Netflix拥有超过1.95亿用户,每天生成数PB的数据。数据科学家和工程师从我们的订户和视频中收集这些数据,并实施数据分析模型以发现客户行为,以最大程度地提高用户满意度。
通常,数据科学家和工程师使用大数据计算技术(例如Spark或Presto)编写Extract-Transform-Load(ETL)作业和管道,以处理此数据并定期计算成员或视频的关键信息。处理后的数据通常存储为AWS S3中的数据仓库表。Iceberg在Netflix中作为数据仓库表格式被广泛采用,该格式解决了Hive表的许多可用性和性能问题。
在Netflix,我们还广泛采用强调关注点分离的微服务架构。这些服务中的许多服务通常都需要对定期生成的细粒度数据进行快速查找。例如,为了增强我们的用户体验,一个在线应用程序获取订户的首选项数据来推荐电影和电视节目。
但是数据仓库的目标不是为了以低延迟服务于微服务的点请求。
因此,我们必须有效地将数据从数据仓库转移到全局,低延迟和高度可靠的键值存储中。
Bulldozer是一个自助式数据平台,可将数据从数据仓库表高效地批量转移到键值存储中。它利用Netflix Scheduler来调度Bulldozer作业。Netflix Scheduler建立在Meson之上,Meson是一个通用的工作流程编排和计划框架,用于执行和管理数据工作流程的生命周期。Bulldozer使数据仓库表更易于被不同的微服务访问,并减轻了每个团队构建自己的解决方案的负担。图1显示了我们如何使用Bulldozer在Netflix上移动数据。
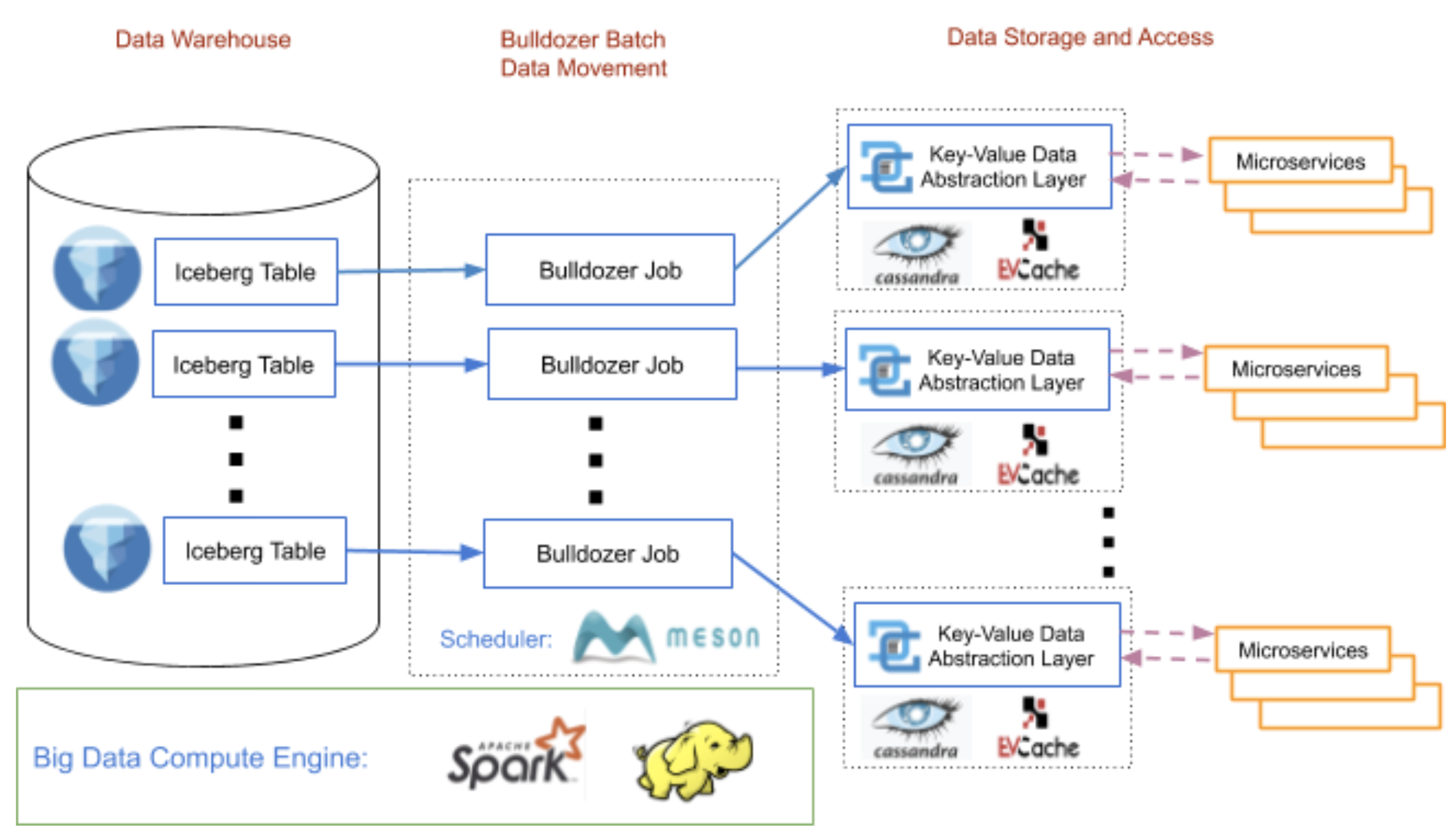
作为将数据移至键值存储的铺装路径,Bulldozer提供了可扩展且高效的无代码解决方案。用户只需要在YAML文件中指定数据源和目标群集信息。Bulldozer提供了自动生成protobuf文件中定义的数据模式的功能。protobuf架构用于Bulldozer和数据使用者对数据进行序列化和反序列化。Bulldozer使用Spark将数据仓库中的数据读取到DataFrames中,使用protobuf中定义的架构将每个数据条目转换为键值对,然后将键值对分批传递到键值存储中。
我们在2020年初将Bulldozer投入生产。目前,Bulldozer每天都将数十亿条记录从数据仓库转移到Netflix中的键值存储。这些用例包括我们成员的预测分数数据以帮助改善个性化体验,用于数据生命周期管理的Airtable和Google Sheets的元数据,用于消息传递个性化的消息传递建模数据等等。