如果说“软件正在吞噬世界”,那么“数据就是新的石油”。那些能够最好地管理海量数据的人将脱颖而出。精炼这种油的最先进方法是流加工。在这篇文章中,我想描述什么是流处理,以及为什么在当今时代有必要进行流处理。
过去的好时光
将数据从一个位置移动到另一位置的需求可能与存储本身一样古老。这称为Extract-Transform-Load(简称ETL)。
在计算、提取、转换、加载过程中,是将数据从一个或多个源复制到目标系统的通用过程,该目标系统表示将来源不同的数据或在与来源不同的上下文中的数据表现出来。ETL流程在1970年代成为流行的概念,并经常用于数据仓库。
当我开始我的职业生涯时,运行ETL流程的唯一模式是批处理作业(或批处理)。我相信在撰写本文时,它仍然是主要的模式,这要归功于(或由于)此类工作的巨大遗产仍使银行运转。通常,计划将批次按固定的时间间隔自动运行,例如,每天午夜,每月或每年。有时,它们被触发:守护进程监视一个文件夹,并且当该文件夹包含与特定模式匹配的文件时,该批处理将被触发-并对这些文件进行处理。
以下是一些批处理示例:
1. 数据仓库
根据几种“形式”,对SQL数据库进行了规范化。其中一种形式要求将数据复制到专用表中,而不是将重复数据复制到不同的行中,并通过主键-外键关系进行引用。这种方法的缺点是,对多个表进行查询需要联接,而联接会减慢查询的执行速度。拥有大量数据,这可能导致无法接受的等待时间。因此,数据仓库存储未规范化的数据。
每月(或每周)批处理将标准化数据从生产数据库中提取出来,对其进行非标准化以进行快速查询,然后将其加载到数据仓库数据存储中。
2. 银行账户
最初,银行是通过邮寄每月发送其帐户状态的邮件。随着互联网的普及,他们开始允许用户以数字形式访问账单。但是,出于安全原因,访问权限并未授予其内部存储,而是授予了面向公众的只读数据库。
每日批处理将所有交易数据以及相关数据从内部数据库复制到前端客户数据库。
批处理模型的限制
如上所述,“数据就是新的石油”。数据获取的速度呈指数级增长并非神秘。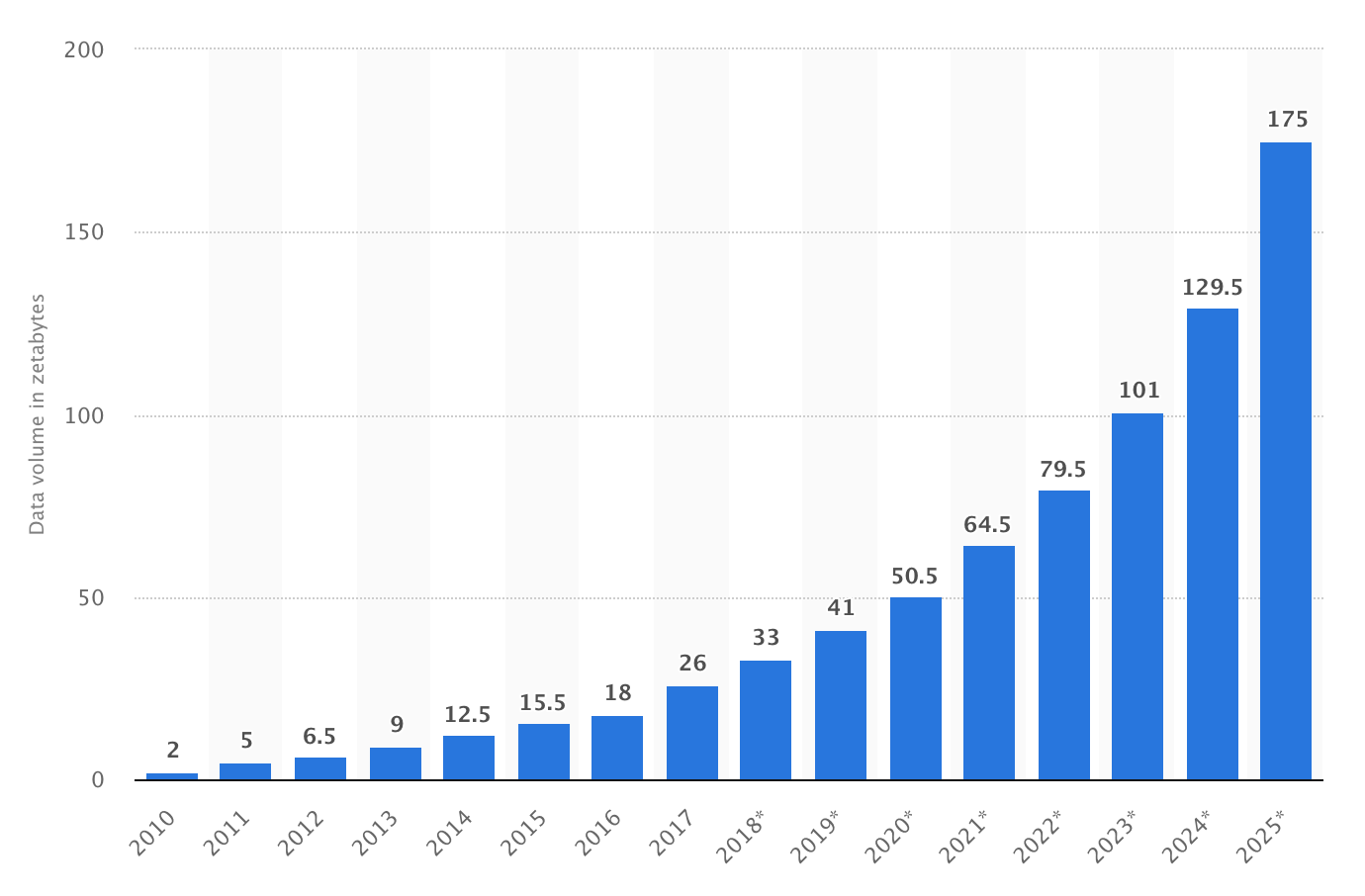
图1.在全球范围内创建的数据(请参阅https://bit.ly/2OF5MY2)
当需要处理的数据量也开始增长时,批处理的问题就会显现出来。
- 当需要将存储在数据库中的数据加载到内存中时,将触发第一个问题。如果数据量不足以容纳在内存中,则批处理将失败。通常,这由ETL软件处理,该软件基本上只加载块中的数据,并保留块的开始和结束。
- 如果批次需要在每个X周期运行,并且比X花费更多的时间,则会发生第二个问题。因此,该模型变得无关紧要。我已经在职业生涯中见过好几次了,而且我相信我还远非唯一。没有真正的解决方法。通常,人们开始购买性能更高的硬件,但迟早会达到其极限。
- 最后,如果在批处理运行之前需要数据可用怎么办?如果一个月运行一次,则在月底肯定可以使用所有数据。但是,需要等待一个月才能访问这些数据。尽管这可能适用于上面的银行帐户用例,但其他用例可能更希望尽快获取不完整的数据。本质上,批处理是定期运行的,并且为了获得可用性而权衡完整性。
流模型
流式传输争夺权衡,并在数据可用后立即进行处理。用户可以选择等到这段时间过去,或者根据不完整的数据在任何时候做出决定。该方法的基础是,现在不完整的数据要好于后来的完整数据。
流数据是由不同来源连续生成的数据。此类数据应使用流处理技术进行增量处理,而不能访问所有数据。另外,应该考虑的是概念漂移可能发生在数据中,这意味着流的属性可能会随时间而变化。
流处理是一种查看数据以及如何处理数据的新方法。