为什么计算科学中最难的两件事是命名和缓存失效
DDD的命名笼统好像是小事,但是反映了对事物的分析程度,有句老话:
"There are only two hard things in Computer Science: cache invalidation and naming things" - Phil Karlton
计算科学中最难的两件事是命名和缓存失效。
在DDD实践中,这两个问题都会同时碰到,命名反映了领域模型的提炼过程,聚合边界的划分,说白了反映程序员的分析能力:
事物分析方法之道:找出内聚性强的结构,以包含这个结构为边界进行切分。
找到聚合体名称后,实体和值对象等类的名称都能确定了。但是这个过程在对复杂业务情况下比较难。
关于缓存失效,其实也就涉及到实体的状态变化,现在计算机业界采取有态和无态划分方式,EJB也是这种划分,函数编程FP也是这种划分,专门针对无态。但是有态的变化是无法回避的,也是很难的。
见下图,当我们命名好我们的领域模型后,进入计算机代码实施时,这时我们的领域模型对象是生存在计算机的In-memory cache,而领域模型的对象状态是经常被事件改变的,那么不可避免遭遇状态在缓存中失效,也就是更新的问题: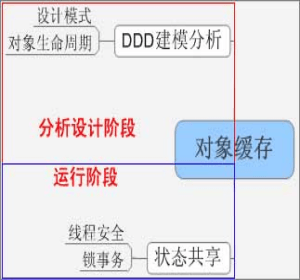
下图演示用户的事件是如何改变领域模型状态的:
缓存失效还涉及到数据一致性等等问题,也可以说,很难用算法来精确进行缓存失效。
一个复杂系统只有将这两个问题解决了,系统基本意味成熟稳定了,也就表示良好的维护性和拓展性,否则越修改越乱,BUG越多。
有句笑话:程序猿成天象抓蚊子一样抓臭虫BUG,反映两个问题:
首先教育阶段只了解CPU是咋样脾气,不了解人如何与CPU计算机交互,或者说如何训练计算机作为自己的宠物狗;第二是因为不了解人分析事物方法,也就不知道有这个“道”存在,只能象无头苍蝇到处乱撞,拼命加班,浪费青春年华。
[该贴被banq于2013-01-12 10:05修改过]