发编程,主要讲述了如何使用Disruptor 2.8如何进行并发编程,Disruptor核心是其神奇的RingBuffer,见下面附图:
使用Disruptor有几个步骤,以一个生产者,一个消费者为例子:
1. 首先需要一个创建事件的工厂,实际是一种事件生产者:
|
其中SimpleEvent是你自己的POJO事件对象。
2.创建事件处理器,消费者获得事件后,需要激活事件处理器EventHandle:
|
3.然后将事件,事件处理器和RingBuffer装载在一起:
|
以上装载wire到一起后,只要调用ringBuffer.publish()就在当前线程开启发送事件,SimpleEventHandler.onEvent在另外一个线程被激活运行。
这之间原理如图JDK的队列等概念,好像是线程通讯的基础用法,但是RingBuffer相比JDK提供的那些有锁Queue或LinkedList,其特点是无锁,可见本站以前关于Disruptor的帖子。
该PPT中还列举了一个生产者,多个消费者的使用方式。
[该贴被banq于2012-03-10 17:43修改过]