MySQL、PostgreSQL、MSSQL、DB/2、Oracle比较
您通常需要为OLTP(事务/操作)数据库选择RDBMS。 本文提供一些建议。首先定义一下对于生产级别的24×7 OLTP RDBMS很重要的一些功能。
基于锁与MVCC
对于读写混合的操作来说,MVCC某种程度上好于锁,如果隔离级别高于Read Uncommitted;当然OLTP场合很少见大量并行读取,如果有,读取副本。
对于大部分是纯写的 OLTP,基于锁的数据库会比 基于 MVCC 好一点,另外一方面说,如果用于Insert 而不是Update,MVCC效率会高些。
ACID
如上所述,对于OLTP数据库,我们确实需要全面的ACID事务 。 此外,我们需要涉及多行和多个表的ACID事务。
这几乎自动排除MySQL + MyISAM OLTP DB。 请注意,对于相当多的应用程序(例如,作为快递跟踪系统的后端或作为系统监控工具的后端),MySQL + ISAM可能比较适合 - 但是通常的OLTP处理会涉及与货币相关信息。
您的RDBMS提供ACID保证几乎暗示它有一个DB日志; 这通常意味着在RDBMS崩溃的情况下它可从DB日志自动恢复(和自动化前滚)。
支持24×7操作
1. 在线备份。 无论我们在做什么 - 我们希望有一个备份,24×7操作的在线备份变得必要。在线备份还意味着“日志前滚”功能。 大多数时候 - 你可以有2个DB,一个是“Master”,另一个是“Slave”。 你只需从“Master”获取日志文件,将它们发送到“Slave”,并在Slave上“前滚”它们。
作为在线备份的候选,异步主从复制能够用于保持大部分备份同步。
调整数据表结构,这是通过ALTER TABLE ... ADD COLUMN语句完成的。 当面对ADD COLUMN语句时,相当多的RDBMS会简单地将整个表重写为新的行格式。 如果你的表有十亿行 - 好吧,这将需要很多时间。(而在复制正在进行,所有对该表的访问被阻止,所有这些时间使得数据库变得不可用),可使用下面办法实现无锁ADD COLUMN(和一般的ALTER TABLE)如下:
1.创建一个具有新结构的“影子”表
2.使得触发器将从当前表中写入所有修改
3.将数据从当前表复制到“影子”表(忽略通过触发器已经保存的行)
4.用当前表替换“影子”表
需要注意在线表的优化,由于RDBMS不断修改它的表 - 表会逐渐降级(事实上,所有类型的讨厌的事情发生取决于使用中的存储引擎 - 从“溢出行”到“死行”),处理优化(对于InnoDB称为OPTIMIZE TABLE,对于DB / 2称为REORG TABLE,对于Postgres等称为VACUUM)变得必要 - 我们希望在线进行(不停止整个业务处理,因为优化一亿行的表可能需要一段时间)。大多数时候,这种优化将需要创建一个“shadow copy卷影副本”(由DB保存,这总是比自己做的更好),这意味着额外的空间要求。 另一方面,至少一个RDBMS提供“就地”表优化。
容器重新平衡,虽然不像上面列出的其他问题那么重要,我仍然认为“容器重新平衡”是RDBMS的重要加分。在添加一对新磁盘之后,我们需要在磁盘之间重新平衡以重新平衡负载 - 这种重新平衡将分别由RAID或DB完成。RAID级别的重新平衡通常会导致比DB级别更严重的性能损失。
性能
性能(尤其是写入性能)是对OLTP数据库的关键。下面是几个优化技巧:
(1)SQL编译器的hint。当我们将SQL提供给RDBMS时,它会被编译成一个“执行计划”。 而且(尽管DB开发人员可能认为或DB销售可能告诉你)编译器往往会不时出错。 只有下面问题发生时才会成为普遍情况:
1.我们使用基于统计(也称为基于成本)的SQL编译器
2.我们有一个大的历史表,带有TIMESTAMP字段
3.统计数据有点过时 - 几个小时/天(通常是)
4.我们正在编译SQL,它基于T =最后一小时获取一些数据。
要处理这样的(以及相当多的其他)事故 - 有所谓的“SQL编译器hint提示”。 “提示”允许我们强制RDBMS进入我们想要使用的执行计划(对于99%的OLTP语句,可以提前告诉最佳执行计划)。
(2)OLTP性能问题:
Postgres:ctid即使更新非索引字段也会更改,Postgres已经被观察到在最新真实世界中当有相当多的索引时存在严重的性能问题。
MemSQL:轮询日志写入,MemSQL使用50毫秒轮询发出写入数据库日志。 这对于任何类型的 OLTP数据库来说是一个非常不好的做法。
(3)执行计划和分析
为了了解生产中DB工作情况,你需要调试和配置您的SQL语句。 要做到这一点,你需要一个最低限度的工具,可以显示您的SQL查询的“执行计划”。 这允许预测执行查询的方式(即,如果要将SQL编译到生产数据库的执行计划中,或者是从生产导入的统计数据库中)。
在另一方面,执行计划只显示预测执行(从数据库统计计算)的成本; 在实践中,这个成本大小可以按数量级不同而不同。
为了定位问题 - 可以使用某种实时分析。 这可能是一个有用的工具,虽然IMO不是绝对必要的:通常,通过一些经验和使用一些常识,查询的性能问题很容易识别。
(4)内存处理
相当多的RDBMS提供内存处理选项。 这些可以分为两大类:
1.非持久内存处理。 这包括在RAM中运行RDBMS,以及MySQL的MEMORY存储引擎。 不幸的是,这些通常在OLTP DB中不能接受。
2.持久的内存处理。 这可以看作是在您的应用程序和RDBMS之间有一个内存中缓存(实际上,Oracle的TimesTen IMDB 甚至作为缓存上市)。
复制
在一个严重的负载下,你很可能迟早需要一个DB的复制用于只读。 如果你的RDBMS支持复制,你不需要DIY。
我们最需要的是所谓的主从(Master-Slave)异步复制(副本复制延迟不会影响Master)。 其他特征例如合并复制能力(在简单的主 - 从异步环境中 - 并且没有任何冲突)也可以使用。
RDBMS提供的副本在重负载下表现相当糟糕。 在一种极端情况下 - 在几天之后,在小于1M个事务/天的负载下,复制会发生一些不明显的错误而导致脱离同步,这需要完全重新同步副本(巨头痛)。
在依赖它之前,一定在严重负载下测试您的复制
分区
RDBMS提供的分区是一个被高度推崇为实现可扩展性的东西。我倾向于更喜欢纯Share-Nothing模型(具有应用级分区),因为它们比跨不同服务器分区DB提供更多的线性可伸缩性。 仍然,有些情况下,RDBMS提供的分区可以是有用的。
关于OLTP非问题
JOIN虽然所有这些对于“报表”数据库和“分析”数据库都非常重要 - 根据经验,它们对于OLTP并不重要。
OLTP DB是一个非常奇怪的野兽; 特别是 - 使用JOIN的语句相当罕见。
MySQL、PostgreSQL、MSSQL、DB/2、Oracle对比表见:
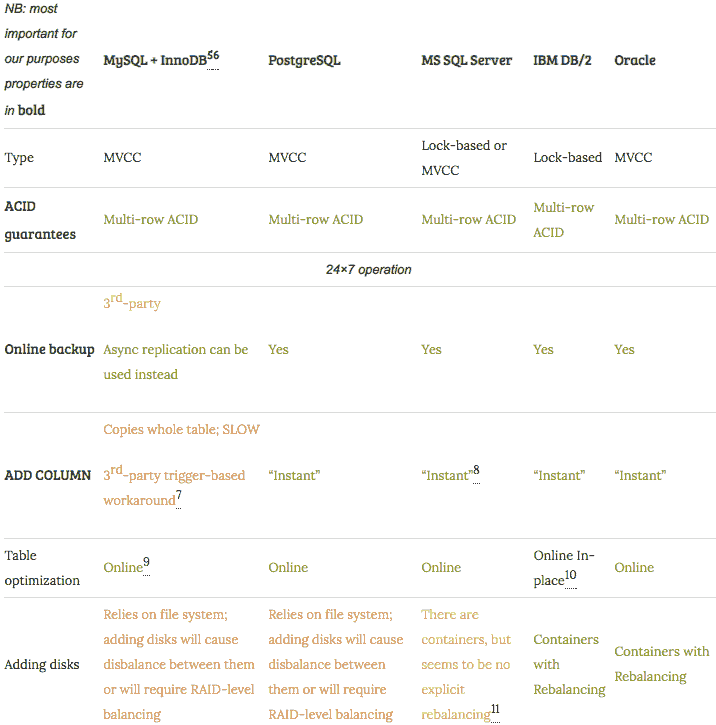
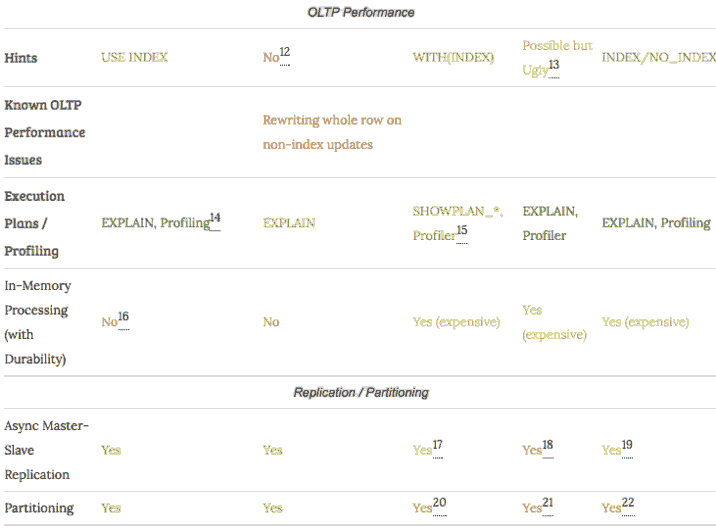
MySQL vs Postgre vs MSSQL vs DB/2 vs Oracle for OL
[该贴被admin于2016-11-16 15:01修改过]