最快的微服务分布式事务?
本文介绍了Adaptive如何在应用层面实现分布式事务,也就是如何在应用服务之间的实现分布式共识算法,这对于微服务的分布式柔性事务有很大参考意义。Adaptive基于此技术研发了高性能、弹性、实时金融交易平台Hydra,号称“实时交易专家”。
这种分布式事务系统的核心是通过确定性执行、复制共识日志以及快照状态等三个方式实现,这样的共识方法好处是简单、易于调试、容错性强和高科伸缩性。
几年前看到LMAX架构,其中Disruptor后来开源了。LMAX让我产生了“应用级别共识”的想法,自从我们在2015年开始探索其潜力以来,我们获益良多,2016年,我们能够做到部署在两套交易系统,其中包括一套金融交易。
LMAX有什么特点?
LMAX是外汇商品和指数的金融交易系统,该系统流程可以实时处理客户的买卖订单。外汇非常不稳定,变化很快,因此交易所需要以非常低的延迟(亚毫秒)处理大量订单 延迟。核心系统是匹配 引擎,负责匹配客户的买入和卖出,匹配引擎是有状态的:它需要保存客户订单直到它们完成匹配或取消。
这种系统面临的挑战是它们具有很强的资源竞争性,但是不适合使用分片来实现并行性或吞吐量:例如, EUR/USD(欧元兑美元) 本身非常不稳定,需要管理这对货币的所有订单在同一个订单book中:你真的不能分片这个问题,怎么解决这个问题呢?
传统方式总是尝试计算是无状态 在应用级别使用某个缓存或数据库中的状态,但这种设计无法解决高吞吐量同时,对低延迟如此苛刻的要求。
什么模型解决了LMAX问题?
LMAX团队尝试了高度竞争的数据库方法和其他各种方法,包括SEDA,Actor模型等,然后他们尝试了一个七十年代和八十年代的想法:状态机复制。 将相同的顺序的消息应用到状态机,因为消息是顺序的,能使得状态修改有效,因为状态机 是确定性的。
所以这就是总体思路:编写匹配的引擎逻辑(业务逻辑),遵循一些简单的规则,确保确定性。然后部署此代码 在网络中的几个节点,再以相同的消息顺序(买 ,卖和 取消订单等)应用于所有节点。
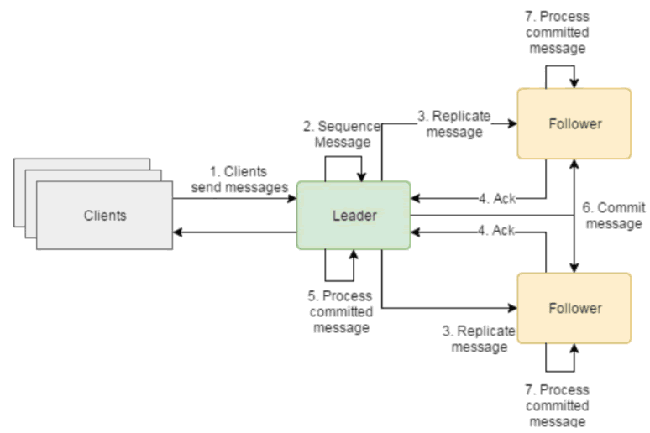
在这个阶段你可能想知道如何你可以构建这个顺序消息?订单来自不同的地方(UI,API等) 因此,一个开箱即用的“单一顺序” 并不存在。 下面是解决之道:
1.放置一个算法来选举一个节点做领导者leader,即主节点。
2. 主节点处理所有传入的消息并对它们进行排序(客户端 群集总是与领导者交谈)。
3. 主节点将顺序复制到从节点。
4. 一旦从节点收到消息就会确认。
5.一旦主节点收到的从节点确认数目符合符合集群总数的法定人数(比如1/2 + 1个),这个消息将被标记为已提交committed,并已准备好由业务处理 逻辑。
6. 主节点还告知从节点已经提交确认committed的消息。
7. 从节点关注者现在可以将消息应用于他们自己的状态机(业务逻辑)。
共识算法
如果你听说过有关共识算法,例如Paxos或Raft算法,刚才上面的LMAX算法也很类似,但是LMAX没有使用Raft。那时该论文尚未发表。
共识算法传统上用于构建分布式数据库或 分布式协调系统(Chubby,Zookeepe r,Etcd,Consul等)。 LMAX案例中有趣的是他们没有使用数据库级别的共识算法 ,而是在应用程序级别共识算法。
由此付出的工程努力通常与设计分布式数据库的研发根本不同,我不认为有很多人都会试图在服务层级别中直接使用共识算法。
共识算法解决了分布式系统中的难题:它们保证即使发生故障,节点故障或网络分区,一组节点也会同意并复制相同的状态。Raft等算法保证了线性化 到集群的客户端(CAP定理的C
),它们也是容错的。 但是需要大多数节点在集群中是可用的,这适合那些将一致性(CAP的C)看得比可用性(CAP的A)更重要的系统,比如同步系统。
开发应用的好处
相比数据库级别共识算法,这种应用级别共识算法在开发应用有哪些好处?
简单
我认为当我实现架构时,最让我感到惊讶的是第一次是这么简单。一旦集群基础设施到位,实现状态机(确定性业务逻辑)非常简单,当然比我用其他方法看到的要简单得多,在我没有 看到另一种设计之前。清晰的分离关注:共识模块和业务逻辑。
这也是一个应用DDD的好环境,我们的交易业务逻辑代码是没有使用任何框架或技术基础设施:简单的旧对象,数据结构和算法,都在一个线程上运行。我们建立的交易交换模型是相当先进的楷模,而且,说实话,我想不出任何其他设计使我们能够满足客户的功能要求和高可用性 。至少肯定没有这么快的上市时间。
一致性
这种架构的一个非常重要的优势是可以获得保证业务逻辑中的状态在节点之间是一致的。
“传统” 系统处理事务的样子:
1. 从客户端收到消息。
2. 从某个存储(数据库,缓存等)加载相应的数据。 3.处理消息,对数据应用一些逻辑并做出决定。
4. 视图提交的新数据到一致性存储,但因为我们正处在一个 分布式系统,其他人(另一个节点,线程等)可能有 在此期间改变了数据,我们需要以某种形式的乐观锁定 或者对数据库进行CAS(比较和交换)操作,才能确保我们不会 覆盖另外一个渠道已经修改的数据。 5.如果CAS失败,我们必须重新加载数据和重试 。
将上述内容与我们在“内部”实现一致算法进行对比:
1.接收客户端消息。
2.对我们已经在内存中的数据应用逻辑(在这种系统中 我们倾向于加载前期最需要我们在运行时的热数据)。
3.由于系统是一致的,因此没有什么需要回退的 所有节点中的状态都相同,直接向客户端确认即可
这种方式取代了需要处理多种可能的故障情况的大量代码,读写数据库都可能发生的错误,会导致脏数据或不一致。
在服务层中实现强一致性的另一个后果是:积极地在业务逻辑中加载所需的所有数据而不用担心,这样可以显着简化外部系统或数据存储区代码,并且产生更好的性能,计算和数据存在于架构不同层中,
不需要数据库
“不需要数据库”可能听起来有争议,其实意思是你并不是真的需要一个具有这种设计的数据库。与大多数共识算法一样,Raft是将系统收到的所有消息存储在集群的每个节点本地:被称为Raft日志。
该日志用于以下几种情况:
1. 如果重新启动群集,则可以将日志应用于所有节点,从而播放系统回到启动前同一状态 - 记住状态机是确定性的,所以 重新应用相同的事件顺序将产生相同的状态。
2. 如果群集中的某个节点出现故障或重新启动,也可以使用该日志: 当它加入时,它可以重放其本地日志,然后查询领导者以检索任何 它可能已经错过了它的消息。
3. 此属性对于解决代码中的错误也非常有用:如果 系统出现故障时,只需要检索Raft日志和本地重放, 相同版本的代码可使用调试器进行调试,这样做,你会 重现生产环境出现的同样问题。任何有高度诊断并发系统经验的人应该了解该方法的显着优势。
4.快照 由于Raft日志可以无限增长,因此它通常与快照结合使用: 系统从Raft日志中的某个的序列号中获取应用程序状态的快照,并将快照存储在磁盘上。然后可以重新启动系统,或者通过加载最新的快照然后应用所有快照来修复失败的节点。
没有“临时”弹性
与其他架构的另一个根本区别在于您如何处理弹性。由于应用程序是基于一致性算法构建的,因此无需考虑弹性。消除了很多复杂性。
确定的业务逻辑
前面提到业务逻辑需要确定,当你以同样顺序两次调用你的业务逻辑时,系统获得的结果应该是相同状态,幂等的。这就意味着你的业务逻辑不应该:
1. 使用系统时间。如果查询系统时间,每次您将获得不同的输出 。时间需要在基础设施中抽象出来并成为Raft日志其中的一部分 。每条消息都由领导者加上时间戳并复制到从节点日志,业务系统应该使用这种逻辑时间而不是系统时间,在系统中“注入”时间也有 副作用:它使得时间相关的代码非常容易测试(你可以快进)。
2. 使用不仔细定义的随机数。如果系统需要生成随机数,你需要确保 所有节点上使用相同种子的随机生成器。 使用当前消息时间(非系统时间!)作为种子。
3. 使用不确定的库。这可能听起来非常严格,但是 记住我们在这里讨论系统的业务逻辑,并且 根据我的经验,普通的旧对象效果很好。
它真的那么容易吗?
简单并不简单 - 一些 在LMAX工作的开发人员说,马丁打破了他们 架构:一旦他们使用它,就很难在任何其他系统上工作 因为太痛苦了。
权衡 请注意,强大的一致性需要付出代价:集群中的所有节点都 参与共识算法并处理系统接收的每条消息。 如果您的系统不需要强大的一致性,可使用“无共享”架构,每个节点处理请求都是独立的。 还要注意,一致性算法至少需要三个节点:你会 需要至少三个进程,在三个不同的服务器上运行,最好是三个,此外,由于消息需要在被发送之前复制到大多数节点提交,节点之间的延迟将直接影响吞吐量,由于这个原因,节点通常部署在同一个地区。
寻找一个名字 我认为这种架构风格适用于许多类别的交易系统(实时 工作流程,RFQ引擎,OMS,匹配引擎,信用检查系统,智能 订购路由器,对冲引擎等),在金融和金融之外也非常适合相关应用。 在某些情况下,与传统应用相比会产生更好的结果。
但当然和任何架构一样,它比其他系统更适合某些系统。
当我与其他人谈论架构时,我们倾向于将其称为“LMAX” 架构,但我认为它值得拥有自己的名字。我还没有找到更好的名字匹配这个“应用层面的共识”架构。
原文PDF
[该贴被banq于2018-09-19 07:46修改过]