本章试图说明据我所知,面向数据编程的核心原理是什么。这在很大程度上取决于我在Clojure的编程经验,但是我认为这些原则与语言无关。
可以使用Java或C#等面向对象(OO)语言来遵守它们,而可以使用Ocaml,Haskell,JavaScript(甚至使用Clojure)之类的功能编程(FP)语言来破坏它们。
实际上,在本章中,我将说明如何在JavaScript(一种支持FP和OOP的编程语言)中应用或打破这些原理。
面向数据(DO)编程的原理是:
大意摘录如下:
关于原则1的评论
- 在纯FP中,函数的行为仅取决于其参数,但这并不是DO的要求(DO中允许使用全局变量)。
- 通过将状态隐藏在函数的词法范围内,可以在FP中打破这一原理。
- 可以在OOP中遵守此原则:例如,这些函数可以聚合为静态类的方法。
- 该原理与数据建模方式无关。通过为每种数据创建一个特定的类,我们可以遵守这一原则。(banq注:与OOAD无关,可以用类概念区别不同种类的数据)
当我们在一个对象中将数据和代码组合在一起时,我们将打破这一原则,如下所示(典型的OOP实施方式):
class Author { |
当我们在函数的词法范围内隐藏数据时,即使没有类,我们也会打破这一原则:
function createAuthorObject(firstName, lastName, books) { |
下面才是分离代码和数据的正确做法:
function createAuthorData(firstName, lastName, books) { |
当我们在静态类中编写代码并将数据存储在没有函数的类中时,即使是类,我们也遵守该原则:
class AuthorData { |
原则1的好处
当我们仔细分离代码和数据时,我们的程序将从以下方面受益:
- 可以在不同的上下文中重用代码
fullName功能可在作者数据和艺术家数据上正常工作:
var data = createAuthorData("Isaac", "Asimov", 500); |
var data = createArtistData("Maurits", "Escher", "Painting"); |
关于这点可参考鲍勃大叔:鲍勃大叔实锤:类与数据结构的比较!每个优秀的软件设计师和架构师都需要牢记的问题
- 可以隔离测试代码
分离代码和数据的另一个好处与前一个类似,是我们可以在隔离的上下文中自由测试代码。
当我们不将代码与数据分开时,我们必须实例化一个对象以测试其每个方法。但是在现实情况下,实例化对象可能涉及许多不必要的步骤。
在DO版本中,其中createAuthorData和fullName是分开的,我们可以自由创建要传递给fullName我们的数据,并进行独立测试fullName:
fullName({firstName: "Isaac", lastName: "Asimov"}) === "Isaac Asimov" |
- 系统往往趋于不太复杂
我所指的复杂性类型是使大型系统难以理解的一种类型,这是在精美的论文Out of the Tar Pit 定义的。它与程序消耗的资源的复杂性无关。
类似地,当我们提到简单性时,我们的意思是“不复杂”,换言之易于理解。
请记住,复杂性和简单性(如困难和容易)不是绝对的,而是相对的概念。我们可以比较两个系统的复杂度,并认为系统A比系统B更复杂(或更简单)。
当代码和数据位于单独的实体中时,由于以下两个原因,系统更易于理解:
实体分为不相交的组:代码和数据。因此,实体与其他实体的关系较少。
让我在图书馆管理系统的类图上说明这种见解,其中代码和数据是混合的。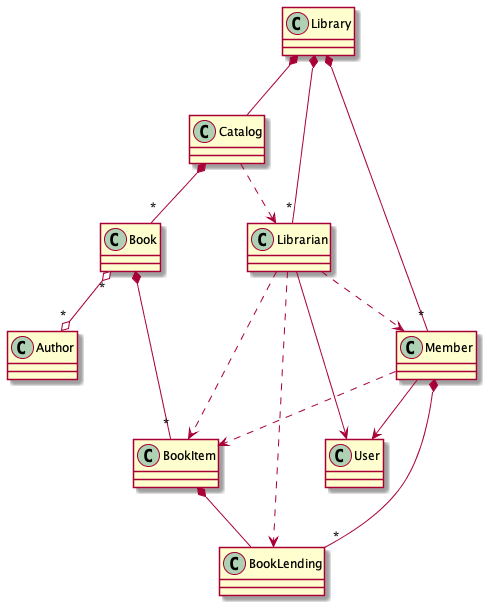
图1.图书馆管理系统的类图概述
不需要知道这些类的详细信息即可注意到,该图表示一个很难理解的复杂系统。该系统难以理解,因为组成系统的实体之间存在许多依赖关系。系统中最复杂的节点是图书管理员实体,该图书管理员实体通过7条边线连接到其他节点。边缘的一部分是数据边缘(关联和组合),边缘的一部分是代码边缘(继承和依赖)。(banq注:如果遵循DDD聚合设计原则,类图中只有聚合关系,其他关联都会切断,通过设计约束产生干净的只有聚合关系类图,不会产生上述类图的多种关联关系图)
现在,如果我们在代码实体和数据实体中拆分了该系统的每个类,而没有对系统进行任何其他修改,则系统图将拆分为两个不相交的部分。
- 左侧仅由数据实体和数据边缘组成:关联和组成(banq注:也就是聚合关系)
- 右侧部分仅由代码实体和代码边缘组成:依赖关系和继承(banq注:依赖是通过服务组件图实现的,不是在类图中实现,具体方式可见我的书籍)
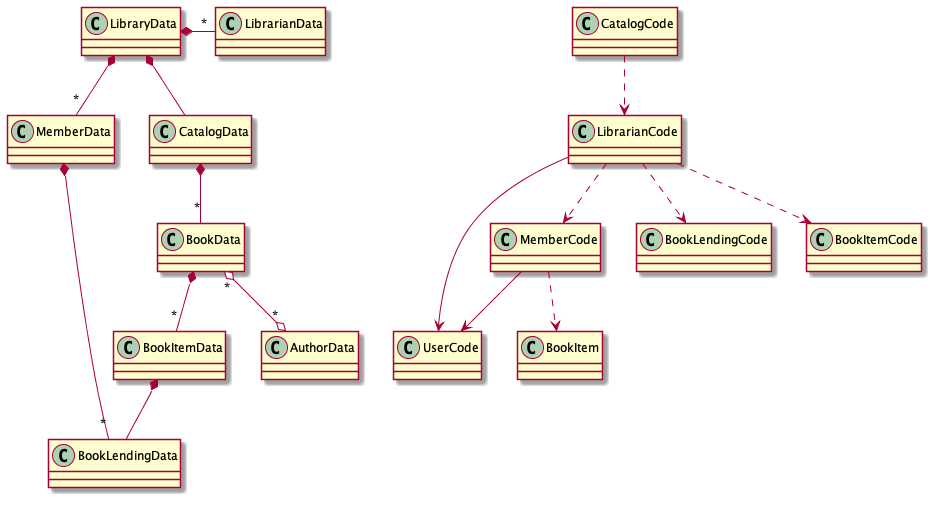
图2.一个类图,其中每个类都分为代码和数据实体
最终的系统肯定更简单。我不确定是否有系统复杂性的正式指标可以使我的意思更简单,但我的非正式理解是:
由不相交的简单零件组成的系统比由单个复杂零件组成的系统复杂。
有人可能会说,将代码和数据混合在一起的系统的复杂性是由于不良的设计和数据造成的,有经验的OO开发人员会利用智能设计模式设计出一个更简单的系统。没错,但从某种意义上讲是无关紧要的。我在这里要说明的一点是,由不合并代码和数据的实体组成的系统往往比由合并代码和数据的实体组成的系统更简单。
多次说过“简单是很难的”。
我的主张是,当我们分离代码和数据时,更容易实现简单性。
原则一的成本
没有免费的饭菜。应用原则1需要付出一定的代价。
为了从代码和数据之间的分离中受益,我们必须付出的代价是:
- 无法控制什么代码访问什么数据
- 没有包装(banq注:没有package就没有模块)
- 我们的系统由更多实体组成
原则二
根据原则1:将代码与数据分开,我们必须将代码和数据分开。原则2的主题是关于我们应该用来对数据建模的编程结构。
在DO中,我们使用通用数据结构(例如映射和数组)而不是特定的类对数据建模。可以使用映射和数组对典型应用程序中出现的大多数数据实体进行建模。
让我们看一下与用于说明原理1的示例相同的简化示例。
下面是使用映射和数组表达原则2:
function createAuthorData(firstName, lastName, books) { |
下面则是违背原则2,使用类表示Author:
class AuthorData { |
在像JavaScript这样的语言中,也可以通过字面literals来实例化地图,这更加方便:
function createAuthorData(firstName, lastName, books) { |
原则2的好处
当我们使用通用数据结构表示数据时,我们的程序将从以下方面受益:
- 利用不限于我们特定用例的功能
艾伦·佩利斯(Alan Perlis)有句著名的名言很好地总结了这种好处:
在一个数据结构上运行100个函数比在10个数据结构上运行10个函数更好。
当我们使用通用数据结构表示实体时,除了第三方库提供的功能外,我们还具有使用我们编程语言中本机可用的丰富功能集来操纵实体的特权。
例如,JavaScript原生提供了对象上的一些基本功能,而第三方库(如lodash)则通过更多功能扩展了该功能。
例如,当作者表示为Map时,我们可以免费将JSON.stringify其序列化为JSON,这是JavaScript的一部分:
var data = createAuthorData("Isaac", "Asimov", 500); |
- 灵活的数据模型
当我们使用通用数据结构时,我们的数据模型具有一定的灵活性,即不会强制我们的数据遵循特定的形状。我们可以自由创建没有预定义形状的数据。而且我们可以自由修改数据的形状。
在经典OO中,每个数据都是通过一个类实例化的。因此,即使需要稍微不同的数据形状,我们也必须定义一个新类。
举例来说,一种类AuthorData,它表示由3个字段的作者实体: firstName,lastName和books。假设您要添加一个fullName具有作者全名的字段。在OO中,您将必须定义一个新类AuthorDataWithFullName。
但是,在DO中,您可以“随时”向映射Map添加(或删除)字段:
var data = createAuthorData("Isaac", "Asimov", 500); |
原则二的价格
没有免费的饭菜。应用原则2需要付出一定的代价。
在对具有通用数据结构的实体进行模式化时,我们必须付出的代价是:
- 性能受到打击
- 数据形状需要手动记录
- 无法在编译时检查数据是否有效 (banq注:TypeJavascript的好处所在)
原则三 数据不可变的
- 数据永远不会改变,但是我们可以创建新版本的数据。
- 允许我们更改变量的引用,以便它引用数据的新版本。
以下是一个函数,该函数Object.assign通过JavaScript本身提供的克隆对象来更改对象内字段的值:
function changeValue(obj, k, v) { |
现在,当myData改变时,yourData不受影响:
var yourData = myData; |
(其他可参考原文,类似DDD中值对象,使用不可变的事件数据替代可变的对象内部状态)
原则三的好处
当我们限制程序永不变异数据时,我们的程序将从以下方面受益:
- 平静地访问所有
- 代码行为是可预测的
- 等同检查很快
- 免费并发安全
关于原则四的评论
- 计算机科学中对平等的定义是一个很深的话题。我们只是在这里稍微提及
- 在这里,我们不处理不同类型(例如列表和向量)的数据收集的比较
- 我们不仅在处理原始类型的相等性
原则4说:
- 具有相同元素的两个数组被视为相等
- 具有相同键和值的两个映射被视为相等
实际上,此定义是递归定义,因为数组的元素和映射的值本身可以是数组和映射。
在原生JavaScript中,数组和映射均打破了这一原则:
var a = [1]; |
false |
为了按值比较数据,需要一个自定义的相等函数,例如Immutable.jsis提供的函数。
var a = Immutable.List([1]); |
原则4的好处
当我们按值全面比较数据时,我们的计划将从以下方面受益:
- 编写单元测试是一种乐趣
- 带有数据键的映射
传统JS不支持这种带有数据键的映射,如下面代码:
var myMap = new Map; |
结果:
Map { |
原因是JavaScript不遵守原则4。
当我们使用遵循原则4的库(例如Immutable.js)时,不会发生这种奇怪的情况:
var myMap = Immutable.Map({}); |
结果:
Object { |
原则四的成本
没有免费的饭菜。应用原则4需要付出代价:
- 没有原生语言的支持
在Clojure中,平等是根据原则4的价值来定义的。但是,在大多数编程语言中,相等性是通过引用而不是值来定义的。为了遵守原则4,我们必须小心不要使用本机相等性检查来比较数据集。
HN讨论:
我一直喜欢“面向表的编程”的思想,其中更详细的架构信息用于完成大多数CRUD和UI工作。在我的实验中,棘手的部分是模式的例外。您始终需要能够命令性地调整(通过代码)。但是属性仍然可以完成大约90%的工作。
当I / O性能成为瓶颈时,它将滋生面向数据的“反模式”。专注于硬件。几乎就像您需要向后工作才能为现代数据加载构建可扩展算法;)通过虚拟内存进行可扩展的机器学习和图形挖掘
http://poloclub.gatech.edu/mmap/
OOP就是“状态代理”。对象是解释器,对于处理来自IoT设备的历史数据,可能需要使用面向数据/函数的方法。时间序列数据不是有状态的,而是有状态的不可变历史(banq注:事件溯源)。通常,函数/转换在这里最有效。
我认为使用Rust这样的原理应该易于遵循
这对于事件溯源或一般来说对于易变性可能成为问题的敏感数据(即财务交易)非常有用。我也认为这完美地映射了值对象。我已经将ES实施到了几个项目中,现在正在编写一个ES库,因为我认为它可以比我以前觉得太冗长的实现更简单,因此我将考虑一些指针。
许多游戏使用的实体组件系统(ECS)可能属于DO。
参考:
鲍勃大叔实锤:类与数据结构的比较!每个优秀的软件设计师和架构师都需要牢记的问题