JVM可能是一个复杂的野兽。值得庆幸的是,大部分复杂性都在幕后,我们作为应用程序开发人员和部署人员通常不必过于担心。随着基于容器的部署策略的兴起,需要引起注意的一个复杂领域是JVM的内存占用。
两种内存
JVM将其内存分为两大类:堆内存和非堆内存。堆内存是人们通常最熟悉的部分。它是存储由应用程序创建的对象的位置。它们一直存在,直到它们不再被引用并被垃圾收集。通常,应用程序使用的堆量将根据当前负载而波动。
JVM的非堆内存分为几个不同的区域。我们可以使用HotSpot VM的本机内存跟踪(NMT)来检查这些区域的内存使用情况。请注意,虽然NMT不跟踪所有原生本机Native内存使用情况(例如,它不跟踪第三方本机代码内存分配),但对于大类典型的Spring应用程序来说已经足够了。可以通过启动应用程序-XX:NativeMemoryTracking=summary然后使用jcmd <pid> VM.native_memory summary来显示内存使用情况摘要来使用NMT 。
让我们通过查看应用程序来说明NMT的使用,在这种情况下,我们的老朋友Petclinic。下面的饼图显示了当使用48MB最大堆(-Xmx48M)启动Petclinic时由NMT报告的JVM的内存使用量(减去其自身的开销):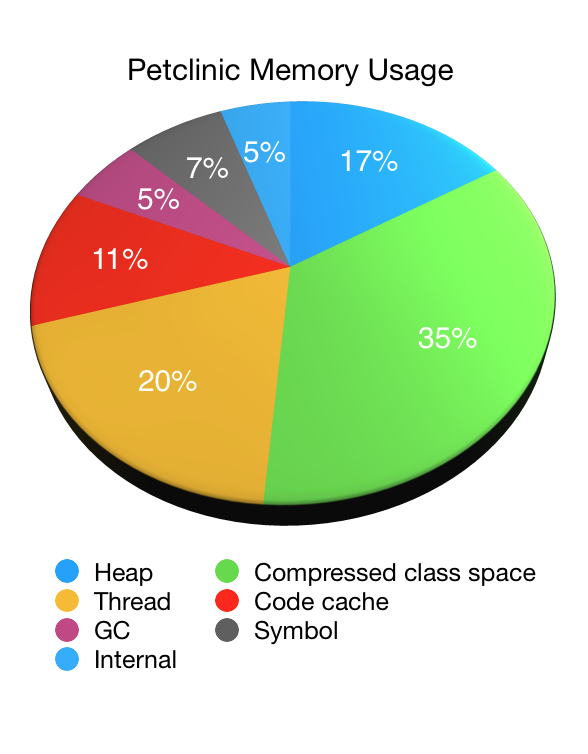
正如您所看到的,非堆内存占绝大多数JVM的内存使用量,堆内存仅占总数的六分之一。在这种情况下,大约44MB(垃圾收集后立即使用33MB)。非堆内存使用总量为223MB。
本机Native内存区域
- 压缩类空间:用于存储有关已加载的类的信息。受到约束MaxMetaspaceSize。已加载的类数的函数。
- 线程:JVM中线程使用的内存。正在运行的线程数的函数。
- 代码缓存:JIT用于存储其输出的内存。已加载的类数的函数。受到约束ReservedCodeCacheSize。可以通过调整JIT来减少,例如,禁用分层编译。
- GC:存储GC使用的数据。根据使用的垃圾收集器而有所不同。
- 符号:存储符号,如字段名称,方法签名和实习字符串。过多的符号内存使用情况可能表明字符串过于激进。
- 内部:存储不适合任何其他区域的其他内部数据。
非堆内存与堆内存的不同
与堆内存相比,非堆内存在负载下不太可能发生变化。一旦应用程序加载了它将使用的所有类并且JIT完全预热,事情就会陷入稳定状态。要查看压缩类空间使用量的减少,加载类的类加载器需要进行垃圾回收。在将应用程序部署到servlet容器或应用程序服务器时,这种情况更常见 - 应用程序的类加载器将在取消部署应用程序时进行垃圾收集 - 但现代应用程序部署方法很少发生。
调整JVM的大小
配置JVM以有效利用给定数量的可用RAM并不容易。如果您启动JVM -Xmx16M并期望它最多可以使用16MB的RAM,那么您会感到非常惊讶。
调整JVM大小的一个有趣的方面是JIT的代码缓存。默认情况下,HotSpot JVM最多可使用240MB。如果代码缓存太小,JIT将耗尽空间来存储其输出,因此性能将受到影响。如果缓存太大,可能会浪费内存。在调整代码缓存大小时,查看应用程序内存使用情况及其性能的影响非常重要。
在Docker容器中运行时,Java的最新版本现在知道容器的内存限制并尝试相应地调整JVM的大小。不幸的是,这种大小调整经常过度分配非堆内存并且分配不足。假设您有一个在具有2个CPU和512MB可用内存的容器中运行的应用程序。您希望它能够处理更多负载,因此您将CPU加倍为4,将内存加倍至1GB。如上所述,堆使用通常根据负载而变化,而非堆使用则更少。因此,我们希望将大部分额外的512MB内存提供给堆来应对增加的负载。不幸的是,JVM默认情况下不会这样做,并且会在其堆和非堆区域之间更均等地分配额外的内存。
值得庆幸的是,CloudFoundry团队拥有丰富的JVM内存占用知识。如果您要将应用程序推送到CloudFoundry,构建包将自动为您应用此知识。如果您没有使用CloudFoudry,或者您想了解有关如何调整JVM大小的更多信息,那么Java buildpack内存计算器第三版的[url=https://docs.google.com/document/d/1vlXBiwRIjwiVcbvUGYMrxx2Aw1RVAtxq3iuZ3UK2vXA/edit?usp=sharing]设计文档[/url]提供了一些强烈建议的进一步阅读。
这对Spring来说意味着什么?
考虑到堆和非堆内存使用情况,我们花了很多时间在Spring团队中考虑性能和内存利用率。限制非堆内存使用的一种方法是使Framework的一部分尽可能通用。这方面的一个例子是使用反射来创建应用程序的bean并将其注入到应用程序的bean中。由于使用了反射,所使用的Framework代码量保持不变,无论应用程序包含多少bean。我们使用基于堆的缓存来优化启动时间,一旦启动完成就清除此缓存。然后,垃圾收集器可以轻松地回收堆内存,从而在应用程序处理其工作负载时为应用程序提供尽可能多的内存。