为什么Actor模型是高并发事务的终极解决方案?
首先看看道友提出的一个问题:
用户甲的操作
1.开始事务
2.访问表A
3.访问表B
4.提交事务
乙用户在操作
1.开始事务
2.访问表B
3.访问表A
4.提交事务
如果甲用户和乙用户的两个事务同时发生,甲事务锁住了表A未释放(因为整个事务未完成),正在准备访问B表,而乙事务锁住了表B未释放(因为整个事务未完成),正在准备访问A表,可是A表被甲事务锁住了,等甲事务释放,而甲事务真正等待乙事务释放B表,陷入了无限等待,也就是死锁Dead Lock。
也有道友使用多线程来模拟存储过程:http://www.jdon.com/45727,每个线程里开启一个事务,类似上述问题也会出现死锁。
问题出在哪里?
是我们的思路方向出现问题:
其实无论是使用数据库锁 还是多线程,这里有一个共同思路,就是将数据喂给线程,就如同计算机是一套加工流水线,数据作为原材料投入这个流水线的开始,流水线出来后就是成品,这套模式的前提是数据是被动的,自身不复杂,没有自身业务逻辑要求。适合大数据处理或互联网网站应用等等。
但是如果数据自身要求有严格的一致性,也就是事务机制,数据就不能被动被加工,要让数据自己有行为能力保护实现自己的一致性,就像孩子小的时候可以任由爸妈怎么照顾关心都可以,但是如果孩子长大有自己的思想和要求,他就可能不喜欢被爸妈照顾,他要求自己通过行动实现自己的要求。
数据也是如此。
只有我们改变思路,让数据自己有行为维护自己的一致性,才能真正安全实现真正的事务。
数据+行为=对象,有人问了,对象不是也要被线程调用吗?
例如下述代码,因为对象的行为要被线程调用,我们要使用同步锁synchronized :
|
上面这段代码业务逻辑是想实现lower<upper:
1. lower和upper的初始值是(0, 5),
2.一个客户端请求线程A: setLower(4)
一个客户端请求线程B: setUpper(3)
3. lower和upper是 (4, 3)
这个结果破坏了lower<upper这个逻辑一致性,所以,用锁并不能保证逻辑一致性,而且还带来了堵塞。锁用错了地方,不但没有得到想要的,而且还失去更多。
下图展示了锁带来堵塞,每个时刻只能允许一个线程工作,如同只能允许一个人蹲马桶一样。
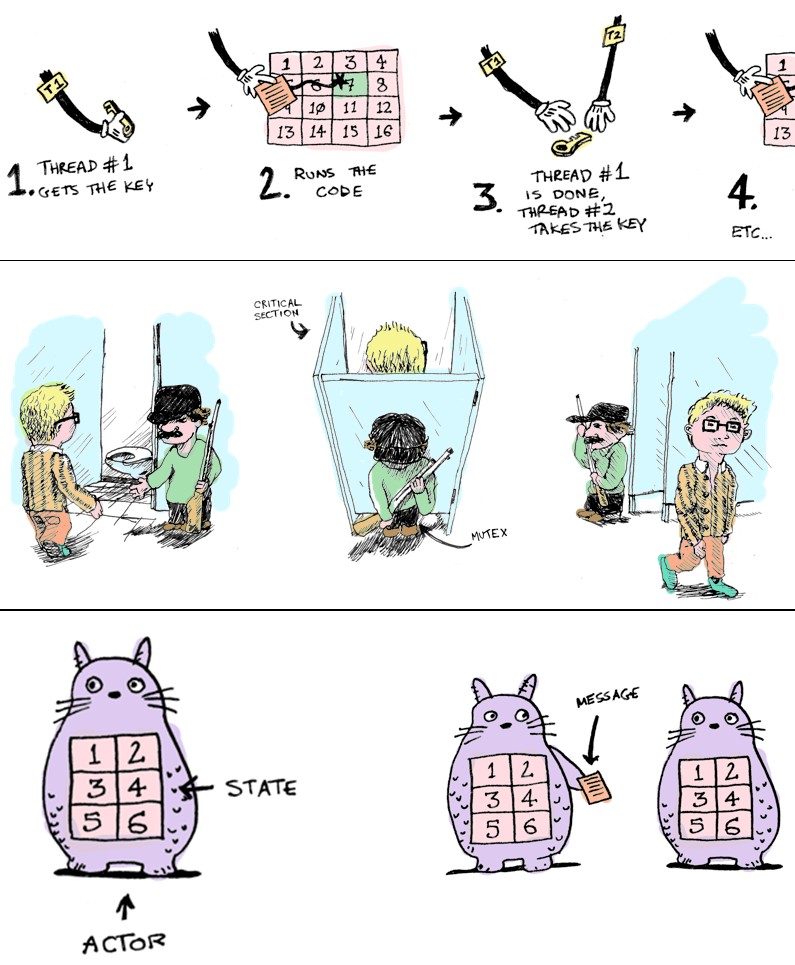
从历史上看,锁的问题如鬼魂一直伴随着我们:
1.用数据表一个字段来表示状态,比如1表示已付款未发货,2表示已付款已发货,然后用户来一个请求用SQL或存储过程修改,这时使用的数据库锁。
2.用ORM实现,比如Hibernate JPA来修改状态,虽然不用SQL了,但是Hibernate的悲观锁和乐观锁也让人抓狂。
3.彻底抛弃数据库,直接在内存缓存中进行修改,使用Java的同步锁,性能还是不够,吞吐量上不去。如上图提示,只能一个厕所蹲位一个人用,其他人必须排队。
4.Actor模型。
Actor模型原理
Actor模型=数据+行为+消息。
Actor模型内部的状态由自己的行为维护,外部线程不能直接调用对象的行为,必须通过消息才能激发行为,这样就保证Actor内部数据只有被自己修改。
Actor模型如何实现?
Scala或ErLang的进程信箱都是一种Actor模型,也有Java的专门的Actor模型,这里是几种Actor模型比较
明白了Actor模型原理,使用Disruptor这样无锁队列也可以自己实现Actor模型,让一个普通对象与外界的交互调用通过Disruptor消息队列实现,比如LMAX架构就是这样实现高频交易,从2009年成功运行至今,被Martin Fowler推崇。
回到本帖最初问题,如何使用Actor模型解决高并发事务呢?
转账是典型的符合该问题的案例,转账是将A帐号到B帐号转账,使用Actor模型解决如下:
发出是否可转出消息--->消息队列--->A
A作为一个对象,注意不是数据表,对象是有行为的,检查自己余额是否可转账,如果可以,冻结这部分金额,比如转账100元,冻结100元,从余额中扣除。因为外部命令是通过消息顺序进来的,所以下一个消息如果也是扣除,再次检查余额是否足够......
具体详细流程可见:REST和DDD
那么,既然Actor模型如此巧妙,而解决方向与我们习惯的数据喂机器的方式如此不同,那么如何在实战中能明显发现某个数据修改应该用Actor模型解决呢?因为我们习惯将数据喂机器的思路啊?
使用DDD领域驱动设计或CQRS架构就能明显发现这些特殊情况,CQRS是读写分离,其中写操作是应领域专家要求编写的功能,在这类方向,我们都有必要使用Actor模型实现,因为在这个方向上,领域专家的要求都表达为聚合根实体,聚合根就是用Actor模型实现最合适不过了。而读方向,比如大数据处理,报表查询,OLTP等等都是数据喂机器的方式。
有的道友会疑问,我们经常使用SSH,也就是Spring + Hibernate架构,这个默认是哪种方向呢?很显然,默认是数据喂机器的方向,所以在实现写操作时,特别警惕高并发发生死锁等影响性能问题,当然也包括EJB架构。
有一种togaf架构,将企业软件架构分为数据架构和应用架构等,实际是EJB或SSH的变相描述,这种架构的问题我们已经一目了然了,特别这样的系统如果从面向内部管理转向到SaaS模型时,这类高并发死锁问题就特别容易发生,几乎不具备可用性。前期12306火车票系统是这类问题的典型体现。
[该贴被banq于2013-09-12 08:09修改过]
[该贴被admin于2013-09-15 07:13修改过]
[该贴被admin于2013-09-15 07:29修改过]
[该贴被admin于2013-09-15 07:30修改过]