Cassandra+Akka+Spark分布式机器学习架构
目前基于Mesos的 Spark, Akka, Cassandra 和 Kafka (简称SMACK)架构将机器学习 大数据分析 快数据实时流处理和集群自动化管理结合一起,形成大数据领域的主流架构。
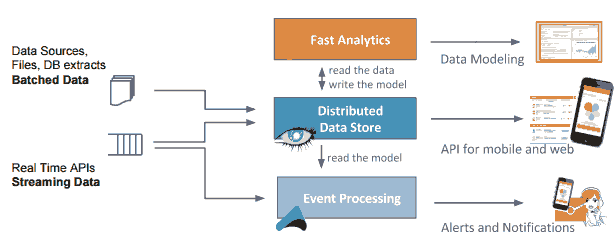
数据分为快数据和大数据;快数据包括相关的最新信息以及提供可操作的事件。大数据是有关分析与模型和学习,聚类,分类以及组织事实。
下图是展示对大数据和快数据分别进行批处理和流处理以后,进入分布式数据存储系统,然后再为最终用户分别提供分析报告和实时提醒报警服务。
为了实现这样一个目标设计,使用Akka-Cassandra-Spark 组合实现,如下图:
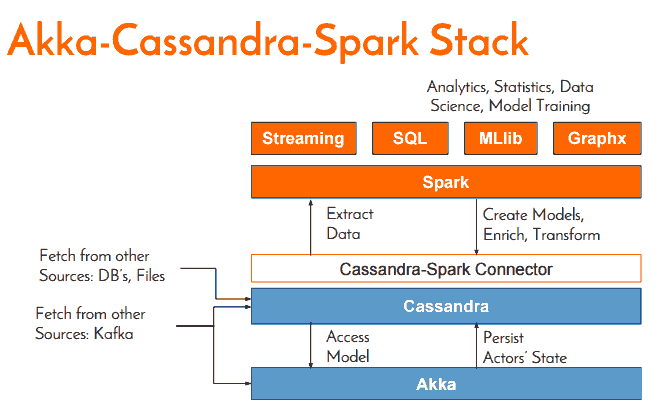
Spark从Cassandra中释放数据,创建模型,丰富模型,改造模型后再写入到Cassandra;而Akka负责从Kafka消息系统接受处理事件,以及实现实时响应式的提醒和报警服务。
使用Akka持久化接受进来的事件到Cassandra,也就是将Akka有态actor将其内部状态持久化保存,这样当遭遇崩溃或重新启动或集群迁移时,actor能够从Cassandra中恢复状态,这是使用event sourcing原理,只是将改变actor状态的事件持久化,而不是直接持久状态,这是以一种日志方式保存。这种方式有很高的事务性和复制高效性。
英文资料:
使用Spark MLlib, Akka and Cassandra进行实时异常检测
Using Spark to analyse Akka persistence journal in Cassandra
Streaming Big Data with Spark, Spark Streaming, Kafka, Cassandra and Akka
[该贴被banq于2015-10-31 14:29修改过]