Hadoop与Spark等数据处理系统哪个是最好的?
如今我们拥有广泛的数据处理系统选择:Hadoop, Spark, Naiad, PowerGraph, Metis 和 GraphChi 等,这些不同框架的最佳性能其实高度依赖于高阶的工作流程,其次,没有某个单个系统总是会比其他系统性能高,也就是说,几乎每个系统都有自己特定场景下的最好性能表现。
所以,选择一个数据处理系统应该将其工作负载贴近其最佳设计点,但是我们很容易忽视这点,导致宗教式的争论:哪个数据处理系统是最好的,这些争论往往没有背景前提。
选择一个正确的并行数据处理系统是困难的,它需要大量的关于编程范式、设计目标和许多可用性的实现等专家知识。
影响系统性能的四个关键因素有:
1.输入数据的大小,对于较小的数据输入,单机架构要优于分布式架构。
2.数据的结构,这会影响I/O性能和工作分发。
3.数据处理系统的自身建设中的工程决策,比如它是如何有效率的加载数据
4.计算类型,因为越专业的系统会更有效的运作。
所有系统数据来源与最终目地都是在HDFS文件中。
下图横坐标是数据量大小,纵坐标是时间。可见数据输入量小于0.5GB,其中紫红的Metis单机MapReduce性能最好:
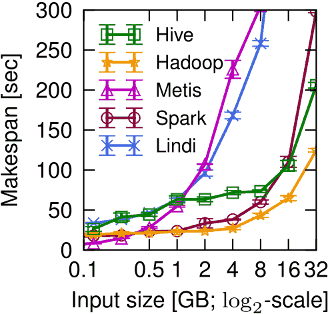
对于40-80%的job提交到MapReduce系统,最好选择是运行在单机系统。一个大型的join产生29GB的系统采取Hadoop比较合适。
一旦数据规模增长,Hive, Spark 和 Hadoop都会优于单机的Metis,至少是因为他们都能将HDFS的进出数据并行流化处理,但是不管如何,因为在工作流程中没有数据重用,Spark性能会更差于Hadoop,它在进行计算前会将所有数据都加载到分布式内存RDD。
对于涉及图的迭代计算时,毫不奇怪特定的图形处理系统会更好。面向图的范式有很强的优势,运行在Naiad上的GraphLINQ会明显优于其他系统,PowerGraph也表现得很好,因为它的vertex-centric分片会降低通信开销,它在PageRank领域一直占据主导。当然,最快的系统并不总是最有效的。
总结:实验表明,对于一个工作流变化很大的系统最好的选择取决于,这个最好是指最快或最有效的系统,这些依赖于工作流本身、输入数据大小和并行规模。
Musketeer – Part I : What’s the best data processi
[该贴被banq于2015-04-28 08:14修改过]