机器学习术语通俗易懂的解释
人工智能是基于数据做出判断和预测,机器学习能够让计算机实现数据驱动的决策,但是目前机器学习很多算法名词非常复杂,本文试图用浅显易懂的语言解释机器学习领域的相关术语.
监督学习Supervised Learning
让程序首先基于预先定义的数据集进行训练,离开这些训练数据以后,这个程序还能基于新的数据进行精确判断。
非监督学习Unsupervised Learning
程序自己能够窄一段数据集中自己自动发现模式和关系。比如,分析Email数据集,能够自动根据主题进行分类归组,在这之前无需任何事先的相关知识数据的训练。(先天的判断力,无需后天培养)。
分类Classification
这是监督学习的子目录,分类是对某种数据输入,能够为他们分配标签进行分类(比如将人分为男人和女人,不过出于对人的尊重,尽量不要对人标签化)。分类通常是用在预测结果是离散的,要么是肯定,要么是否定的情况下。比如,将一张人的图片分类为男人或女人。
回归Regression
监督学习的另外一个子目录,当预测结果不是简单的的"是"或"否"时,也就是说,预测结果是一段连续的范围,比如"多少钱"或"多少东西"等。
决策树
使用类似树形结构的图模型进行决策判断和可能后果的判断,比如下面:
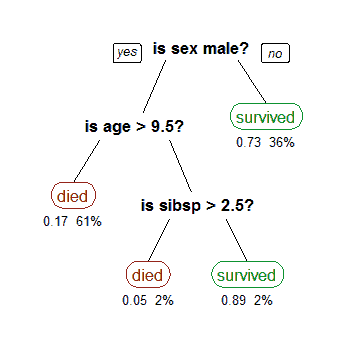
生成模型Generative Model
在概率和数理统计中,生成模型是在一些参数被隐藏时用于产生数据值。生成模型既可以直接用来建模数据,也可以作为中间步骤用来形成条件概率密度函数,比如你建模p(x,y)是为进行预测,
它能使用贝叶斯规则转为p(x|y),也能够生成像(x,y)数据对,能够广泛应用在非监督学习中。生成模型包括:Naive Bayes, Latent Dirichlet Allocation 和 Gaussian Mixture Model.
判别模型Discriminative Model
判别模型或条件化模型是用来建模基于变量x的依赖变量y,因为这个模型需要计算条件概率,如p(y|x),经常用在监督学习中,具体有: Logistic Regression, SVMs 和 Neural Networks.
深度学习
使用人工神经网络产生模型,能够解决图片辨识问题,因为它有能力获得识别事物的特征。
神经网络和人工神经网络
被定义为为统计学习模型,用于实现依赖大量的输入的估算或近似函数。神经网络通常用于有大量输入数据,这些数据对于标准的机器学习太大了。
