大约一年前,我们的工作流程团队开始开发跨业务多个领域的新应用。我们面临着一个有趣的挑战:是从头开始构建应用程序的核心,同时还需要使用许多不同系统中存在的数据。
我们需要的一些数据点,例如有关电影,制作日期,员工和拍摄地点的数据,分布在实现各种协议的许多服务中:gRPC,JSON API,GraphQL等。现有数据对于我们应用程序的行为和业务逻辑至关重要。我们从一开始就需要高度集成。
可切换的数据源
将可见性引入我们产品的早期应用程序之一是作为单体构建的。单体架构允许快速开发和快速更改。某一时刻,有30多个开发人员正在使用它,并且它具有300多个数据库表。
随着时间的流逝,应用程序从广泛的服务产品演变为高度专业化的产品。这导致决定将单体分解为特定的服务。该决定并非针对性能问题,而是针对所有这些不同领域设置了界限,并使专门团队能够独立开发针对特定领域的服务。
单体仍然提供了我们为新应用所需的大量数据,但我们知道单体将在某个时候分解。我们不确定分手的时间,但是我们知道分手是不可避免的,我们需要做好准备。
因此,我们一开始可以利用来自单体的某些数据,因为它们仍然是真实的来源,但要准备将这些数据源在联机后立即交换给新的微服务
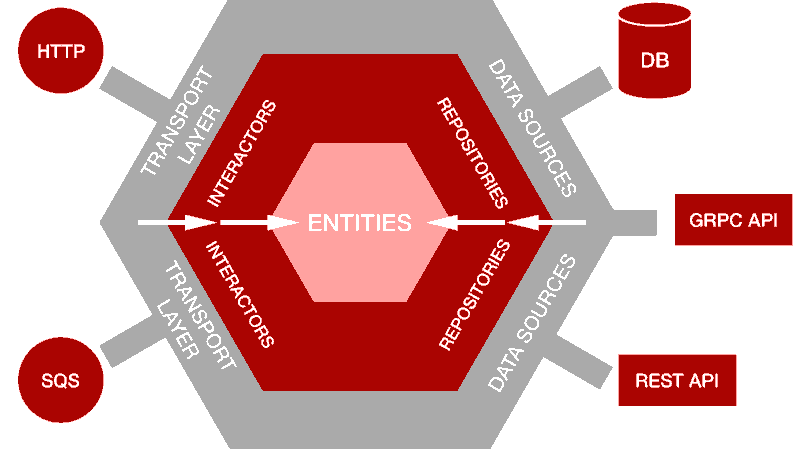
利用六角形架构
在不影响业务逻辑的情况下我们还需要支持交换数据源的能力,因此需要将这两者分离。我们决定根据Hexagonal Architecture和Bob叔叔的Clean Architecture背后的原理来构建我们的应用程序。
六边形架构思想是将输入和输出置于我们设计的边缘。业务逻辑不应该依赖于我们公开REST还是GraphQL API,也不应该依赖于我们从何处获取数据,不依赖于数据库,通过gRPC或REST公开的微服务API,或者仅仅是一个简单的CSV文件。
该模式使我们能够将应用程序的核心逻辑与外界的关注隔离开。将我们的核心逻辑隔离开意味着我们可以轻松更改数据源详细信息,而不会造成重大影响或无需将主要代码重写为代码库。
在具有清晰边界的应用程序中,我们还看到的主要优势之一是测试策略-我们的大多数测试都可以验证我们的业务逻辑,而无需依赖易于更改的协议。
定义核心概念
借鉴六边形/六角形结构,定义业务逻辑的三个主要概念是实体,存储库和交互器。
- 实体是领域对象(例如电影或拍摄地点),它们不知道它们自己的存储位置(与Ruby on Rails或Java Persistence API中的Active Record不同)。
- 存储库是获取实体以及创建和更改实体的接口。它们保留用于与数据源通信并返回单个实体或实体列表的方法列表。(例如UserRepository)
- 交互器是用于编排和执行领域操作的类-考虑服务对象或用例对象。他们实施特定于领域操作的复杂业务规则和验证逻辑(例如,入职生产)
使用这三种主要类型的对象,我们可以定义业务逻辑,而无需任何知识或关心数据保存在何处以及如何触发业务逻辑。业务逻辑之外是数据源和传输层:
- 数据源是不同存储实现的适配器。数据源可能是SQL数据库的适配器(Rails中的Active Record类或Java中的JPA),弹性搜索适配器,REST API,甚至是诸如CSV文件或Hash之类的简单适配器。数据源实现在存储库上定义的方法,并存储获取和推送数据的实现。
- 传输层可以触发交互器执行业务逻辑。我们将其视为系统的输入。微服务最常见的传输层是HTTP API层和一组处理请求的控制器。通过将业务逻辑提取到交互器中,我们不会耦合到特定的传输层或控制器实现。交互器不仅可以由控制器触发,还可以由事件,cron作业或命令行触发。
使用传统的分层体系结构,我们将使所有依赖项指向一个方向,上面的每一层都取决于下面的层。传输层将取决于交互程序,交互程序将取决于持久层。
在“六角体系结构”中,所有依赖点都向内指向-我们的核心业务逻辑对传输层或数据源一无所知。传输层仍然知道如何使用交互器,数据源知道如何符合存储库接口。
这样,我们就可以为其他Studio系统的不可避免的更改做好准备,并且只要需要进行更改,就很容易完成交换数据源的任务。
切换数据源
交换数据源的需求比我们预期的要早:我们突然遇到了一个单体的读取限制,并且需要将某个实体的特定读取切换到在GraphQL聚合层上公开的较新的微服务。微服务和单体保持同步,并且从一个服务或另一个服务读取的数据相同,产生的结果相同。
我们设法在2小时内将读取数据从JSON API传输到GraphQL数据源。
我们之所以能够如此快地完成它,主要原因是六角结构(通过适当的抽象,就很容易更改数据源)。我们没有让任何持久性细节泄漏到我们的业务逻辑中。我们创建了一个实现存储库接口的GraphQL数据源。一个简单的单行(one-line)变化是所有我们需要开始从不同的数据源读取。
此时,我们知道六角建筑已经为我们发挥作用了。
单行更改的很大一部分在于,它可以减轻发布风险。如果下游微服务在初始部署时失败,则回滚非常容易。这也使我们能够分离部署和激活,因为我们可以决定通过配置使用哪个数据源。
隐藏数据源详细信息
该体系结构的一大优势是我们能够封装数据源实现细节。我们遇到了这样一种情况:我们需要一个尚不存在的API调用-服务具有一个API来获取单个资源,但没有实现批量获取。与提供API的团队进行交流后,我们意识到此端点需要一些时间才能交付。因此,我们决定在构建此端点的同时,提出另一种解决方案来解决该问题。
我们定义了一个存储库方法,该方法可以在给定多个记录标识符的情况下获取多个资源-并且该方法在数据源上的初始实现向下游服务发送了多个并发调用。我们知道这是一个临时解决方案,数据源实现的第二个要点是在实现后使用批量API。
这样的设计使我们能够继续满足业务需求,而不会产生太多技术债务,也无需事后更改任何业务逻辑。因为我们的业务逻辑不需要了解特定的数据源限制。
测试策略
当我们开始尝试六角结构时,我们知道我们需要提出一种测试策略。我们知道,要获得高速发展的先决条件就是拥有可靠且超快速的测试套件。我们认为它不是一个很好的选择,而是必须具备的。
我们决定在三个不同的层次上测试我们的应用程序:
- 测试我们的交互器,我们的业务逻辑的核心生活在其中,但与任何类型的持久性或传输无关。我们利用依赖注入并模拟任何类型的存储库交互。这是对我们的业务逻辑进行详细测试的地方,而这些正是我们力求进行的大部分测试。
- 测试数据源,以确定它们是否与其他服务正确集成,它们是否符合存储库接口,并检查它们在出现错误时的行为。我们尝试最小化这些测试的数量。
- 我们具有集成规范,遍及整个堆栈,从我们的Transport / API层到交互器,存储库,数据源以及重要的下游服务。这些规格测试了我们是否正确“布线”了一切。如果数据源是外部API,我们将命中该端点并记录响应(并将其存储在git中),从而使我们的测试套件可以在每次后续调用时快速运行。我们不会在这一层进行广泛的测试,通常每个域操作只有一个成功方案和一个失败方案。
我们不测试存储库,因为它们是数据源实现的简单接口,并且我们很少测试实体,因为它们是定义了属性的普通对象。我们测试实体是否具有其他方法(不涉及持久层)。
与可以轻松在任何机器上运行的测试套件一起工作非常好,并且我们的开发团队可以在不中断的情况下处理其日常功能。
延迟决策
在将数据源切换到不同的微服务时,我们处于非常有利的位置。关键好处之一是,我们可以延迟有关是否以及如何存储应用程序内部数据的某些决定。根据功能的用例,我们甚至可以灵活地确定数据存储的类型-是关系型还是文档型。
鲍伯叔叔说得很好:
好的架构的目的是延迟决策。为什么?因为当我们推迟做出决定时,我们需要更多的信息来做出决定。
在项目开始时,关于我们正在构建的系统的信息量最少。我们不应该将自己锁定在一个不知情的决定而导致项目悖论的体系结构中。
我们现在做出的决定对我们的需求很有意义,并且使我们能够快速行动。六角结构的最好之处在于,它可以使我们的应用程序灵活地适应将来的需求。