这是一篇EventSourcing/CQRS实现的教程文章,从原理模式到具体技术产品选型都阐述得比较详细。以下是架构图:
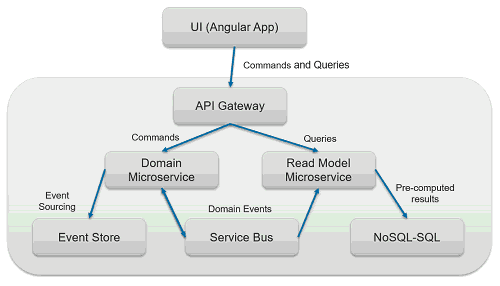
这里简单介绍一下这个架构的工作原理:
- UI应用程序(例如Angular应用程序)通过Http向API网关发出请求。
- 该请求是“命令”或“查询”。
- 命令将传递给Domain Microservice,它只接受命令。Domain Microservice根本不接受查询。
- Domain Microservice接收命令,将事件保留在内存中,并将事件发送到Event Store数据库。
- Domain Microservice还会将这些事件发布到Service Bus。
- 由于Read Model Microservice对此事件感兴趣,因此它将被订阅此事件,因此它将通过服务总线接收此事件,并更新其非规范化数据的版本并准备好进行查询。
- 如果请求是“查询”,它将被发送到读取模型微服务。
Domain Service里面的细节:
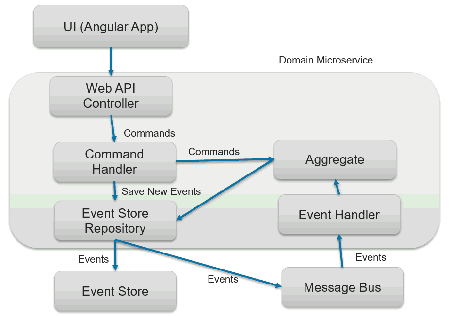
以下是Domain Microservice中的简单事件流:
- Web API Controller仅接受命令,当它获得命令时,它只是转发给命令处理程序。
- 然后,Command Handler会将命令发送到Aggregate以运行与该命令相关的业务逻辑。
- 完成后,将通知命令处理程序聚合操作已完成,并且已准备好保留事件。
- 然后,事件将通过存储库持久保存到Event Store,同样的事件也将发布到Service Bus以供其他服务使用。
两阶段提交
这里我们可以将消息保留到事件存储但消息总线消息发布失败,现在,我们需要做的就是识别失败,然后返回事件存储并重放将发布消息的消息.
设计模式和组件
以下模式和组件仅支持分布式和松散耦合系统的思想。
- CQRS模式:命令和查询责任分离
使用CQRS Pattern,我们的想法是将查询和命令视为两个独立的问题来处理,因此在我们的代码中,我们将查询和命令发送到不同的路径来处理它们。
仅凭这个定义,如果你在一个服务中同时拥有命令和查询,它对我们的微服务实现没有任何帮助,因为它是服务中发生的内部,但是如果我们想要分离命令和查询两个不同的微服务,一个服务处理查询,另一个处理命令,然后如果我们使用这个模式,分离将非常简单,因为理论上查询和命令应该有单独的代码路径。
- 事件溯源模式
使用Event Sourcing Pattern,我们的想法是不在数据存储中保存对象的最终状态,而是使用这种“仅不断追加事件”的方法,我们只将事件记录为事件流中的序列,每次我们想知道对象的当前状态是什么,我们从事件流的开头开始,重新播放执行它们,并找出最终状态。
老实说,这种模式是一种很好的模式,在构建微服务时很有用,但我仍然不完全理解,这有助于我们构建分布式解耦应用程序。
有人建议,我们将这些事件放在Event Store中,如果其他微服务需要这些对象的状态,他们可以查看这些事件流并找出对象的状态,而无需转到得到它的原始服务。这对我来说又是另一个单点故障,在Monolit单点系统中,我们都是这样查询共享表来找出状态的,而现在我们都查询事件存储库?
无论如何,我认为在这一点上我认为宁愿使用服务总线(接下来解释)并让每个服务访问他们自己的数据存储中所需的数据(即使是重复数据)。
Service Bus是Microservices实现中非常重要的一部分,这是我们将使用Publisher和Subscriber模型在Microservices之间进行异步通信的工具。使用此发布者和订阅者模型迫使我们采用最终一致性范例。
- 乐观并发
当转向微服务时,我们不应过多担心并发性,因为很多东西都是异步的,类似于两阶段提交情况。我们应该尝试构建工作流,如果由于并发而出现问题,我们可以反向执行。
- 域驱动设计(DDD):将微服务与域上下文对齐
DDD是一个古老的主题。如果您还没有阅读“蓝皮书”,我建议您这样做,因为这是围绕这一主题的最着名的书。
基本上,DDD和一些称为“ 事件溯源 ”的技术在微服务方面有所帮助,它有助于我们了解一个服务的结束位置以及其他服务的启动位置。它基本上有助于我们根据业务能力了解我们的服务,并帮助我们了解每项服务的界限。
DDD和Event Sourcing也将帮助我们构建一种名为“ Ubiquitous Language ”的语言,这种语言是开发人员和用户之间的一种通用、严谨的语言。
- NoSQL:读模型
如前所述,事件溯源被大多数书籍推荐为在我们的系统中存储事件的模式(由我们的CQRS模式的命令路径处理)。现在这对于查询目的而言将非常缓慢,因此建议使用“ 读取模型 ”,它本质上是我们数据的模型。但出于性能原因,建议使用NoSQL或内存缓存作为微服务中的“读取模型”。
- API网关:针对UI进行了优化
在单体架构中,UI部分很简单。但在微服务中,UI需要对不同的服务进行多次调用,并收集数据并将其组合在一起呈现给用户。这也是我们在身份验证和授权方面的“可信子系统”边界。
要解决此问题,可以使用不同的工具来处理多个调用并聚合数据(就像它是Monolth一样)。
API Gateway和GraphQL是用于解决此问题的两种技术。但对我而言,这个API网关或GraphQL将是瓶颈和故障的单点,它必须改变并与微服务中的所有变化同步。我还不清楚这实际上是不是一件好事!
另一方面,如果你没有这个层,并让你的UI直接与你的微服务交谈,那么无论何时你移动微服务,或者你拆分它,那么你需要不断更改UI,这也不行!
- 版本控制:API,数据库
在微服务中,我们需要提前考虑版本控制,因为事情会发生变化,我们需要能够正确处理它们。
需要的软件和库
在语言和框架方面,使用C#和Asp.Net Web API,以下是我用于此实现的软件和nuget包库。
1. Redis
我将使用Redis作为我们的Read Model和NoSQL Storage。它非常易于安装和配置。
就Nuget包而言,为了与C#中的Redis交互,我使用StackExchange.Redis nuget包作为Redis客户端。
2. RabitMQ
对于我们的“消息总线”组件,我将使用RabitMQ。它是一个非常着名,广泛使用的开源消息代理,它是配置方面最简单的一个。
注意:Azure Service Bus是另一种选择,如果您计划将Microsoft Azure用作云基础架构,则可能是更好的选择。
对于与RabbitMQ交互的Nuget库,我使用EasyNetQ库作为RabbitMQ客户端,为我们的目的提供了非常好的API。
3. EventStore
EventStore作为一个工具,在为他们的工具拿起一个名字方面做得非常好......事实证明它是一个Event Store!
我将使用它作为我们的事件存储,以保持我们的Domain Microservice使用的事件历史记录。
我们为什么要使用Event Store?
我们使用的任何事件存储都有自己的一套特性和功能,但是当涉及到将事件存储用作微服务中的数据存储时,有一个主要原因:
无需处理“两阶段提交”。
想象一下,如果我们不使用Event Store,而使用常规SQL数据库以及Service Bus来发布要订阅的其他服务的事件。在这种情况下,我们需要正确处理“2阶段提交”情况。
如果您在某些数据库表中保存了一些记录,然后尝试将相关事件发布到Service Bus,那么您怎么办?现在你必须使用“ 指数补偿Exponential backoff ”算法重试一段时间(这会导致系统延迟正确传播事件),如果你最后没有成功发布事件,你必须回滚您对数据库所做的更改。
我们可以使用常规数据库吗?
简短回答是,如果数据库具有Publisher Subscriber功能。
可以为我们提供Pub / Sub功能以及常规存储的最着名的NoSQL数据库是Redis。
我们可以使用没有Pub / Sub功能的数据库吗?
答案是肯定的,但是你需要有一种跨越数据库事务的“ 补偿事务交易 ”,并向服务总线发布消息,只有当两个操作都成功时才完成交易。虽然它不会是一个原子操作,却可以工作,但是你可以想象,如果我们能够在没有事务的情况下做到这一点,那么效率会更高。
来自维基百科:
如果事务是长期存在的(通常称为Saga事务),例如在需要用户输入的业务过程中,也使用补偿事务。在这种情况下,数据将被提交到永久存储,但随后可能需要回滚,可能是由于用户选择取消操作。
使我们使用Redis,我们仍然需要一个Redis事务,我们只是将两个操作(1.向Redis添加数据2.发布一个事件)放在事务范围内。
Azure Service Bus的原子事务
以下内容来自Azure Service Bus Github页面,该页面解释了补偿或Saga事务当前支持的内容:
Azure Service Bus当前不支持通过MS DTC或其他事务协调器登记到分布式两阶段提交事务,因此您无法在同一事务范围内对SQL Server或Azure SQL DB和Service Bus执行操作。
Azure Service Bus支持.NET Framework事务,它将易失参与者置于事务范围内。因此,一组服务总线操作是否会生效可以取决于独立登记的并行本地工作的结果。
使用事件溯源是原子的Atomic
使用Event Store,我们不需要担心补偿或Saga事务,因为我们正在做的只有一件事,即将事件追加保存到事件存储中,因此无论如何它都是原子操作,因此根本不需要事务处理。
使用事件溯源的任何其他原因?
嗯,是的,Event Stores提供的一些功能非常有用:
- 准确的审计跟踪
当我们在事件存储中单独记录每个事件时,通过查看流,很明显每个流的历史记录是什么,以及为什么我们处于当前状态。
我们不能用SQL做到这一点吗?是的,我们可以使用自定义实现或SQL CDC(更改数据捕获)来执行完全相同的操作,但Event Store可以更轻松地完成此操作。
嗯,是的,Event Stores提供的一些功能非常有用:
- 准确的审计跟踪当我们在事件存储中单独记录每个事件时,通过查看流,很明显每个流的历史记录是什么,以及为什么我们处于当前状态。我们不能用SQL做到这一点吗?是的,我们可以使用自定义实现或SQL CDC(更改数据捕获)来执行完全相同的操作,但Event Store可以更轻松地完成此操作。
- 易于进行时间查询因为我们为每个业务对象保留完整的事件跟踪,所以很容易查询过去并知道过去任何时候该对象的状态。
我们不能用SQL做到这一点吗?是的,我们可以,但使用Event Stores实现此类查询要容易得多。
我们需要Event Store和Service Bus吗?
简短的回答是否定的。但是,如果您已经在您的微服务的常规数据库和发布消息到服务总线之间实施了适当的Saga或补偿事务处理,并且您没有查询时态数据或非常准确的审计日志跟踪的要求,并且您不关心您的历史数据中的内容会发生变化,您只需使用服务总线,就不需要事件存储。
为什么要将事件发布到Event Store和Service Bus?
你不必这样做,如果您的服务有一些要求,使用事件存储是一个很好的选择,然后同时你的系统中有一些其他服务,不需要事件存储,他们只是使用服务总线和他们有自己的本地SQL数据库,所以在这种情况下,您将事件发布到Event Store以使用Event Store的服务,然后将另一个事件发布到Service Bus以获取不使用Event Store,仅使用Service的服务总线和常规SQL或NoSQL数据库。
我们可以一起跳过Event Sourcing吗?
简短的回答是肯定的,但只有当你考虑了它的所有好处和用例并且你没有任何这些要求时,你也已经为跨服务交易处理实施了适当的“Saga”。
根据我的经验,在大多数企业软件中都有完全适合Event Sourcing提供的业务需求,所以我猜你最终可能会使用Event Store或者使用常规SQL或NoSQL数据库自己实现类似的东西。
财务组件系统是第一个被认为适合使用Event Stores的组件。
使用Event Sourcing来解决所有微服务的问题?
使用事件源需要考虑的因素,如报告,较少的社区支持或与常规数据源相比较不成熟的工具,与人们习惯的相比较尴尬的查询等。
所以考虑到这一点,我不认为企业架构中的每一个微服务都需要使用事件源,就像软件工程中的任何其他模式一样,我们应该务实,只需使用最有意义的工具和模式。
回到微服务的定义,我们的想法是每个服务或团队将决定以最有效的方式提供业务需求最有意义的东西,我相信在特定的微服务中使用或不使用事件源是类似的需要由团队根据业务需求做出的决定。
点击标题查看原文系列,可以在github上找到完整的代码