如果普通算法是普通程序员必备知识,那么更实用的机器学习算法是不是呢?还是属于数据科学家的必备知识呢?
在准备数据科学中的面试时,必须清楚地了解各种机器学习模型-为每个现成的模型进行简要说明。在这里,我们通过强调要点来总结各种机器学习模型,以帮助您传达复杂的模型。
线性回归
线性回归涉及使用最小二乘法找到代表数据集的“最佳拟合线”。最小二乘方法涉及找到一个线性方程,该方程使残差平方和最小。残差等于实际负预测值。
举个例子,红线比绿线更好地是最佳拟合线,因为它离点更近,因此残差较小。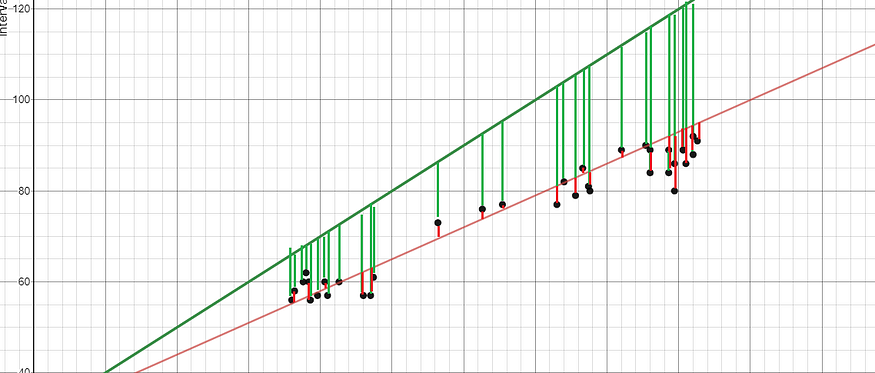
图片由作者创建。
Ridge回归
Ridge回归(也称为L2正则化)是一种回归技术,可引入少量偏差以减少过度拟合。它通过最小化残差平方 和加 罚分来实现此目的,其中罚分等于λ乘以斜率平方。Lambda是指处罚的严重性。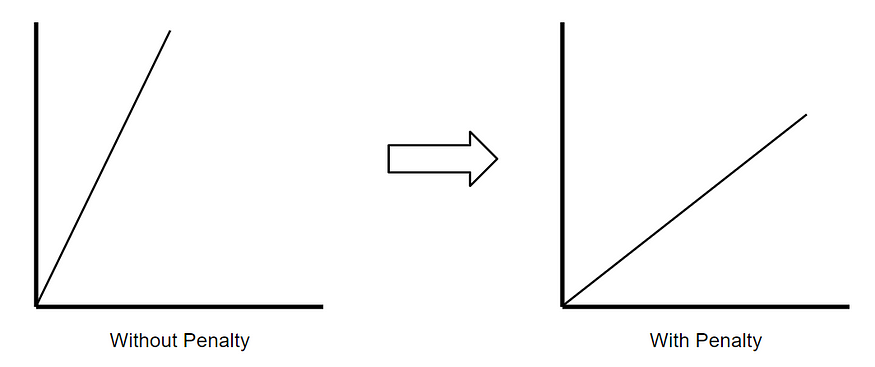
图片由作者创建。
如果没有惩罚,则最佳拟合线的斜率会变陡,这意味着它对X的细微变化更敏感。通过引入惩罚,最佳拟合线对X的细微变化变得较不敏感。背后的岭回归。
Lasso回归
Lasso回归,也称为L1正则化,与Ridge回归相似。唯一的区别是,罚分是使用斜率的绝对值计算的。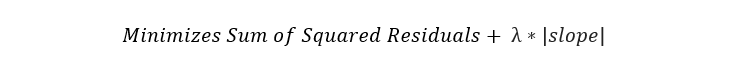
逻辑回归
Logistic回归是一种分类技术,也可以找到“最合适的直线”。但是,与线性回归不同,在线性回归中,使用最小二乘方找到最佳拟合线,而逻辑回归则使用最大似然来找到最佳拟合线(逻辑曲线)。这样做是因为y值只能是1或0。 观看StatQuest的视频,了解如何计算最大可能性。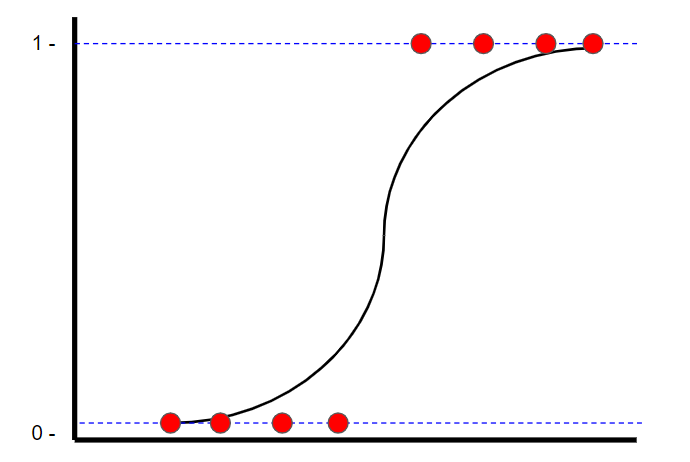
图片由作者创建。
K最近邻居
K最近邻居是一种分类技术,通过查看最近的分类点对新样本进行分类,因此称为“ K最近”。在下面的示例中,如果k = 1,则未分类的点将被分类为蓝点。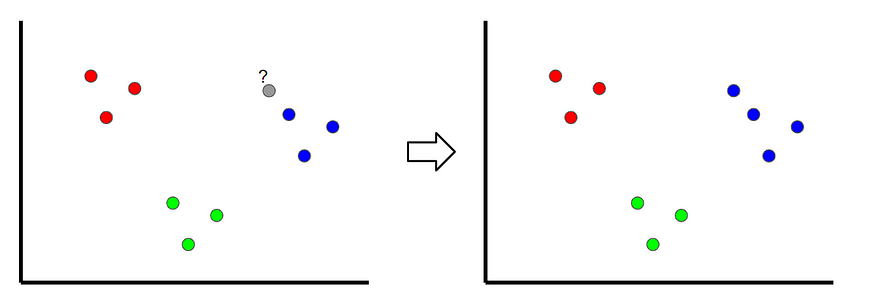
图片由作者创建。
如果k的值太低,则可能会出现异常值。但是,如果它太高,则可能只用几个样本就忽略了类。
朴素贝叶斯
朴素贝叶斯分类器是一种受贝叶斯定理启发的分类技术,其陈述以下等式:
由于天真的假设(因此得名),变量在给定类的情况下是独立的,因此可以如下重写P(X | y):
同样,由于我们要求解y,所以P(X)是一个常数,这意味着我们可以从方程中将其删除并引入比例性。
因此,将每个y值的概率计算为给定y的条件概率x n的乘积。
支持向量机
支持向量机是一种分类技术,可找到称为超平面的最佳边界,该边界用于分隔不同的类别。通过最大化类之间的余量来找到超平面。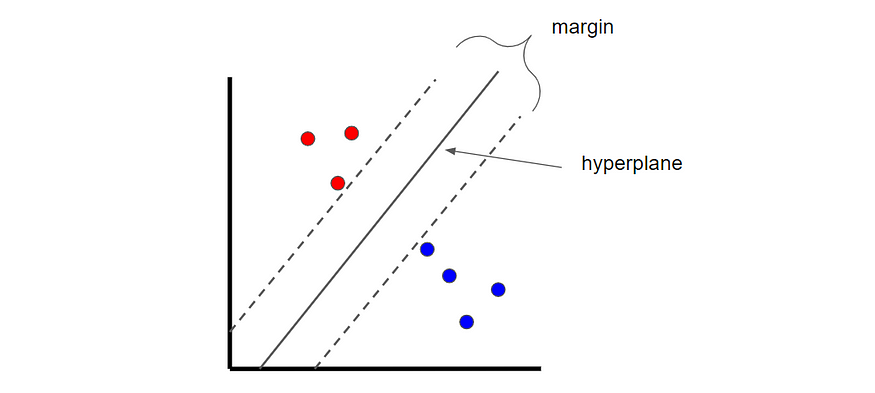
图片由作者创建。
决策树
决策树实质上是一系列条件语句,这些条件语句确定样本到达底部之前所采取的路径。它们直观且易于构建,但往往不准确。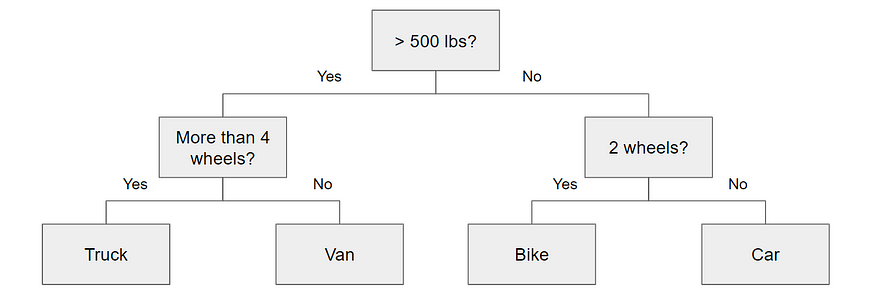
随机森林
随机森林是一种集成技术,这意味着它将多个模型组合为一个模型以提高其预测能力。具体来说,它使用自举数据集和变量的随机子集(也称为装袋)构建了数千个较小的决策树。在拥有数千个较小的决策树的情况下,随机森林使用“多数获胜”模型来确定目标变量的值。
例如,如果我们创建一个决策树,第三个决策树,它将预测0。但是,如果我们依靠所有4个决策树的模式,则预测值将为1。这就是随机森林的力量。
AdaBoost
AdaBoost是一种增强算法,类似于“随机森林”,但有两个重要区别:
- AdaBoost通常不是由树木组成,而是由树桩组成的森林(树桩是只有一个节点和两片叶子的树)。
- 每个树桩的决定在最终决定中的权重不同。总误差较小(准确度较高)的树桩具有较高的发言权。
- 创建树桩的顺序很重要,因为每个后续树桩都强调了在前一个树桩中未正确分类的样本的重要性。
梯度提升
Gradient Boost与AdaBoost类似,因为它可以构建多棵树,其中每棵树都是从前一棵树构建的。与AdaBoost可以构建树桩不同,Gradient Boost可以构建通常具有8至32片叶子的树木。
更重要的是,Gradient Boost与AdaBoost的不同之处在于构建决策树的方式。梯度增强从初始预测开始,通常是平均值。然后,基于样本的残差构建决策树。通过采用初始预测+学习率乘以残差树的结果来进行新的预测,然后重复该过程。
XGBoost
XGBoost本质上与Gradient Boost相同,但是主要区别在于如何构建残差树。使用XGBoost,可以通过计算叶子与前面的节点之间的相似性得分来确定残差树,以确定哪些变量用作根和节点。