Plaid的API可帮助开发人员为北美数以千万计的消费者提供金融服务。这些服务帮助消费者管理他们的个人财务,让他们转移资金和付款,并允许他们获得贷款和抵押贷款。我们的使命是通过提供对金融系统的访问来改善人们的生活。
我们不仅通过帮助消费者访问其财务数据,而且通过提高数据质量来实现这一使命。通过机器学习丰富数据是我们数据科学和基础设施团队的目标之一,在这篇文章中,我们还将讨论我们团队建立的ML模型。
交易的待处理和已过账(pending-posted)的难题
Plaid为传统银行的交易数据增加价值的一种方法是确定何时发布来自消费者账户的待处理交易。当银行正在处理消费者的交易时,交易正在等待银行处理状态中,在这个待处理期间,钞票金额将从帐户所有者的可用资金中扣除,但不会从帐户余额中扣除。等交易结束后,交易才从“待处理pending”变为“已过账posted”,已过账posted的交易最终会完成,并且已从该帐户余额中扣除。
当Plaid拍摄帐户快照时,我们会收到一份包含说明、货币金额以及交易状态是待处理还是已过帐的交易清单。虽然我们知道交易是否处于待处理状态,但银行通常不会告诉我们先前快照中的哪些待处理交易与当前快照中的新发布交易相对应。这种匹配对客户至关重要。如果他们向每个新交易的消费者发送通知,那么重要的是他们不要接受到重复复通知。
不幸的是,通常不清楚银行的哪些已发布的交易事务映射匹配到先前消费组在商家的待处理的交易事务?一个常见的困难匹配问题是餐馆账单,当消费者的信用卡在餐馆收取账单时,餐厅会启动待处理的交易,它不包括服务费和小费。一旦餐厅的收据被批量处理(通常在工作日结束时),他们通过在一个统一事务中来完成交易,这是事务交易成为已过账posted状态的时候。
在其他情况下,相应的待处理和已过帐的交易可能看起来不同。酒店通常会将较高的待处理pending费用作为暂缓incidental费用的帐户。一旦交易过帐,即可结算到实际的账单金额。商家,支付处理商和金融机构均可以更改这项交易的描述。
我们针对此问题的高级方法是构建一个模型来预测这种可能性或匹配分数:来自银行和消费组的两笔的待处理和已过账的交易是否是同一笔?如果待处理的事务从一个帐户快照到下一个帐户快照时消失,我们会将其与新快照上显示的“最有可能”的已发布交易进行匹配。当匹配得分高于某个阈值时,贪婪地继续匹配。
问题的关键是选择一个模型来确定这个匹配分数。
决策树算法
为了解决这个问题,我们最初考虑的规则会告诉我们一个特定的待处理和已发布交易的匹配程度。以下是匹配餐馆发起的待处理和已发布交易的示例规则的直观表示: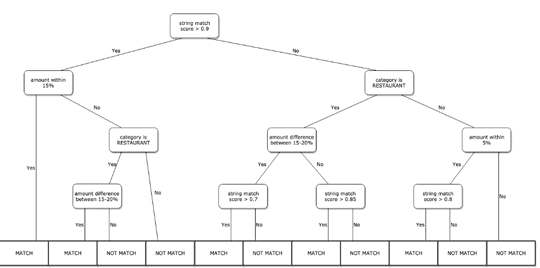
这种基于规则的方法称为决策树,它对独立变量的空间进行分段,如有关事务的信息,并尝试查找可能与匹配事务相对应的此空间区域。虽然上述可视化中的决策树输出布尔预测,但决策树通常用于更强大的机器学习,包括在我们的模型中,而是输出可能性的预测。
用于训练决策树的算法,在实践中很少使用独立树。这是因为他们倾向于学习训练数据背后的噪声而不是数据中的基础关系。决策树可能错误地了解了无关紧要的交易描述,因为很多相互不匹配的事务却具有相似的交易描述。此问题称为过度拟合。
过度拟合
过多的模型复杂性导致过度拟合,因为它允许模型扭曲到训练数据。
过度拟合被称为“高方差”,因为过度拟合模型强烈依赖于训练数据,输入的微小变化将导致预测的大的变化。
另一方面,变量不足和模型复杂性不足导致欠拟合,其中模型太不灵活,无法在训练数据中找到有意义的关系。欠拟合被称为“高偏差”,因为欠配合模型具有显着的系统预测误差或偏差。
数据科学的一个基本挑战是偏差 - 方差权衡。不小心增加模型复杂性会导致更高的方差和更低的偏差。如果我们的模型完全基于偏差测量(例如训练集的准确度)进行优化,那么它们将倾向于过度拟合。
Bagging
为了解决待发布的匹配问题而不过度拟合,我们的第一个模型使用bagging装袋和feature 特征采样增强了决策树的概念。让我们先来讨论bagging,这是指bootstrap aggregating。
“Bootstrapping”是在训练数据的随机样本上训练模型的过程。通过限制训练过程中使用的数据量,bootstrapping 通过在训练期间提供不同的噪声分布来对抗过度拟合。
“Aggregating”是组合许多不同引导模型的过程。对于bootstrapping 树,聚合过程通常通过计算树预测的可能性的平均值来对树“投票”。由于训练子集是随机采样的,因此决策树仍然平均适合数据集,但投票给出了更稳健的预测。
结合Bootstrapping和Aggregating结果进行bagging装袋。
如果组件模型不相关,则bagging装袋模型会更多地减少差异。然而,仅对不同的训练数据样本进行Bootstrapping通常会导致树具有高度相关的预测,因为最具信息性的分支规则在采样的训练数据中通常是相似的。例如,由于交易描述是未处理和已过程交易是否匹配的强有力指标,因此我们的大多数树木将严重依赖此指标。在这种情况下,bagging装袋的能力有限,可以减少整体模型的差异。
这是特征抽样的来源。
随机森林
为了减少树的相关性,我们的模型除了随机抽样训练数据外,还随机抽样特征,产生随机森林。作为数据科学家工具包的主要成分,随机森林是具有低过度拟合风险,高性能和高易用性的强大预测因子。
这是Plaid多年来用于匹配待处理和已发布交易的模型。随着时间的推移,这种方法被证明是有效的,但并不是很好:当我们根据人类标记数据评估模型时,我们注意到了高假阴性率。我们需要改进模型,以便更可靠地找到匹配项。
当随机森林失败时
随机森林和一般的bagging装袋易受不合适的不平衡数据集的影响。我们对从待处理pending到已过账posted匹配的随机森林模型遇到了这个问题。由于每个待处理交易在训练集中最多只有一个已发布的事务,因此大多数待处理和已过账交易的候选对都不匹配。这意味着我们的训练集存在不平衡,其中绝大多数数据“不匹配”; 因此,我们的随机森林模型错误地预测了较低的匹配概率,从而导致较高的假阴性率。
Boosting
为了解决这个问题,我们使用了boost。Boosting将决策树限制为简单形式 - 例如,树不是很深 - 以减少整体模型的偏差。增强算法迭代地探索训练数据,添加最大限度地改善聚合模型的受限树。与bagging装袋一样,树的投票决定最终的决定。
从这个过程我们最终了解到,改善少数情况下的性能 - 匹配的交易对 - 将最大化模型提升。该算法深入研究了识别该情况的条件,通过精心调整的超参数,我们终于看到了我们的假阴性率的重大改进。
boosting的另一个优点是能够在训练期间灵活地定义“模型改进”度量。通过对误报和漏报分配不对称惩罚,我们训练了一个模型,更加符合这些模型错误如何不对称地影响消费者。
结果
与随机森林模型相比,我们新的增强模型将假阴性率降低了96%,最终为我们的客户和消费者提供了更高质量的交易数据。除了内部指标改进之外,我们还看到客户提交的有关待处理到期交易票据显着减少。
必须了解机器学习模型原型的特征如何导致不同的优点和缺点。虽然我们的新模型在我们提供的数据质量方面取得了重大进步,但它还是有自己的权衡。Boosting对模型改进度量以及限制树必须简单的其他超参数敏感。在这种情况下,改善的消费者体验非常值得仔细的培训程序和细致的调整。
还有更多我们还没有探索。例如,考虑到我们使用大量的分类变量,哪种提升算法最好?鉴于我们每天有四分之一的美国人使用银行账户处理交易多次,我们如何确保我们的匹配算法足够快以便跟上?鉴于难以解释和解释其输出背后的推理,深度神经网络对于这个问题是否值得投资?