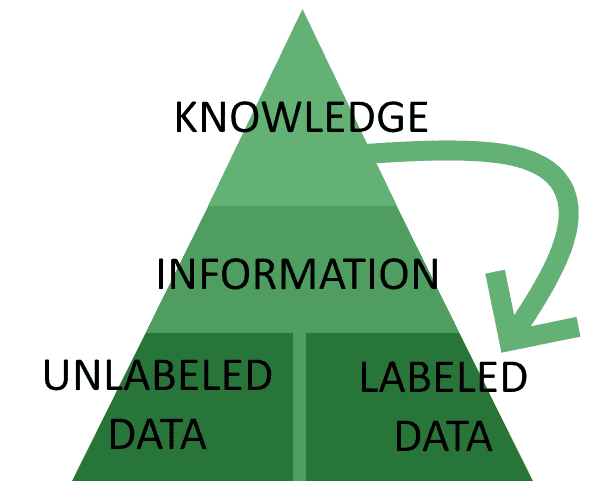
用于开发AI系统的传统体系结构涉及数据,信息和知识之间的区别,以及它们随后的层次结构排列:
这种结构通常称为“ 知识金字塔 ”或“ DIK金字塔”,其中首字母缩写词代表其组成部分的首字母。尽管这种理论方法受到了广泛的批评,但仍被普遍用作AI系统开发的共享概念参考。
在此模型中,我们设想一个AI系统通过将数据聚合为信息来理解世界,然后处理信息以提取知识,然后使用该知识指导后续的数据收集。
现在让我们进一步将此模型分解为其基础组件。
数据
金字塔的最底层包含数据,这是将机器学习系统连接到现实的基础。我们可以将数据解释为由传感器执行的测量或观察的集合,这些传感器具有原始或清晰表达的形式。
数据示例为:
- 包含数字的矩阵
- 文字串
- 类别值列表
- 采样音频
在此上下文中,“数据”对应于数据结构中包含的一个或多个值。稍后我们将看到如何进一步区分本文所讨论的两类数据。
信息
下一步是数据汇总,可以多种方式聚合数据,以便从中提取模式。模式对应于数据分布的规律性,可以通过在其上施加数学或统计模型来进行检索。
与数据中的规律性相对应的模式或方案通常被称为“信息”。
信息比原始数据具有更好的总结外部现实复杂性的能力,这就是为什么我们将其置于金字塔的更高层次。另一种看待同一想法的方法是说,信息,数据的方案或模式允许人们对未来的测量结果进行预测,而数据本身则不行。
知识
一旦从一组数据中提取了模式,就可以将其用于预测由于系统行为而产生的世界的未来状态。
知识对应于世界运转方式的先验假设(banq注:类似函数的输入条件、第一性原则、公理、前提条件、上下文)。反过来,这个假设塑造了我们对已经执行或尚未执行的测量的期望。当我们或机器学习系统进行数据收集时,我们可以使用该知识先验地预测我们将检索的数据的某些特征。这些特征来自于我们对世界或其运作方式的常识。在那种情况下,我们可以说我们从我们的知识中得出了假设数据具有的某些特征。
标记数据与未标记数据
我们也可以用贝叶斯术语表达这种想法。通过说明传感器和测量特性的知识,可以完全确信所收集的数据将至少具有与其他类似情况下所收集的那些特征相同的特征。然后,该知识将未标记的数据(即传感器接收到的原始数据)转换为由相关的先验知识形成的数据:
假设我们要使用卷积神经网络对两类图片进行分类。还可以说这些类别是“猫”和“狗”。我们向CNN展示的图片包含隐式假设,对应于先验知识,即它们属于“猫”类还是“狗”类。(banq注:假设它不是猫就是狗,不可能是第三个动物)
从机器学习系统的角度来看,换句话说,该假设可以表述为:“在这个世界上,我拥有的传感器为我提供了属于两个类别之一的数据”。因此,机器学习系统具有 对于任何给定图像的先验知识或信念。
对于任何给定图像的先验知识或信念。
这不一定是世界的运行方式,但必然是如何建立隐含在该机器学习系统中的世界表示的。从某种意义上讲,这就是我们在本文中提出的想法,所有数据都是未标记的数据。只有我们对它的先验知识的分配才能将该数据变成标记数据。
我们已经讨论了根据世界知识和贝叶斯先验区分标记数据和未标记数据的理论基础。
1. 未标记的数据是唯一存在的纯数据。如果打开传感器,或者睁开眼睛,不了解环境或世界运转方式,那么我们将收集未标记的数据。
2. 标记数据是需要事先了解世界运作方式的数据。人工或自动标记者必须使用他们的先验知识在数据上加上其他信息。但是,在执行的测量中不存在此知识。
标记数据的典型示例是:
- 猫或狗的图片,带有相关标签“猫”或“狗”
- 产品评论的文字描述,以及用户对该产品的评分
- 待售房屋的特征及其售价
我们根据该先验得出的所有结论与该先验的有效性一样有效。这就是为什么正确标记是准备数据集中至关重要的重要步骤的原因。
何时使用标记数据和未标记数据
标记数据和未标记数据之间的区别很重要。这是因为,一件事情可能有不同的事情,而另一件事情则不可能。特别是,我们可以使用某些机器学习算法来处理带标签的数据,而另一些可以使用未标记的数据。
根据某些标准,我们最终将为工作选择一种数据类型。这些标准是:
- 任务类型
- 任务的目的
- 数据的可用性
- 进行标记所需的一般知识与专业知识的水平
- 决策功能的复杂性
带标签的数据允许执行回归和分类任务,该任务属于监督学习任务的类别。
未标记的数据允许执行聚类和降维任务,这些任务属于无监督学习类别。
更详细讨论点击标题见原文