在外部系统之一不可用的情况下进行事件重新处理是我们业务流程的重要组成部分。希望有这样一个重试机制:如果任何外部系统暂时不可用,该应用程序可以让我们重新处理消息。
卡夫卡之前
在项目的早期,我们使用IBM MQ进行异步消息传递。如果在服务操作期间发生任何错误,则可以将接收到的消息放入死信队列(DLQ)中,以进行进一步的手动处理。DLQ是在传入队列旁边创建的,消息移动是在IBM MQ内部完成的。
如果错误是暂时的,我们可以判断它,回调战略将生效。不管应用程序逻辑的分支如何,原始消息都将移至系统队列以进行延迟发送,或移至曾经用于重新发送消息的单独应用程序。在这种情况下,重发号码将写入消息头,该消息头在应用程序级别链接到延迟间隔或策略的末尾。如果我们已完成策略的最后阶段,但外部系统仍然不可用,则该消息将放置在DLQ中以进行手动分析。
寻找解决方案
在Internet上可以找到解决方案。长话短说,建议为每个延迟间隔创建一个主题(如创建5m重试主题、30M重试主题或1小时重试主题),在应用程序端的Consumers上进行延迟读取(每隔5M读取一次),它将以必要的延迟读取消息。
尽管有很多积极的反馈意见,但对于我们的团队来说似乎并不好。首先,因为除了执行业务需求之外,我们还必须花费大量时间来执行所描述的机制。
此外,如果Kafka集群包含访问控制,则您将不得不花费一些时间来创建主题并提供对它们的访问权限。除此之外,您将需要为每个相关主题选择正确的参数remaining.ms,以便可以重新发送消息且消息不会消失。必须对每个现有或新服务重复执行和访问请求。
spring-kafka问题
让我们看看有什么机制可以重新处理消息,特别是spring-kafka。Spring-kafka依赖于spring-retry的传递依赖,该依赖关系为管理不同的BackOffPolicy提供了抽象。它非常灵活,但是它的主要缺点是它将消息重新存储在应用程序内存中。这意味着由于操作过程中的更新或错误而重新启动应用程序将导致丢失所有等待再次处理的消息。由于这一点对我们的系统至关重要,因此我们不再作进一步考虑。
spring-kafka本身提供了ContainerAwareErrorHandler的几种实现,例如SeekToCurrentErrorHandler,通过它们您可以延迟处理消息,而不会在发生错误的情况下进行偏移量继续偏移。从spring-kafka 2.3开始,现在可以指定BackOffPolicy。
这种方法允许重新处理的消息期间容忍应用程序的重新启动,但是仍然缺少DLQ机制。我们在2019年初选择了此选项,乐观地认为将不需要DLQ。但是临时错误触发了SeekToCurrentErrorHandler。其余错误已记录下来,导致偏移还是提交,并且还是继续处理之后消息。
最终的解决方案
基于SeekToCurrentErrorHandler的实现促使我们开发了自己的重新发送消息的机制。
首先,我们想利用已有的经验,并根据应用程序逻辑对其进行扩展。对于具有线性逻辑的应用程序,最好在回调策略指定的短时间内停止读取新消息。对于其余的应用程序,我们希望有一个要点,以确保实施了重新处理策略。此外,这两种方法的这一点都应具有DLQ功能。
重新处理策略本身应存储在应用程序中,该应用程序负责在发生时间错误时获取下一个间隔。
消费者停止使用线性逻辑应用程序
使用spring-kafka时,用于停止Consumer的代码可能如下所示:
public void pauseListenerContainer(MessageListenerContainer listenerContainer, |
在示例中,retryAt是重新启动MessageListenerContainer的时间(如果它仍然可以工作)。重新启动将在TaskScheduler中运行的单独线程中发生,该实现也由spring提供。
我们通过以下方式找到retryAt的值:
- 我们正在寻找重试计数器的值。
- 根据该计数器值,搜索后处理策略中的当前延迟间隔。该策略以JSON格式在应用程序中宣布。
- 在JSON数组中找到的间隔包含秒数,在此秒数之后,我们将需要重复处理。该秒数将添加到当前时间,从而形成retryAt的值。
- 如果未找到间隔,则retryAt的值为null,并将消息发送到DLQ进行手动处理。
使用这种方法,仅需要将当前正在处理的每个消息的重复调用次数存储在例如应用程序内存中。对于这种方法,将重试计数器保存在内存中并不很重要,因为具有线性逻辑的应用程序无法一次性线性处理。与spring-retry相反,重新启动应用程序不会导致丢失所有要重新处理的消息。
这种方法有助于减轻外部系统的负载,外部系统可能由于重负载可能无法使用。换句话说,除了重新处理之外,我们还需要实现断路器模式。
在我们的例子中,错误阈值仅为1。为了最大程度地减少由于网络临时故障而导致的系统停机时间,我们使用间隔时间短的非常精细的重调用策略。这可能不适用于所有应用程序,因此应根据系统要求选择错误阈值和间隔值之间的比率。
一个单独的应用程序:用于处理来自不确定逻辑的消息
这是将消息发送到这样的应用程序(重试器)的代码,当达到RETRY_AT时间时,该消息再次将其发送到DESTINATION主题:
public <K, V> void retry(ConsumerRecord<K, V> record, |
RETRY_AT的值与通过使用者停止进行重复的机制相同。除了DESTINATION和RETRY_AT,我们还发送:
- GROUP_ID,我们将其分组以进行手动分析和简化搜索。
- ORIGINAL_PARTITION尝试保存相同的使用者以进行重新处理。此参数可以为null,在这种情况下,新分区将通过原始消息的record.key()获得。
- 更新了COUNTER值以遵循重新处理策略。
- SEND_TO是一个常数,它指示在到达RETRY_AT时将其发送以进行重新处理还是将其放入DLQ中。
- 原因-消息处理被中断的原因。
重试器将消息保存以在PostgreSQL中重新发送和手动处理。计时器启动一个任务,该任务使用RETRY_AT查找消息,然后使用record.key()将它们发送回DESTINATION主题的ORIGINAL_PARTITION。
发送后,消息将从PostgreSQL中删除。消息的手动分析是在一个简单的UI中执行的,该UI通过REST API与Retryer进行通信。它的主要功能是转发或删除DLQ中的消息,查看错误信息以及搜索消息(例如,按错误名称)。
由于在我们的集群上启用了访问控制,因此有必要另外请求对该主题的访问,该主题将侦听Retryer,并允许Retryer写入DESTINATION top。这很不方便,但是与间隔主题的方法相反,我们有完整的DLQ和UI来管理它。
在某些情况下,多个应用程序实现不同逻辑的不同使用者组将读取传入的主题。通过Retryer对一个应用程序的消息重复处理将导致另一个应用程序的消息重复。为了防止这种情况,我们创建了一个单独的retry-topic 主题进行重新处理。同一个消费者可以读取传入input topic的和操作retry-topic消息,而没有任何限制。
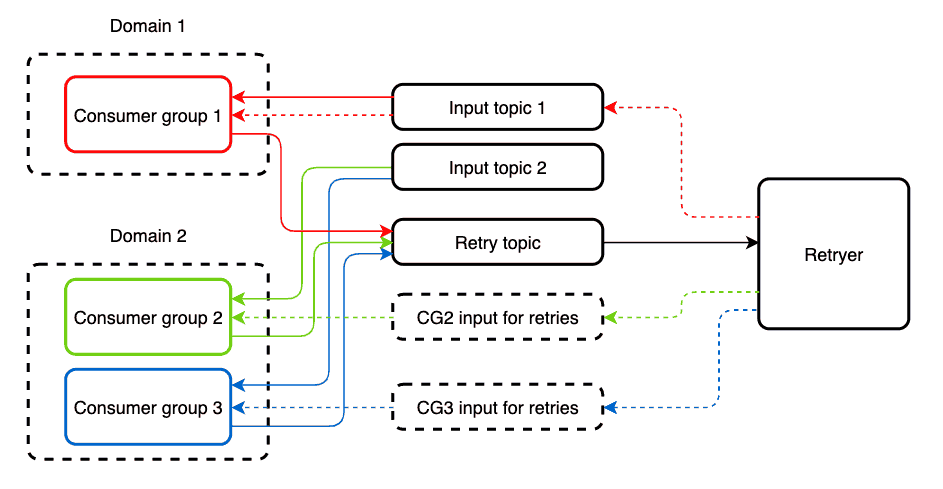
默认情况下,此方法不提供断路器功能,但是可以使用spring-cloud-netflix或新的spring cloud断路器将其添加到应用程序中,从而将外部服务的调用位置包装到适当的抽象中。另外,可以选择策略bulkhead模式,这也很有用。例如,在spring-cloud-netflix中,它可能是线程池或信号灯
结论
结果,我们有了一个单独的应用程序,如果任何外部系统暂时不可用,该应用程序可以让我们重新处理消息。
该应用程序的主要优点之一是,它可以由运行在同一Kafka群集上的外部系统使用,而无需对其进行大量修改!这样的应用程序仅需要访问retry-topic,填写一些Kafka标头并将消息发送到Retryer消费者。无需添加任何其他基础结构。为了减少从应用程序传输到Retryer并返回的消息数量,我们使用线性逻辑隔离了应用程序,并通过使用方停止对它们进行了重新处理。