质疑Lambda架构
Google和Twitter刚发布它们综合实时流处理和批处理的Lambda架构,LinkedIn的Jay Kreps则对这种架构提出了质疑,指出实时处理和批处理其实是两种范式,将它们硬生生捆绑在一起会犯ORM框架一样的错误,并且提出一种类似EventSourcing或CQRS架构思路只要使用一个实时流处理框架解决两种框架捆绑在一起的问题。以下为大意翻译,原文见这里
Storm 作者Nathan Marz 发表了Lambda Architecture (见:How to beat the CAP theorem如何打败CAP 和Lambda架构两篇文章). Lambda Architecture是一个基于MapReduce 和 Storm 建立流式处理的应用,这已经被证明是一个非常令人激动的流行想法,LinkedIn也使用 Kafka 和 Samza 实现实时大数据处理,。
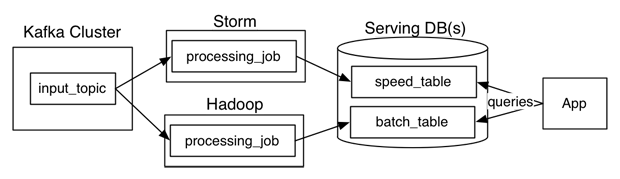
这种方式对于不可变的记录序列工作得很好,将这些不可变记录截获后并行地送进批处理系统和流处理系统. 实现逻辑转换两次,一次是在批处理系统,另外一次是在流处理系统,然后在查询时间将两个系统的结果混合在一起产生一个完整的响应结果。
在这里有许多变数,例如,你能使用Kafka, Storm, 和 Hadoop, 人们经常使用两个不同的数据库存储输出表,一个是为实时优化的,另外一个是为批处理更新优化的。
Lambda 架构是定位建立复杂异步的需要低延迟运行的转换场合。典型案例是建设一个推荐系统,需要抓取各种数据源,处理输入,索引 排序 任何存储便于读取处理结果。
我已经在LinkedIn建立这样一个大数据实时系统和pipeline系统,但这不是我喜欢的风格,下面我谈谈它的优缺点,然后表达我喜欢的风格。
Lambda架构的优点
我喜欢Lambda 架构注重输入数据的不可变性,我认为建模一个从原始输入到系列过程的数据转换必须遵照纪律会有很多好处。这能建立一个可跟踪的大型MapReduce工作流,让你可以独立调试每个阶段。
我也喜欢Reprocessing 重新处理数据,也就是将输入数据再计算一次输出,只要你的代码变化,你需要重新计算一下结果,以便查看代码对数据处理结果的影响。
那么代码为什么会变化呢?也许你的应用在演进,你需要重新计算输出一些新的字段。或者你发现Bug并订正了它。无论什么原因,只要代码变化你都需要重新产生你的输出。
有很多针对Lambda Architecture反对意见,他们认为流式实时处理与批处理本质上类似,没有后者强大,经常会丢失数据,不稳定,流式技术是没有现在批处理计数成熟,但没有理由认为流处理系统不能如同一个批处理系统提供强大的语义保证。
lambda架构的缺点
Lambda Architecture 的问题是改变代码后需要重新在两个复杂的分布式系统中再次处理输出结果是非常痛苦的,而且我不认为这个问题能够解决。
为什么流式处理系统不能自己提高到处理整个数据,不需要借助批处理框架?首先得有一种语言框架是基于实时和批处理两种模型的抽象,你可以使用这样高级框架编程,它会编译到流处理或MapReduce, Summingbird 是这样的一个框架(见http://www.jdon.com/46501
). 但是我还是不认为它解决了问题。
最终即使你可以避免两次编码。在两个系统中运行和调试代码的负担也是比较高的。任何抽象只能提供两个系统交叉部分的共同特点,更糟糕的是,致力于发明一种新的超级框架会脱离Hadoop强大的生态圈 (Hive, Pig, Crunch, Cascading, Oozie, etc).
以类推方式,想想跨数据库ORM框架臭名昭著的困难,试图跨越这两个系统提供一个近似标准接口语言也会如此,试图在两个不同编程范式的顶部建立一个抽象层是非常难的。
LinkedIn的经验
我们已经在LinkedIn通过数轮实践。我们已经建立了混合各种Hadoop架构和甚至提供一个特定领域的API(DSL),允许代码 “透明”的运行在实时系统或在Hadoop上。这些方法能够工作,但不是很好或具有生产性。保持两个不同系统的代码完全同步,真的,真的很难。该API是隐藏了底层框架。这样就不需要深入Hadoop和实时的知识就能加入的新的需求。
关于使用类似MapReduce这样的批处理框架我的建议是:如果你对延迟(性能)很敏感,你可以使用流处理框架,否则就不要试图将两者混合一起使用。
那么Lambda Architecture激动点在哪里呢? 我认为那是因为人们日益迫切需要构建一个复杂的低延时的处理系统,一种是可伸缩扩展的高延迟批处理系统只能处理历史数据,而低延迟的流式处理系统并不能重复处理产生结果,通过横跨这两个系统放在一起,他们就能得到一个有效的解决方案。
虽然这是有痛苦的,但是Lambda Architecture也是解决了重要问题,否则就会被普遍忽视,但是我不认为这是一个新的范式,或代表大数据未来。这只是一个临时状态,会有更好的替代。
替代方案
我认为首先考虑下面问题:为什么流式处理系统不能提高到能处理整个领域问题?为什么需要和另外一个批处理系统搅和在一起?为什么你不能既做实时流处理也能实现在代码变化时进行重复处理reprocessing?流处理系统已经有很好的并行机制,为什么不通过提高并行来实现重复处理reprocessing和很快地重新播放历史?答案是你能做这些,这就是我认为可以有更好替代的理由。
有人会说流式处理对于历史数据的高吞吐量会力不从心,但是我认为这是因为他们使用系统的限制或可伸缩性不够或不能保持历史数据。那么流式系统如何实现重复处理reprocessing呢?我的答案很简单:
使用 Kafka等类似系统保留住你要重复处理的完整日志数据,并且允许它有多个订阅者,比如你要重复处理30天数据,你就让Kafka保留到30天。
当你要开始再次处理reprocessing数据时,你只要从你流式处理job第二个实例开始处理你的保留数据,但是这次输出数据是直接输出到一个新的输出表,当这第二个job实例完成后,切换到应用从这个新表中读取,然后停止这个job的老版本运行,再删除刚才的输出表。
不像Lambda Architecture,,这个设计只是在你代码改变时实现重复处理,也就是重新计算你的结果. 你需要启动并行机制让这个工作更快些。
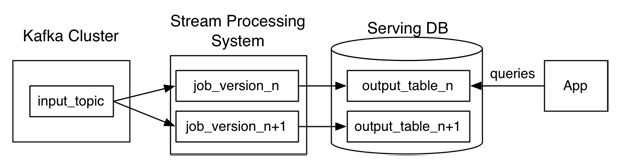
我们可以称为这个架构为Kappa Architecture, 我们已经有文档说明如何使用Samza实现重复处理reprocessing 架构的 。
实际上这个主意和Kafka一点也没有关系. 你可以使用有序保留长时间数据的介质来替代如HDFS或某些数据库. 如果熟悉Event Sourcing 或 CQRS的人不会感到陌生。
我们在使用Samza已经这样成熟运行一段时间,这个方案真正的优势不是效率,而是让人们在一个单一的处理框架下开发,测试,调试,操作系统。所以,如果简单是重要的,那么可以作为Lambda架构的替代。
相关:
Lambda架构
如何打败CAP
Twitter基于时间流的聚合设计
Google使用Pipeline统一了大数据批处理和流处理