六角体系结构是实现域驱动设计时要使用的关键设计模式。它支持不断变化的变化,有助于保持测试套件的快速和可靠,并保护系统免受技术问题引起的连锁反应的影响。这一系列博客文章探讨了它的起源和益处,以及五种可能的实现方式及其各自的特征。
为什么要进行域驱动设计?
将业务逻辑与系统的其余部分分离的想法并不是什么新鲜事:至少从1970年代就开始将关注点分离为设计原则。作为创建模块化的,可组合的计算机程序的一种方式。而且,由于业务可以说是一个独特的问题,可以与其他事务(例如安全性或网络)清楚地区分开来,因此我们应该能够找到在实现代码中封装,抽象和保护它的方法,这是合乎逻辑的。
传统方法:分层架构
为了使域与技术问题分开,Evans建议实现包含以下四个层的分层体系结构:
- 表示层(UI,视图,图形交互)
- 应用程序层(又称为服务层,包含API和“job”)
- 域层(又称业务层)
- 基础结构层(持久性,消息传递,体系结构框架)
各个层根据彼此之间的相互依赖关系而相互堆叠:每个层都只能依赖于自身以及下面的层。这是为了允许模块化和可更改性。
分层体系结构的某些方面仍然仍然是潜在的问题:
- 依赖关系只能指向下,但是即使向下的依赖关系也要承担责任。例如,在分层样式中,数据库结构的更改几乎可以肯定会导致整个堆栈的重新部署:业务层取决于它,应用程序层取决于业务层和数据库,GUI取决于应用程序层–我们将此称为“ 涟漪效应”。
- 由于数据库位于堆栈的底部,并且对其进行更改会带来重大后果(并非最不重要的是很大的成本),因此我们倾向于首先设计数据库,并防止其设计过于频繁地更改。因此,数据建模(尤其是关系数据建模)会无意间塑造并告知(有时不自觉地)我们对业务对象结构的思考。在最坏的情况下,这最终可能导致所述业务对象的设计模仿规范化关系数据库的设计。它可能会导致劣等的,有时甚至是有害的体系结构决策,从而对整个系统产生负面影响。一些示例是通过数据所有权对分布式系统进行分区,这导致了“ Distributed Monolith ”反模式,而可怕的是“规范数据模型。”
- 一旦决定使用特定的数据库技术,就很难替换。尽管对象关系映射器(例如Hibernate)可能允许我们在测试过程中将内存数据库(h2)交换为生产db(MariaDB集群),但仍需要运行的数据库-测试速度大大降低。因此,转换用于持续生产的技术模型成为一项重大工作,可能需要数周,数月甚至数年的时间才能实现。由于性能要求的变化,网络限制或法规的变更(从SQL到NoSQL,或者基于内存或基于文件的存储),这可能比人们想象的要早。
进入六边形架构
2005年,阿利斯泰尔·科伯恩(Alistair Cockburn)发行了他称之为“ 六角形架构”(又名“端口和适配器”模式)的原始版本。阿利斯泰尔(Alistair)以前曾出版过有关编写有效用例的书,他的问题是查找分散在系统中的业务代码-以及分层体系结构的影响:
“多年来,软件应用程序的一大缺陷是业务逻辑渗透到用户界面代码中。这引起的问题有三个方面: |
首先,无法使用自动化测试套件对系统进行完整的测试,因为需要测试的部分逻辑依赖于经常变化的视觉细节,例如字段大小和按钮位置;
出于完全相同的原因,不可能从人工驱动的系统转换为批处理运行的系统。
出于同样的原因,当程序变得有吸引力时,很难或不可能允许该程序由另一个程序驱动。
在许多组织中反复尝试的解决方案是在体系结构中创建一个新层,并保证这次确实,确实没有将业务逻辑放入新层中。但是,由于没有机制来检测何时发生违反该承诺的情况,该组织发现几年后新层被业务逻辑弄得乱七八糟,旧问题又出现了。” |
他还发现GUI和应用程序另一部分之间的对称性,它对应于基础结构层:
“通常在应用程序的“另一侧”存在一个有趣的类似问题,其中应用程序逻辑与外部数据库或其他服务绑定在一起。当数据库服务器出现故障或进行大量返工或更换时,程序员无法工作,因为他们的工作与数据库的存在紧密相关。这会导致延误成本,并常常导致人们之间的不良感受。 |
Alistair的解决方案非常简单,它非常简单:他提议完全放弃层的概念,而是通过“端口”将应用程序的核心(业务)暴露给所有外部问题,即适合每个单独目的的公共API 。任意数量的“ 适配器 ”都可以连接到它们,并且可以作为一个整体无缝地工作,而使核心本身不了解技术细节和外部零件的确切性质。此逻辑都可以被应用到他所谓的“左侧”的应用程序的:通过GUI中使用的“驱动”,或事件处理端口,批处理机制或远程连接的荷兰国际集团的应用,例如ERP系统;包括“右侧”:即“驱动”端口,用于连接持久性,消息传递和远程控制ed应用程序。
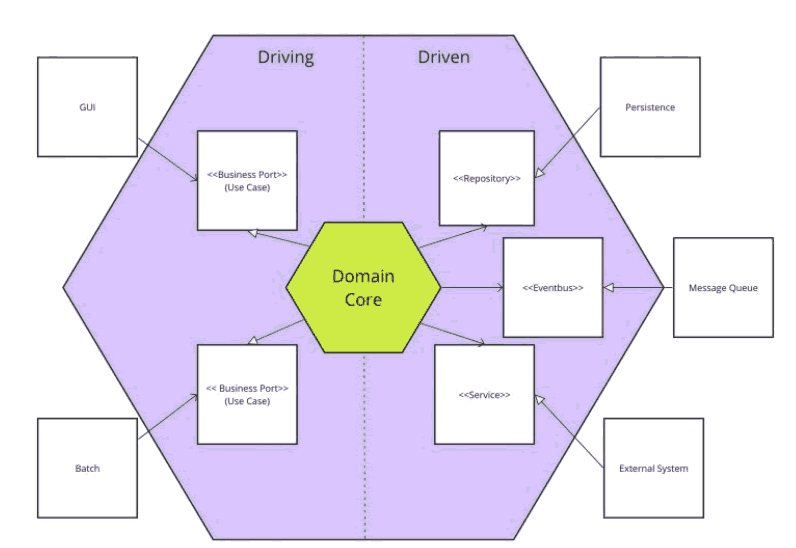
注意:外部适配器取决于内核提供的协议/接口。左侧是驱动适配器使用的接口,右侧是从动适配器实现的接口。所有依赖项都向内指向,因此核心本身可以完全忽略其周围环境。
即使Alistair可能没有考虑域驱动设计,但是当他提出模式(本文中没有提到)时,毫无疑问它是一个完美的选择:它保留了分离的初衷令人担忧的问题–而且,与分层方法相比,它对业务进行了更为严格的分离–并且它解决了上一节中列出的分层体系结构的所有问题。此外,其技术不可知的性质还允许它以多种方式实施,根据目标产品的规模和整体/分布式性质提供多种选择。
在本系列博客文章的其余部分中,我们将探索和比较一些可能的实现及其各自的优缺点。
网上商店
如何证明大规模实施模式的效果,该模式随时间推移显示其真实价值?
我的答案是:通过显示演化变化的几个阶段,从简单到复杂,从整体到分布式,从关系数据存储到事件源。当您从“让它开始工作”过渡到“我们无法满足需求,而我们迫切需要对用户的需求进行深入了解时,这种变化自然会发生在起义业务中我们的产品组合具有吸引力。”
案例场景是我们都应该非常熟悉的场景:我们的小型初创公司有一个在线商店,上面有产品目录,用户可以从中将商品添加到购物车中(或从中删除),最终将其结帐并变成订单。幸运的是,这家商店已经获得了很大的吸引力,我们希望尽快扩大规模。目前,我们有两个前端应用程序:商店GUI(用于客户)和管理GUI(用于管理产品并跟踪未完成的购物车和订单)。
我们已经考虑过许可ERP系统,该系统可能会用标准的物流平台代替我们的产品管理应用程序,同样,我们可能会连接到外部服务以向我们提供GTIN产品代码。但是目前,这些只是要牢记的想法。
我们已经完成了一个EventStorming研讨会:
该域实际上只有一个带有标题“购物车”的有界上下文,以及两个相邻的上下文,它们仅使用CRUD逻辑:“产品”(主要是主数据的源)和“订单”(我们在其中使用的存储桶)存储我们的最终产品。跨上下文边界只有一个过渡,其中将购物车签出并转换为订单。共有三个业务规则(策略),它们都与购物车和订单的生命周期有关,并且我们已经确定了一个问题,我们希望确保仅将商品添加到购物车中(如果它们引用的是实际存在的产品)在目录中(过去,人们在浏览器中单击缓存的项目时会遇到问题,由于可用性问题,导致无法履行订单)。
设计实现步骤:
- 模块化整体式:这是我们的出发点和最初的战术设计。
- 共享内核“微服务”:我们将域核心保留为单个库,但是更改了部署模型。
- 微服务,“真正的”:我们将域核心分为无共享组件。
- CQRS:我们将API分为与写入和读取相关的组件,以实现更好的扩展。
- EventSourcing:我们用事件存储替换关系数据库,并使用消息队列将组件完全分离。
您可以在Github上找到所有引用的代码。
更多点击标题见原文