优步如何实时根据打车者的要求有效匹配到对应司机?这项挑战算法归为如何收集,存储和逻辑排列数据的问题。
通过预测打车者的需求,能够确保他只要很短的等待时间就能打到车,同时通过考虑流量和其他因素使司机尽可能有效地使用平台。
为了更好地关注我们如何管理构成优步市场的多个系统上的大量实时数据,我们开发了Rider打车会话状态机,这种方法可以模拟构成单个行程的所有数据事件的流程。
我们将每次打车的基础数据称为会话,该会话从用户打开Uber应用程序时开始。该动作触发一系列数据事件,从打车者实际请求乘车时到行程已完成的目的点。由于每个会话都在一段有限的时间内发生,我们可以更轻松地组织相关数据,以便将来进行分析,从而进一步增强我们的服务。在其他功能中,将优步的打车数据分类为会话可以更容易理解和发现问题或引入新功能。
请继续阅读,了解我们如何设计这个新的会话状态机以及所经历的经验教训。
打车会话状态机
我们想要实时捕获和理解的关键信息之一是一个打车开始到结束的完整生命周期,从打车者打开应用程序到他们到达最终目的地的那一刻。但是,考虑到我们系统的复杂性和规模,这些数据分布在多个不同的事件流中。
例如,当有人打开Uber应用程序时,会提示他们选择目标并在用户日志的事件流上触发事件。该应用程序显示该地理区域中可用的产品(uberPOOL,uberX,UberBLACK等)以及由我们的动态定价系统生成的每个产品的价格,每个价格在展示事件流中显示为离散事件。
当打车者选择产品时,请求会进入我们的调度系统,该系统将打车者与驾驶员进行匹配并将他们的车辆分配给到这个新行程。当驾驶员选择了打车者时,他们的应用程序会向调度系统发送“完成取件”事件,从而有效地开始行程。当驾驶员到达目的地并指示乘客已在他们的应用程序中下车时,它会发送“完成行程”事件。
像这样的典型行程生命周期可能跨越六个不同的事件流,由打车者也就是乘客的应用程序、驱动应用程序和优步的后端调度服务器生成事件。这些不同的事件流线程进入一个优步行程。
我们如何将这些事件流置于语境中,以便将它们逻辑地组合在一起,并快速将有用的信息显示给下游数据应用程序?答案在于定义一个有时间限制的状态机,用于建模不同用户和服务器生成的事件流,以完成单个任务。我们将这种由原始操作组成的状态机称为“会话”。
在优步行程生命周期的背景下,会话由一系列事件组成,这些事件从乘客打开他们的应用程序开始到成功完成他们的旅程结束。我们还必须考虑并非所有会话都要经历这一系列完整的事件,因为乘客可能会在提出请求后取消行程或只是打开应用程序来检查票价。由于这些因素,我们必须在会话上强制执行时间窗口。
当乘客打开应用程序时,行程会话开始,在应用程序日志上生成离散事件。当用户浏览其所在位置的优步产品时,我们的行程定价后端系统会向应用提供多次展示,显示每次展示的价格,在会话中启动购物状态。我们可以从应用程序的移动事件流中收集Request Ride状态以请求事件以及Dispatch系统生成的事件流,该事件流记录它收到的所有请求。当驾驶员按下其应用程序上的“Pickup Completed”按钮时,会话将进入On Trip状态。当然,当驾驶员按下应用程序上的“旅行已完成”按钮时,会话结束。
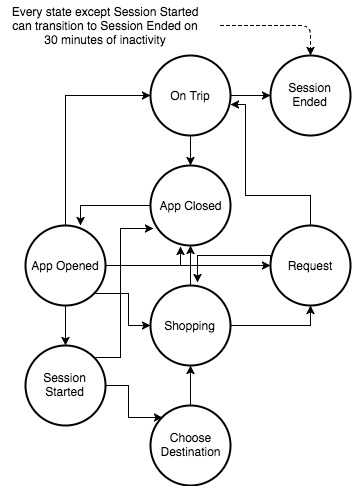
当每个会话模拟物理世界中发生的事件时,我们的打车会话状态机需要具有弹性,旨在应对预期之外的事件。例如,打车者可能在提出请求后取消他们的行程,或者驾驶员的车可能会发生故障或卡在紧急情况相关的交通中,迫使驾驶员取消行程。我们通过允许从Request Ride状态转换回Shopping状态来对这些场景进行建模。
将会话生命周期中的所有相关事件放在一个位置可以解锁各种用例,例如:
- 我们的需求建模团队可以将应用程序展示次数,打开应用程序的人数与实时会话数据进行比较,有助于了解乘客在应用程序中查看特定产品后订购特定产品的概率。
- 我们的预测团队可以在特定时间窗口内查看给定区域内有多少会话处于购物状态,使用该信息预测该区域的需求,从而帮助驾驶员了解他们将来最有可能获得乘客的位置。
生产中实现会话状态机
我们使用Spark Streaming在生产中实现打车会话状态机,因为:
- 我们的许多提取,转换和加载(ETL)管道都是基于Spark构建的,因为优步先前选择的流媒体平台Samza对基于状态的流应用程序(如会话)没有足够的支持。
- Spark Streaming的有状态流应用程序的mapWithState函数被证明是非常通用的,例如提供自动状态到期处理。
ETL管道运行一分钟的微批处理窗口,每天处理几十亿个事件。该管道在我们的YARN集群上运行,使用64个单核容器和8 GB内存。输出以状态转换的形式出现,其中包含相关的压缩原始事件数据。输出发布到Gairos ,我们内部的地理空间时间序列数据系统。
教训
虽然打车会话状态机在理论上似乎很简单,但将它应用于优步的用例却证明是完全不同的野兽。以下是我们在为现有数据流实施此新方法时学到的一些重要经验教训:
- 时钟同步:鉴于各种手机和移动操作系统的变化,更不用说用户设置,您永远不会真正信任从移动客户端发送的时间戳。我们已经看到我们的生产数据中的时钟漂移从几秒到几年。为了解决这个问题,我们决定使用Kafka时间戳,即Kafka收到日志消息的时间。但是,我们的移动客户端缓冲多个日志消息并将它们发送到Kafka的某个有效负载服务器上中,因此许多消息显示相同的Kafka时间戳。我们最终使用Kafka时间戳和每个消息的事件时间戳进行二级排序。
- 检查点稳健性:基于状态的流式传输作业需要定期检查状态到复制文件系统,例如HDFS。该文件系统的延迟可能直接影响作业的性能,特别是如果它经常检查点。单一的检查点故障可能导致灾难性故障,例如整个管道发生故障。
- 检查点恢复和回填:任何分布式系统,特别是设计为在生产中全天候运行的系统,在某些时候必然会失败; 例如,节点将消失,容器可能被YARN抢占,或者上游系统故障可能会影响下游作业。因此,规划检查点恢复和回填至关重要。Spark Streaming检查点恢复的默认行为是在尝试从检查点恢复时,在一个批处理中使用所有积压事件。我们发现,在工作失败和恢复之间的时间很长的情况下,这给我们的系统带来了巨大的压力。我们最终修改了DirectKafkaInputDStream,以便能够在检查点恢复时将积压的事件分成适当的批次。
- 背压和速率限制:Kafka主题的输入速率永远不变。例如,在优步平台上,通勤时间和周末晚上的活动往往会增加。背压对于减轻不堪重负的工作负担至关重要。当批处理所花费的总时间超过微批处理窗口持续时间时,Spark Streaming的背压启动。它使用PID速率估算器来控制后续批次的输入速率。我们注意到估算器的内置默认参数在背压期间产生了大量的振荡和人为的低输入速率,从而影响了数据的新鲜度。在速率估算器中引入合理的底板证明了从背压中更快地恢复的结果。
- 移动日志的保真度:移动客户端发送的事件的保真度可能会有很大差异。在低带宽或弱信号的地方,消息经常丢失或重试并多次发送。由于中间会话功耗较低,客户端可能会脱机,因此状态机应该考虑到这一点。我们意识到,收听由我们相关的后端系统生成的其他事件流有助于确定我们是否从移动客户端获得了有损数据。该经验表明,服务器端系统必须维护自己的事件流。
继续前进
事件顺序处理是一项艰巨的挑战。虽然Spark 2.2中的结构化流媒体原语看起来很有希望处理无序事件,但我们正在考虑转向Flink,因为它更深入支持Uber 的开箱即用事件时间处理和更广泛的支持。此外,我们的一些使用案例可能会使用二级延迟来处理会话数据,这使得Spark的微批次不可行,另一点支持Flink。