这篇文章描述了基于Apache Kafka和Redis的体系结构如何应用于构建高性能,弹性流系统。它适用于近实时系统,在该系统中,需要处理大量事件流,并将结果提交给大量的订户,每个订户都接收自己的流视图。
示例可能包括以下内容:
- 流化庄家赔率-不同用户浏览网站的不同部分,其投注单可增加不同的市场
- 实时游戏-根据玩家的输入和游戏规则,为每个玩家计算一个不同的世界视图
- 基于订阅的数据分发,每个使用者接收总数据集的一个分区
该体系结构假设数据量很大,可能需要计算量大的步骤才能计算出各个视图。该体系结构假定reducer(负责计算的组件)可以独立扩展并通过重新启动从故障中恢复。它们的无状态性质和动态扩展使它们非常适合在Kubernetes集群中进行部署。
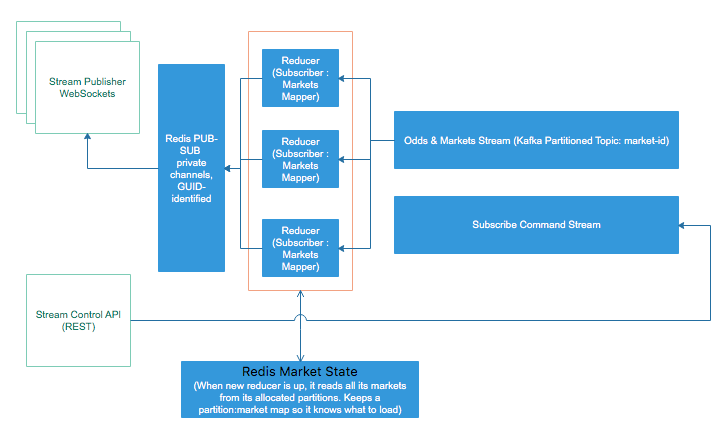
上图使用流系统的术语将博彩赔率分发给所有连接的Web和移动客户端。
总体而言,该系统由几个部分组成,这些部分协同工作并独立扩展:
- 流控制API:可以实现为正常的REST服务,负载均衡。
- 流发布者:它接受WebSockets连接,负载均衡,单个连接可以在任何计算机上运行。
- Redis PUB-SUB组件是通道所在。最终,可以将其分片或替换为RabbitMQ集群。流发布者和Redis PUB-SUB可以替换为socket.io。
- 一个Kafka队列,其中包含两个主题:一个用于流命令(分配给所有的reducer),另一个是分区的主题,所有的reducer都从中使用各自的分区而不重叠(我们称其为data topic)。本主题接收的数据量最大。为了实现良好的负载平衡,建议分区数量很多。
- Reducer本身会消耗数据主题中的非重叠分区。
- 状态存储地方可以是HA Redis集群、MongoDB或任何非常快速的键值状态。
Apache Kafka
Apache Kafka允许以容错,分布式的方式将输入的数据流和计算结果存储在管道的后续阶段。Apache Kafka还允许在高数据负载的情况下将新服务器连接到系统。
- 如果进行复制,则每个分区将有一个服务器作为领导者,而可将其他服务器配置为跟随者。领导者管理特定分区的读/写请求,而跟随者管理领导者的复制。
- 在Kafka中,领导层是按分区定义的。这意味着服务器可以是分区的领导者,而另一个可以是跟随者。
- Zookeeper按主题存储消费者补偿。
使用Kafka开始进行有趣的项目的一种简单方法是使用docker-compose,其设置类似于以下内容:
version : '3.5' |
请注意,以上dockerfile中的竞争条件(Zookeeper启动速度比Kafka慢)导致Kafka服务无法启动,必须使用docker-compose scale kafka=1重新启动。服务启动后,我们可以如下测试配置:
docker run --net=oda --rm confluentinc/cp-kafka bash -c "seq 42 | kafka-console-producer --request-required-acks 1 --broker-list kafka:9092 --topic foo && echo 'Produced 42 messages.'" |
下面是一个短节点脚本,它通过提供默认参数来与上面介绍的dockerfile一起使用,简化了使用kafka控制台工具的操作:
#!/usr/local/bin/node |
这样可以轻松进行如下测试:
- 创建一个名为的主题test:./kafka.js topics --create --topic test --replication-factor 3 --partitions 3
- 列出主题: ./kafka.js topics --list
- 产生一些消息: ./kafka.js produce --topic test
- 要从头开始阅读消息: ./kafka.js consume --topic test --from-beginning
Zookeeper可以并且也应该缩放。由于需要仲裁,用于确定Zookeeper实例数来运行式是2 * F + 1其中F是所期望的容错因子。
为了测试确实有数据正在通过系统传输,让我们为Kafka Producer编写代码。我将使用一个非常基本的NodeJS程序包,该程序包可连接到Kafka的REST API。对于生产用途,应首选更高级的软件包,例如kafka-node撰写本文时快速增长的软件包kafkajs。我在这里使用该kafka-rest软件包是为了简化和方便。
// kafka rest is exposed from docker-compose on 8082 |
一个简单的消费使用者可以实现如下:
const KafkaRest = require('kafka-rest'); |
消费组/使用组提供了构建提议的体系结构的核心抽象。使用方组允许一组并发进程使用来自Kafka主题的消息,同时,确保不会为两个使用方分配相同的分区列表。由于流量波动以及由于使用者崩溃导致的重启,因此可以无缝地扩大和缩小使用者组。使用者组中的使用者会收到一个rebalance通知回调,其中包含分配给他们的分区列表,并且他们可以从分区的开头,该组的另一个成员最后提交的偏移量或自管理的分区中恢复使用抵消。
上面的代码提供了一种非常简单的方法来检查使用者组的工作方式。只需启动几个竞争的消费者并杀死其中一个,或稍后再重新启动即可。由于重新启动策略设置为主题的开头,因此'auto.offset.reset' : 'smallest'每次使用都会从每个分区的开头开始。
Redis注意点
仅通过使用Redis管道尽可能多地批量更新Redis,架构才能实现其最高吞吐量。
对于其他方案,仅在Redis更新后才可以提交Kafka偏移,以牺牲吞吐量来确保正确性。
主要命令和数据流
在本节中,我们将采用赔率更新方案(sportsbook),在这种情况下,更新需要尽快推送到侦听的前端。
一个简单的场景:用户想要订阅单个市场的更改
- 订阅服务器向REST控制API发出“订阅”命令,并且向其发出唯一的通道ID(例如GUID)
- 通过扇出机制(命令主题)进一步向所有减速器reducer发出subscription命令。
- 订阅者打开到Stream Publisher的Websocket,并请求将其连接映射到频道ID。流发布者使用该特定的连接ID订阅Redis PUB-SUB通道。到目前为止,还没有数据发布到Redis PUB-SUB。
- 一旦订阅者收到确认已建立连接的ACK,它将向命令API发出另一个命令“begin stream”。这样做是为了指示简化程序计算初始状态,并在订户打开连接后通过pub-sub发送它,因此不会丢失任何更新。
- 精简器维护两个映射:通道id和连接到市场的通道ID,因此对于每个连接进来的市场,它都直接导向其订阅通道,并且断开连接得到了适当的管理,而不会留下内存泄漏。
Reducers可能会在内存中维护更新的市场值的副本,以进行快速访问和进程内缓存,但是对于每个订阅的市场,其值也必须保存在进程外的Redis HA集群或分片的MongoDB中。订阅时,如果reducer尚未存储市场,即尚未有其他订阅者订阅,则必须首先在共享的Redis或Mongo中查找该市场。在来自Kafka主题的新进入市场更新中,必须首先更新Redis / Mongo。如果无法跳过更新,则仅在Redis / Mongo写入成功后才提交偏移量。订阅也保存在Redis / Mongo中,以使Reducer重新启动,放大或缩小。
为了处理reducer的重新启动,reducer知道了分区逻辑,因此在读取订阅信息时,它将知道它将服务的市场ID类别和忽略的市场ID。如果在将消息发布给订阅客户端之后发送对Kafka的ACK,则reducer可能会选择延迟初始化,而不会从Redis为其分配的市场中读取当前状态。如果订阅率很高,那么reducer可能会选择在Redis的另一个集合中存储一份受欢迎的市场列表,以期渴望初始化时阅读,但在我看来,这不仅仅是一种优化,而不仅仅是必须实现的功能。从头开始。
变化
- 订户能够订阅未知的市场-例如,所有即将开始的足球比赛。在这种方法中,reducer分为两步:第一步,计算与查询匹配的市场ID,并代表客户充当虚拟订户;第二步,上述步骤,将市场发送给订阅客户。
- 复杂查询的视图(例如即将到来的比赛页面)通过REST发布,然后通过CDN发布,以进行快速的初始加载以及时间戳。因此,订户a)知道要订阅哪些市场,因为它们已经在页面中,并且b)可以使用时间戳开始只接收比其已有的更新新的更新。这种方法大大减少了首次加载的时间。
- reducer不是发布市场,而是在用户操作和比赛事件的驱动下转变为游戏状态。在这种情况下,命令队列成为分配给所有reducer的匹配事件的队列,赔率队列成为用户操作的接收者,但常规模式保持不变。
替代方法
可以用于原型制作和相对稳定的MVP的另一种方法是使用诸如MongoDB流(或Firebase或RethinkDB)之类的东西来监听对集合的更改,在该集合中状态被存储和修改。每个文档都是变更的基本单位。客户可以订阅多个文档。所有更改都会传播到所有发布者,发布者会确定哪些是正确的收件人。
这种对体系结构的支持使模型更加简单,使开发人员无需管理复杂的问题(例如持久性,同步和还原),同时减少了依赖项的数量并简化了操作。