分布式系统的弹性设计
在讨论分布式系统的弹性之前,让我们快速回顾一些基本术语:
弹性Resiliency:任何系统从困难中恢复的能力,(banq注:弹性也就是适应能力)。
分布式系统:一些网络组件通过传递消息来完成一个共同目标。
可用性:任何系统在任何时间点保持正常运行的可能性。
故障与故障:故障Fault是您的系统中是不正确的内部状态。系统中一些常见的故障例子包括:
1.存储层缓慢
2.应用程序中的内存泄露
3.被阻塞的线程
4.依赖性故障
5.在系统中传播坏数据(通常是因为输入数据没有足够的验证)
失败Failure是系统无法执行其预期工作。
失败意味着系统正常运行时间和可用性的损失。故障如果不被封装,会导致在系统中传播,从而导致失败。
当故障Fault转为失败Failure时就意味着系统发生了故障:
弹性就是为了防止故障Fault转化为失败Failure
我们为什么关心系统的弹性?
系统的弹性与其正常运行时间和可用性成正比。系统越有弹性,服务用户的可用性越高。
如果不具有弹性能力,可能会以多种方式影响公司各个方面。
分布式系统的弹性设计很难
我们都明白'可用'至关重要。为了保证可用性,我们需要从零开始建立弹性,以便我们系统中的故障自动恢复。
但是在具有多个分布式系统的复杂微服务架构中建立弹性是很困难的。这些困难是:
1.网络不可靠
2.依赖性总是失败
3.用户行为是不可预测的
虽然构建弹性很难,但并非不可能。遵循一些构建分布式系统的模式可以帮助我们在整个服务中实现较高的正常运行时间。我们将讨论未来的一些模式:
模式[0] = nocode
|
你写的代码中最有弹性的代码是你从未写过的代码。
你写的代码越少,破碎的因素就会越低。
模式[1] =超时
停止堵塞住一直等待答案,就要设置超时。
我们来考虑这个场景:
你有一个健康的服务'A'依赖于服务'B'。但是服务'B'因为受到影响并且速度很慢。
默认的Go HTTP客户端是没有HTTP超时。这会导致应用程序泄漏go-routines(处理每个请求Go产生一个go-routine)。当您的下游服务缓慢/失败时,go-routine会永久等待下游服务的回复。为了避免这个问题,为我们的应用程序中的每个集成点添加超时非常重要。
如果您的任何下游服务在规定时间内例如1ms没有回复,那么你就可以认为是超时,实现快速失败fail fast。
应用程序超时有下面方式的好处:
1.防止级联失败
级联失效是非常迅速地将故障传播到系统其他部分的失败。
超时有助于我们通过快速失败来防止这些故障。当下游服务出现故障或速度较慢(违反SLA)时,那就不要永远在傻等响应,尽早提前失败,还能挽救你的系统以及依赖于你系统的系统。
2.提供故障隔离
故障隔离是将故障仅隔离在系统或子系统的某个部位。
超时能不让其他系统问题成为你的系统的问题,从而实现失败隔离。
应该如何设置超时?
超时必须基于您的依赖关系提供的SLA。比如可能是99.9%。
模式[2] =重试
如果发生一次失败,请重试
重试可以帮助减少恢复时间。
处理间歇性故障时,它们非常有效。
重试请求也可以设置超时,重试与超时可以一起工作良好。
立即重试可能并不总是有用
依赖上的失败需要花费时间来恢复,在这种情况下,重试可能会导致
用户的等待时间延长。为了避免这些漫长的等待时间,我们可能会尽可能排队并重试这些请求。
幂等性很重要,维基百科说:
幂等性是某些操作的属性,它们可以多次使用,而不会改变第一次使用
应用程序的情况和结果。
考虑一个场景,其中某个服务器的请求已处理,但未能回复结果。在这种情况下,客户端会尝试重试相同的操作。如果操作不是幂等的,它将导致整个系统的状态不一致。
模式[3] =回退
优雅地回退
当系统出现故障时,他们可以选择使用其他机制来实现降级响应,而不是
完全失败。
地图服务的案例:使用谷歌地图服务来计算我们的客户从他们的取货位置到目的地的路线路线、估算票价等。我们有一个地图服务,它是我们调用谷歌的所有API接口。最初,我们曾经因为谷歌地图api服务放缓而导致预订创建失败。我们的系统对延迟时间的增加不具有容错性。
我们的解决方案是回退到一个近似路线,当延迟事件启动时,地图服务的系统以这种方式降级模式工作。
在上述情景中的回退有助于我们防止整个系统发生灾难性故障,这些灾难性故障可能会影响我们的关键订票流程。
在所有集成点上考虑回退非常重要。
模式[4] =断路器
断路器以保护您的微服务调用依赖
每个家庭中都使用保险丝或电闸/断路器以防止房屋因为用电量突然激增而被烧毁的。
相同的概念可以应用于分布式系统,当您知道系统不健康并且出现故障并允许其恢复时,应该停止对下游服务进行调用。
典型断路器(CB)上的状态转换如下所示:
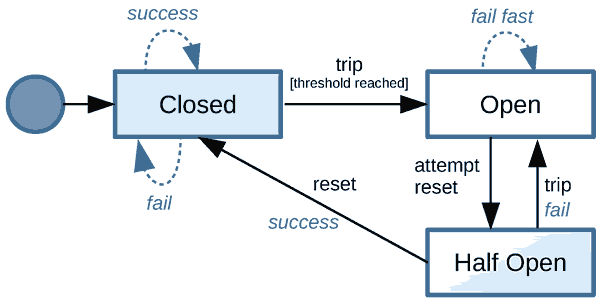
最初当系统健康时,CB处于关闭状态。在这种状态下,它会调用下游服务。当一定数量的请求失败发生时,CB断开电路并进入打开状态。在此状态下,CB停止向失败的下游服务提出请求。经过一定的睡眠 阈值后,CB通过进入半开状态尝试重置。如果此状态下的下一个请求成功,它将进入关闭状态。如果此通话失败,则保持打开状态。
Netflix的 Hystrix是这种模式的流行实现。
集成点需要断路器,有助于防止级联故障。您还可以为断路器添加一个后备电源,以便在断路状态下使用它。
您还需要很好的度量/监控来检测各个集成点上的各种状态转换。Hystrix具有
帮助您可视化状态转换的仪表板。
模式[5] =弹性测试
模拟系统中的各种故障条件非常重要。例如:模拟各种网络故障,网络中的延迟,依赖性缓慢或死亡等。确定各种故障模式后,通过在其周围创建某种测试线束来对其进行编码。这些测试可帮助您对代码的每次更改都执行一些失败模式。
注入故障
将故障注入到系统中是一种有目的地引发故障以测试弹性的技术。
Netflix采用了Chaos Monkey,Latency monkey等工具来支持这种方法。
结论是:
虽然遵循这些模式可以帮助我们实现弹性,但这并非银弹。但是使用这些模式可以提高系统的正常运行时间/可用性。
要有弹性,我们必须:
针对失败的可能设计我们的系统
[该贴被banq于2018-03-27 18:51修改过]