对机器学习的一些怀疑理由
机器学习人工智能是非常热门的词语,本文却列出机器学习的几个缺陷,这有助于人们重新思考机器学习。
首先,机器学习的模型只对你喂给它的数据表现得足够好,比如一个预测系统,给出一个人的姓,该系统就能预测这个姓来自哪个国家,John也许是美国人,而Johannes也许是德国人。
但是如果你没有使用中国姓名来训练这个系统,它就无法辨识中文姓名了。
也就是说,如果你只用英文世界的大量数据训练你的模型,而除了英文世界以外的情况你的模型就可能无法辨识。
其次,模型也有自己的bug,机器学习通常使用编程语言实现,而编程语言有bug。而且bug会超过普通程序,见:Machine Learning: The High Interest Credit Card of Technical Debt
最后,机器学习模型有可能全部错了,假设你使用了经得起质疑的数据集去训练你的模型,但是人们可能会愚弄它,比如google photo应该是用机器学习辨识图片的,然后给这些图片加上关键词。作者准备在自己的google photo中搜索baby图片,结果出来的图片中没有一个是baby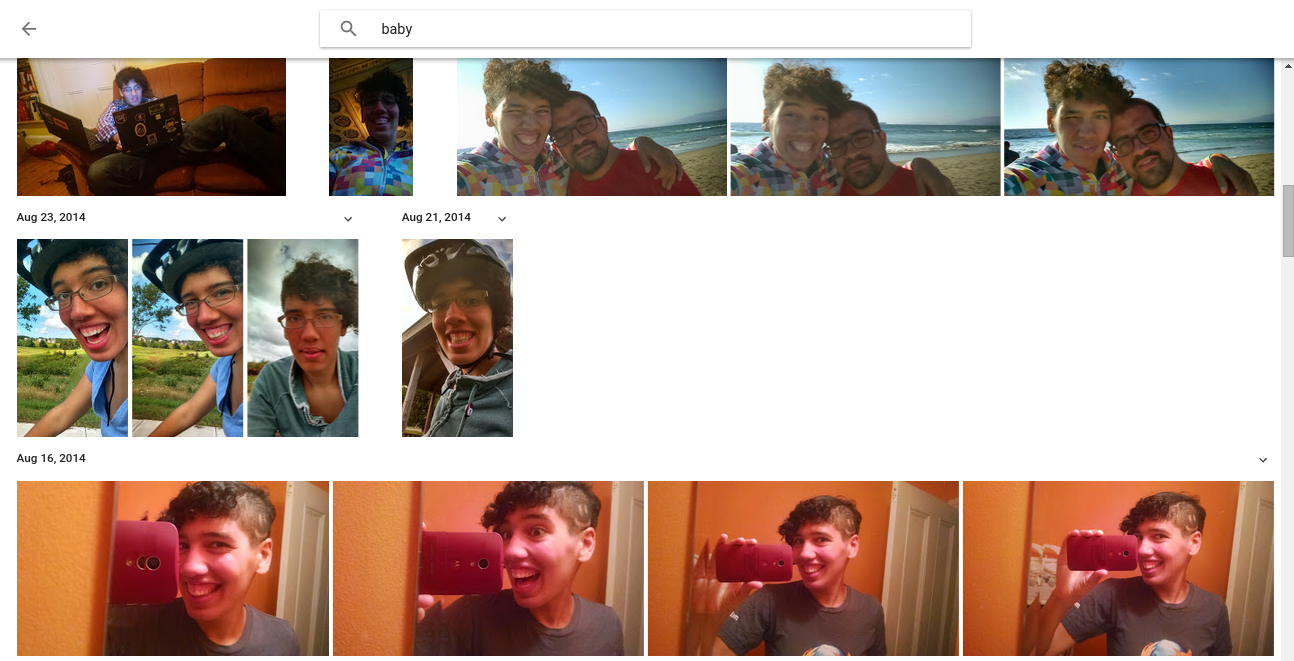
总结,Cathy O'Neil'的博客一直谈论出自一些统计模型的东西总会出现不是客观事物,或者基本的正确性。
Carina Zona在Consequences of an insightful algorithm认为,机器学习模型会意想不到的负面后果,比如著名的目标怀孕Target pregnancy案例。