架构模块
正如我们已经指出的那样,大多数DDD系统可能会使用OO范例。因此,我们对领域模型的元素可能很熟悉,例如实体,值对象和模块。例如,如果您是Java程序员,那么将DDD实体视为与JPA实体基本相同(使用@Entity注释)就足够安全了。
值对象是字符串,数字和日期之类的东西; 一个模块就是一个包。但是,DDD倾向于更多地强调值对象,而不是过去习惯于强调实体。
虽然您可以使用String类型来保存Customer的givenName属性的值,这可能是合理的,但是一笔钱例如产品的价格呢?也可以使用原始类型int或double,但是(甚至忽略可能的舍入错误)1或1.0是什么意思?$ 1吗?€1?¥1?1美分?
相反,我们应该引入一个Money值类型,它封装了Currency 和任何舍入规则(将特定于Currency)。而且,值对象应该是不可变的,并且应该提供一组无副作用的函数来操作它们。我们应该写成:
Money m1 = new Money("GBP", 10); |
将m2添加到m1不会改变m1,而是返回一个新的Money 对象(由m3引用),它表示一起添加的两个Money。
值也应该具有值语义,这意味着(例如在Java和C#中)它们实现了equals()和hashCode()。它们通常也可以序列化,可以是字节流,也可以是String格式。当我们需要持久保存它们时,会很有用。
值对象常见的另一种情况是标识符。因此,(US)SocialSecurityNumber(美国的社会安全码或身份证号)是一个很好的例子,车辆的车架号也是如此。因此,它一个网址URL。
因为我们已经重写了equals()和hashCode(),所以这些都可以安全地用作哈希映射中的键key。
引入值对象不仅扩展了我们无处不在的语言,还意味着我们可以将行为推向值本身。因此,如果我们认为Money永远不会包含负值,我们可以在Money内部实现此检查,而不是在使用Money的任何地方。如果SocialSecurityNumber具有校验和数字(在某些国家/地区就是这种情况),那么该校验和的验证可以在值对象中。我们可以要求URL验证其格式,返回其方案(例如http),或者确定相对于其他URL的资源位置。
我们的另外两个元素可能需要更少的解释。 实体通常是持久的,通常是可变的并且(因此)倾向于具有一生的状态变化。在许多体系结构中,实体将作为行数据保存在数据库表中。同时,模块(包或命名空间)是确保领域模型保持解耦的关键,并且不会成为一团泥球。埃文斯在他的书中谈到了概念轮廓,一个优雅的短语来描述如何分离领域的主要关注领域。模块是实现这种分离的主要方式,以及确保模块依赖性严格非循环的接口。我们使用诸如Bob Martin大叔的依赖倒置原则之类的技术来确保依赖关系是严格单向的。
实体,值和模块是核心构建元素,但DDD还有一些不太熟悉的构建块。我们现在来看看这些。
聚合和聚合根
如果您精通UML,那么您将记住,它允许我们将两个对象之间的关联建模为简单关联、聚合或使用组合。一个聚合根 (有时简称为AR)是由组合物构成的实体(以及它自己的值)。也就是说,聚合实体仅由根(可能是可传递的)引用,并且可能不被聚合外部的任何对象(永久地)引用。
换句话说,如果实体具有对另一个实体的引用,则引用的实体必须位于同一聚合内,或者是某个其他聚合的根。
许多实体是聚合根,不包含其他实体。对于不可变的实体(相当于数据库中的引用或静态数据)尤其如此。例子可能包括Country,VehicleModel, TaxRate,Category,BOOKTITLE等。
但是,更复杂的可变(事务)实体在建模为聚合时确实会受益,主要是通过减少概念开销。我们不必考虑每个实体,而只考虑聚合根;聚合实体仅仅是聚合的“内部运作”。它们还简化了实体之间的相互作用;我们遵循以下规则:只能将聚合根保存到数据库,而不是聚合中的任何其他实体。
另一个DDD原则是聚合根负责确保聚合实体始终处于有效状态。例如,Order(root)可能包含OrderItem的集合(聚合)。可能存在以下规则:订单发货后,任何OrderItem都无法更新;或者,如果两个OrderItem引用相同的产品并具有相同的运输要求,则它们将合并到同一个OrderItem中。或者,Order的派生totalPrice 属性应该是OrderItem的价格之和。维护这些不变量是聚合根的责任。
但是......只有聚合根才能完全在聚合中维护对象之间的不变量。OrderItem 中引用的产品几乎肯定不会在聚合根AR中,因为还有其他用例需要与Product交互, 而不管是否有订单。所以,如果有,一个规则:不能放入已经停产的产品,那么订单将需要以某种方式解决这个问题。实际上,这通常意味着:在订单更新时 使用隔离级别2或3来“锁定” 产品, 这样保证以事务方式更新。或者,可以使用一种外部协调流程来协调保证聚合不变量不会被破坏。
在我们继续之前退一步,我们可以看到我们有一系列粒度:
value <entity <aggregate <module <有界上下文
现在让我们继续研究一些DDD构建方面的元素。
存储库,工厂和服务
在企业应用程序中,实体通常是持久的,其值表示这些实体的状态。但是,我们如何从持久性存储中获取实体呢?
一个数据库库是在持久存储的抽象,满足某些条件返回实体。例如,Customer 存储库将返回Customer 聚合根实体,订单存储库将返回Order s(及其OrderItem)。通常,每个聚合根有一个存储库。
因为我们通常希望支持持久性存储的多个实现,所以存储库通常由具有不同持久性存储实现的不同实现的接口(例如,CustomerRepository)组成(例如,CustomerRepositoryHibernate或CustomerRepositoryInMemory)。由于此接口返回实体(领域层的一部分),因此接口本身也是领域层的一部分。接口的实现(与特定的持久性实现耦合)是基础结构层的一部分。
通常,我们要搜索的条件隐含在方法名称中。因此,CustomerRepository可能会提供findByLastName(String) 方法来返回具有指定姓氏的Customer实体。或者,我们可以有一个OrderRepository返回Orders,用findByOrderNum(ORDERNUM) 返回匹配ORDERNUM(请注意使用的值类型在这里,顺便!)的订单。
更复杂的设计将标准包装到查询或规范中,例如findBy(Query <T>),其中Query 包含描述标准的抽象语法树。然后,不同的实现解包查询以确定如何以他们自己的特定方式定位满足条件的实体。
也就是说,如果你是.NET开发人员,那么值得一提的是LINQ 。因为LINQ本身是可插拔的,所以我们通常可以使用LINQ编写存储库的单个实现。然后变化的不是存储库实现,而是我们配置LINQ以获取其数据源的方式(例如,针对实体框架或针对内存中的对象库)。
每个聚合根使用特定存储库接口的变体是使用通用存储库,例如Repository <Customer>。这提供了一组通用方法,例如每个实体的findById(int)。当使用Query <T>(例如Query <Customer>)对象来指定条件时,这很有效。对于Java平台,还有一些框架,例如Hades (banq注:Spring data jdbc也支持),它允许混合和匹配方法(从通用实现开始,然后在需要时添加自定义接口)。
存储库不是从持久层引入对象的唯一方法。如果使用对象关系映射(ORM)工具(如Hibernate),我们可以在实体之间导航引用,允许我们透明地遍历图。根据经验,对其他实体的聚合根的引用应该是延迟加载的,而聚合中的聚合实体应该被急切加载。但与ORM一样,期望进行一些调整,以便为最关键的用例获得合适的性能特征。
在大多数设计中,存储库还用于保存新实例,以及更新或删除现有实例。如果底层持久性技术支持它,那么它们很可能存在于通用存储库中,但是从方法签名的角度来看,没有什么可以区分保存新客户和保存新订单。
最后一点......直接创建新的聚合根很少见。相反,它们倾向于由其他聚合根创建。一个订单就是一个很好的例子:它可能是通过调用Customer的一个动作来创建的。
工厂
如果我们要求Order创建一个OrderItem,那么(因为毕竟OrderItem是其聚合的一部分),Order知道要实例化的具体OrderItem类是合理的。实际上,实体知道它需要实例化的同一模块(命名空间或包)中的任何实体的具体类是合理的。
假设客户模块使用Customer的placeOrder操作创建订单(参见图6)。如果客户 知道订单的具体类别,则表示客户模块依赖于订单模块。如果订单具有对客户的反向引用,那么我们将在两个模块之间获得循环依赖。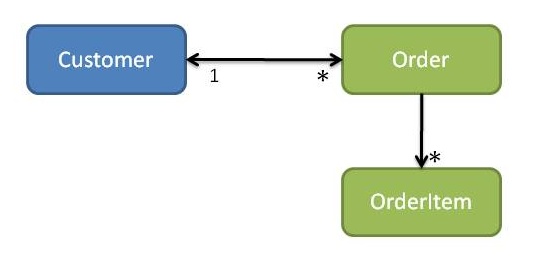
图6:客户和订单(循环依赖)
如前所述,我们可以使用依赖性反转原则来解决这类问题:从订单 - > 客户模块中删除依赖关系,将引入OrderOwner 接口,使Order引用为OrderOwner,并使Customer 实现OrderOwner(参见图7) )。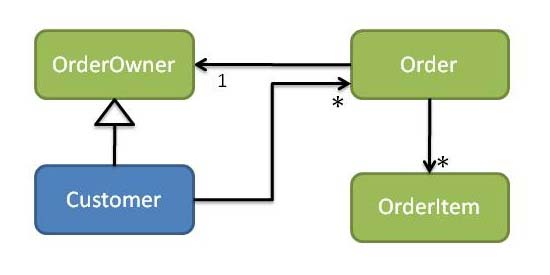
图7:客户和订单(客户取决于订单)
那么另一种方式呢:如果我们想要订单 - > 客户?在这种情况下,需要 在客户模块中有一个表示Order的接口(这是Customer的 placeOrder操作的返回类型)。然后,订单模块将提供订单的实现。由于客户不能依赖订单,因此必须定义OrderFactory接口。然后,订单模块依次提供OrderFactory的实现(参见图8)。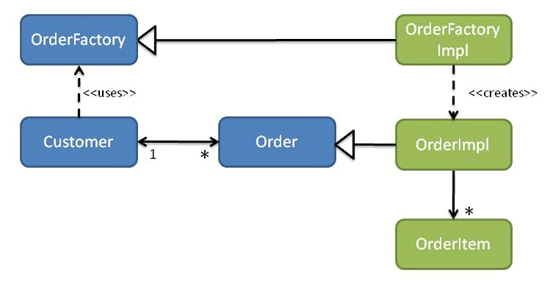
图8:客户和订单(订单取决于客户)
可能还有相应的存储库接口。例如,如果客户可能拥有数千个订单,那么我们可能会删除其订单集合。相反,客户将使用OrderRepository 根据需要定位其订单的(子集)。或者(如某些人所愿),您可以通过将对存储库的调用移动到应用程序体系结构的更高层(例如领域服务或可能是应用程序服务)来避免从实体到存储库的显式依赖性。
实际上,服务是我们需要探索的下一个话题。
领域服务,基础设施服务和应用服务
domain service 是限定在领域层内的,虽然实现可以是基础设施层的一部分。存储库是领域服务,其实现确实在基础结构层中,而工厂也是领域服务,其实现通常在领域层内。特别是在适当的模块中定义了存储库和工厂:CustomerRepository位于客户模块中,依此类推。
更一般地说,领域服务是任何不容易在实体中生存的业务逻辑。埃文斯建议在两个银行账户之间进行转账服务,但我不确定这是最好的例子(我会将转账本身建模为一个实体)。但另一种领域服务是一种充当其他有界上下文的代理。例如,我们可能希望与暴露开放主机服务的General Ledger系统集成。我们可以定义一个公开我们需要的功能的服务,以便我们的应用程序可以将条目发布到总帐Ledger。这些服务有时会定义自己的实体,这些实体可能会持久化; 这些实体实际上影响了在另一个BC中远程保存的显着信息。
我们还可以获得技术性更强的服务,例如发送电子邮件或SMS文本消息,或将Correspondence 实体转换为PDF,或使用条形码标记生成的PDF。接口在领域层中定义,但实现在基础架构层中非常明确。因为这些技术服务的接口通常是根据简单的值类型(而不是实体)来定义的,所以我倾向于使用术语基础结构服务而不是领域服务。但是如果你想成为一个“电子邮件”BC或“SMS”BC的桥梁,你可以想到它们。
虽然领域服务既可以调用领域实体,也可以由领域实体调用,但应用服务位于领域层之上,因此领域层内的实体不能调用领域服务,只能相反。换句话说,应用层(我们的分层架构)可以被认为是一组(无状态)应用服务。
如前所述,应用程序服务通常处理交叉和安全等交叉问题。他们还可以通过以下方式与表现层进行调解:解组入站请求; 使用领域服务(存储库或工厂)获取对与之交互的聚合根的引用; 在该聚合根上调用适当的操作; 并将结果编组回表现层。
我还应该指出,在某些体系结构中,应用程序服务调用基础结构服务。因此,应用服务可以直接调用PdfGenerationService,传递从实体中提取的信息,而不是实体调用PdfGenerationService将其自身转换为PDF 。这不是我特别喜欢的,但它是一种常见的设计。我很快就会谈到这一点。
好的,这完成了我们对主要DDD模式的概述。在Evans 500 +页面书中还有更多内容 - 值得一读 - 但我接下来要做的是强调人们似乎很难应用DDD的一些领域。
以上翻译自methodsandtools.com
百度网盘PDF下载