Drivetribe采取CQRS和Apache Flink的经验分享
Drivetribe是由前Top Gear三剑客克拉克森、哈蒙德和梅创办的在线垂直汽车社区, Aris Koliopoulos作为其高级软件工程师,所在团队负责从无到有建立这样一个社区产品,目标是从一开始就可以处理高用户量和大规模运行,因为这是一项明星产品,一旦上线会立即吸引大量粉丝,因此不得不对Drivetribe架构进行及早决策。
在这篇文章中,我们将解释如何Apache Flink等技术建立drivetribe.com,也会讨论如何为最终用户提供更好的体验。
Drivetribe简介
首先,谈一点点关于drivetribe是什么样社区网站。当用户创建帐户后,可加入“Tribes部落”,这是有特定主题的团体,举办者可以是三个联合创始人之一或其他博客,专家和汽车爱好者们。
部落的主题涵盖了从复古、越野、到世界各地旅行。在部落中,用户可以发布自己的内容和评论,转发,或“bump撞”(我们的术语为“喜欢”)由其他用户发布的内容。
用户的home feed会凸显其最活跃的部落,也显示了他们在部落中新的他们会感兴趣的新帖子。这需要我们进行个性化用户的内容。当从零开始(手上最小的训练数据)启动一个像我们这样的产品,对内容方面有关排序模型的灵活性是必不可少的。
架构概述
drivetribe是一家数据驱动的公司,我们想捕捉一切并计数计量。当第一次思考我们的架构时,我们认为传统的方法:无状态服务器加上包含可变状态的数据库,在状态转换时并不记录历史转换日志,这样的架构一旦出错,就无法追踪错误原因,这种不够灵活性完全不符合我们的要求。
我们是一个Scala开发者团队,我们感谢不变性。此外,在尝试不同的算法的能力和快速迭代的规模也是非常重要的。这导致了我们的第一个决定:利用事件溯源Event-Sourcing和命令查询职责分离(cqrs)。
事件日志的存在作为事实真相的来源在产生物化视图(materialised views)时提供了极大的灵活性。不同的团队可以并行工作在相同的数据。算法可以很容易地更换和应用到整个事件的历史追溯。同样的方法可以应用到bug修正。没有任何服务中断删除情况下,每一个服务的下游消费可以加载和升级。
cqrs提供单独的读路径和写路径分离,易于优化和独立扩展。
这个过程是有一个陡峭的学习曲线。需要找出有多少组件需要配置、部署、维护和缩放。微妙的错误可能危及分布式程序的正确性,在系统级别上就无法保证一致性。
Golden Hammer是一个著名的反模式工程,我们的方法也不是适合每一个分布式系统。然而,它具有大型发布平台平台的潜力,因此我们决定冒险去实现它。
刚开始建立这样一个体系结构,我们需要做出一些重要的决定。Apache卡夫卡™是可扩展、容错、可靠的分布式日志。理所当然选择它作为我国架构的骨架。
系统的入口点由一个一大堆无状态RESTful服务器组成。他们消费来自Redis从Elasticsearch的物化视图和产生的数据以消息的形式放入卡夫卡。这是相当简单的。
这个架构最具挑战性的部分是选择下游分布式的卡夫卡消费者。评估备选方案时有几个选项:Apache Storm,Apache samza,Apache Spark,和Apache Flink。我们评估是基于一些标准系统:
1.可证明的可扩展性和鲁棒性
2.高性能
3.丰富的、可扩展的API
4.管理状态和与其他部分集成测试能力(即卡夫卡,redis,和ElasticSearch集成)
其他因素也被考虑在内,如活跃的开源社区,如果有需要商业支持的能力。
最初的评估和试验阶段后,Flink赢得了比赛。这是唯一的胜出者,时刻关注状态的数据流。
Apache Flink在drivetribe
在平台上产生信息的每一个字节都经过卡夫卡Kafka到弗林克Flink。用户的行动是由卡夫卡的消息表示,Flink是负责消费这些信息并更新我们的内部数据模型。
我们运行大量Flink的job,从简单到复杂的状态还原持久。持久化是在平常的情况下,持久一个数据点到服务Serving层已经足够。
持久化用户的评论,或“撞”时,Flink的低延迟使我们忽视了API级别的最终一致性。
然而,Flink真正的力量在于两个关键特征:状态的计算和定义的拓扑结构的能力。在drivetribe,我们计数统计和汇总统计任何数据。他们中的一些是用户可见的(即凸点数、评论数、印象数,每天bumps数)。
其它许多其他属性则是用于我们内部的排序模型。新闻内容是算法生成的,通过Flink实现我们的排名模型。此外,我们最近推出了通过Flink的流数据协同过滤能力实现了产品推荐。
我们计算统计平台的每个实体。在默认情况下,需要大量的状态。Flink的状态流的抽象定义窗口和folding使得工作轻松。我们只需要定义集合一个适当的数据类型(例如,计数器可以建模为Monoid),然后Flink照顾哈希分区密钥空间和执行分布式计算。这使我们能够计算出关于内容的元数据,如点击率,“魅力”,合作等,使用此元数据喂食内部排序和预测模型。
当然,代码是漏洞百出,算法也可以提高,可以增强其特征。事实上,事实源头是一个日志,包含所有发生事件,这是一套改变我们的实现部署的新的工作过程,使用新的算法产生事件流,。在几个小时内,这个平台提供了完全可更新的视图。对于一个如我们年轻的初创公司,能随时改变我们的想法和提高迭代速度的能力是非常有价值的。
回放卡夫卡时提出了一系列的挑战。从一开始的每一个状态转移都变得可见了,虽然很方便观察,但是对于一个运行系统是不可接受的。为了解决这个问题,我们采用了黑色/白色架构(也被称为蓝色/绿色)。
从概念上讲,drivetribe有两个系统,黑色和白色。每个人都有自己的Flink集群,Elasticsearch集群,Redis集群和RESTful服务器。他们都有卡夫卡。下图描述了上述的结构。
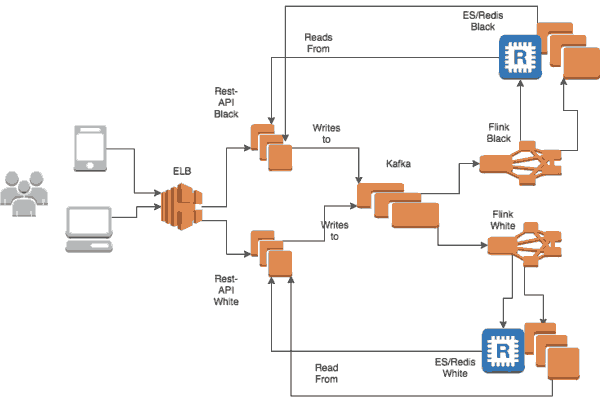
这种方法使我们能够在服务层平行于正在运行的系统重建Flink状态和下游的物化视图。一旦这个过程完成,一个简单的负载平衡器重定向流量到新系统,无需停机。适合重大变化的部署,无计划的停机,或痛苦的数据库迁移。
一个主要挑战是重播卡夫卡要不违反因果一致性,从而才能够产生确定的状态。事件通常有某种因果关系;用户在加入部落之前需要被创建,和在收到“bumps”,浏览或评论之前帖子必须被创建。
卡夫卡只能保证一个主题topic分区内的有序。假设带key的消息,所有的消息都对应一个key,这个key是按顺序递交传递的(因此,对同一个key发生“删除”后不会发生“更新”事件)。然而,Flink的job常常消费多个主题,Flink允许使用任何字段作为流的Key。当处理消息到达时,就是假设在所有消息传递路径都有相同延迟(这实际是不可能的),消息之间因果关系还是会被破坏。任何流如果消费多个主题,或者使用不同的多于一个的key分区信息,都需要考虑到这种情况。
三分之一个挑战还来自重复的存在。Flink虽然能保证“精确一次exactly-once”传递其内部状态,以整个管道考虑这是非常困难的:一个客户端两次发送相同的请求,或是卡夫卡的生产者会发送两次消息,这意味着卡夫卡已经存在重复。一个接收者将两次向外部系统提供处理后的信息,一个简单的计数器可能会计算错误的结果。简单的处理方法是,每一个消息有一个唯一id,每次请求都是幂等的。。我们对计数实现带有语义的数据结构,我们对外部系统只执行幂等更新。
另一个挑战是我们所谓的“克拉克森明星效应The Clarkson Effect”。杰瑞米·克拉克森是非常受欢迎的–它的多级别超过普通用户级,这同样适用于部落和他的帖子。当试图分配key空间,流计算可以分布到多个节点,我们很自然地实现了倾斜计算的问题。当需要计算浏览量和他的部落已收到的总数时,这成为问题,例如。如果每一个浏览都访问rocksdb,这个访问数据库过程自然变得缓慢和积聚背压back pressure 。为了缓解这一问题,我们利用Flink的低级API开发了一个内存缓冲区计算:预汇总或局部汇总计算,使用处理时间触发传播结果到下游。
最后,直到多消息commit在卡夫卡成为现实,平台是不支持开箱事务的。然而,在产品各方面要求事务语义。例如,当用户被删除,每一个部落/后/评论/等与他们的需求也被删除。这是一套需要致力于在多个主题单元信息。部分传播可能会导致不一致的状态,当用户被删除,但他的帖子依然出现在平台上。
虽然卡夫卡不支持事务,但Redis是支持。消息是作为一个组提交到Redis,然后在Flink自定义Redis源获取消息推到卡夫卡。因为卡夫卡的语义一般是“至少一次”,消息是幂等的真的很重要。如果消息生产过程未能提交消息到Redis的事务作为一个整体将视为失败。如果消费进程崩溃,Flink将重新启动并重新处理消息。如果我们认为Redis是事务日志,这基本上被认为是一个向前滚动的语义Saga事务。
Flink的开发经验
Flink的高级别API使定义状态流的计算简单容易地操作Scala集合。Flink的低级别API允许有经验的用户扩展和每个流的用例优化。
在生产运行Flink我们努力地学习一些技巧:
1. 尽可能多运行job。理想情况下,每一个图一个job。无论多好的测试代码,仍然会在生产环节有失败,实际上是提供一种可降级的服务水平很重要。此外,每个图都有不同的要求,能够管理就很重要,还要能独立扩展和独立解决自己的问题。
2. 注意每个key的状态大小。当每个key增加几百KB时候流性能会降低。此外,推送大量消息到下游最终会导致网络饱和堵塞。
3. 当使用卡卡savepoint保存点注意有状态的操作。运算符名称必须是唯一的,所有的类引用需要保持不变。否则,反序列化将会失败,状态将不得不从头开始建立。
4.注意检查点checkpoint管理。检查点不是自增的,如果没有后台进程清理很容易耗尽磁盘空间。
5. 花时间去建立一个适当的部署管道。持续集成不是像停止和启动一个无状态服务器那么简单。这需要时间来完善。
6. 连接流会很重。如果目标是很多数据,考虑denormalising上游。
7. 应该使用消息key和有效载荷payload,才能利用卡夫卡的压缩主题功能。这可以节省存储空间,减少加工时间和提高排序保证。更新事件应该包含完整的更新payload(如更新用户配置文件),而不是一个差异版本。
8. 收集和分析数据,否则很难调试生产中出现的问题。
Drivetribe’s Modern Take On CQRS With Apache Flink