事件建模一直是组织中的痛点。从弄清楚模式的标准格式,有效地处理所述数据模型,最后在将其部署到生产之前进行测试,公司在其数据资产通信方式方面需要某种标准化。
想象一下,一个邮递员将邮件发送给您,您会发现其中一些邮件是信封,其他邮件没有信封,而其余则装在大盒子里。
对于装在大盒子里面的邮件,您现在必须翻阅信封中的内容,打开大而笨重的盒子,然后取下气泡包装纸,然后阅读无信封信。如果邮件以某种标准化的结构到达,生活会不会更轻松?打开邮件时,您会意识到邮件来自不同的国家,并且使用不同的语言编写。这种情况非常类似于负责为企业创建事件驱动平台的软件工程师的生活。
假设一家名为BoopBop的公司拥有各种微服务,数据管道和用于收集指标的现场设备的集合。这些技术因编程语言和硬件而异。您的工作是研究如何在事件设计方面为事件驱动的平台设置主要模式。
设计事件驱动的模型
在研究为事件使用特定的建模语言之前,需要考虑以下三种主要方法:
- 裸信:事件模型具有流程要发出的特定数据所需的所有字段。
- 深层信封:您希望发出的事件被打包到一个信封中,其中包含处理所需的高级元数据。信封被定义为“深层”,因为它定义了可以封装的所有已知事件有效负载。在写入时考虑架构。
- 浅信封:此事件模型类似于深信封方法,但是信封可以接受放置在其中的任何有效载荷。阅读时考虑架构。
接下来的几节更详细地概述了每种方法,介绍了它们的取舍,并总结了每种方法对您的组织结构的影响(与Conway法则有关)。
裸信
使用裸信方法意味着每个进程都可以根据其定义的结构自由发布事件,该结构包含处理该事件所需的所有数据(就地或带有引用)。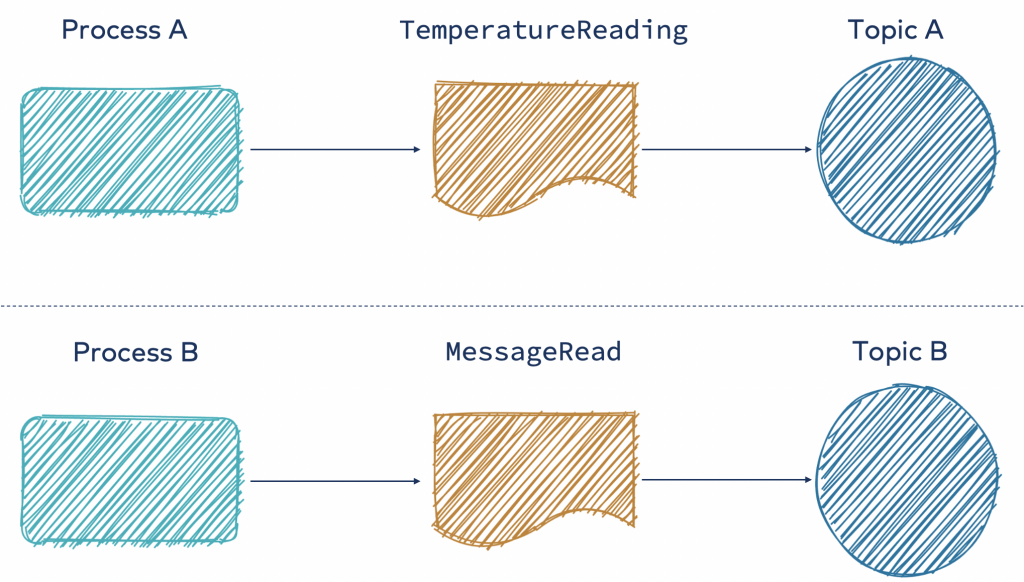
优点如下:
- 没有事件架构重叠;它不依赖其他团队;它带来了“微服务”的好处
- 为这些事件编写一个简单的使用者很简单;发出的模式中的字段符合意图
- 需要序列化最少的数据
- 模式已完全表达,允许在发布之前进行兼容性检查,从而降低了风险
另一方面,这是缺点:
- 由于事件架构的独立性,不能保证存在通用的架构元素。这使编写更高级别的处理器变得更加困难(事件的创建时间可以在每个架构的不同字段中,例如userReadDate和temperatureRecordingTime)。
- 需要在消费者方面付出更多的努力来将数据协调在一起,从而导致语义和翻译要求方面的数据质量问题。
- 结果,跨域的通用字段发生了复制。
当您正在使用的域没有很多共享组件时,或者如果您仍在初步确定系统范围的过程中,这种方法非常有用。
信封
在研究这两种信封方法之前,我们先定义一些信封的术语和属性。
信封试图提取与包含在信封有效载荷内的内容有关的标识或元数据。就像现实生活中的信封一样,它可以帮助您快速将相关性或优先级分配给某些信封,例如账单和工资单。本质上,每个信封都应尽量减少识别或为给定有效负载分配值所需的工作量,而无需通过标准化字段明确查看有效负载本身。在软件领域,这可以是ID,时间戳,优先级和枚举。好处是,它允许编写通用处理器,以便它们在信封级别上运行,而无需深入研究在多个不同事件模式中查找某些元数据的位置。
鉴于事件模型模仿了树数据结构,您可以定义模型的深度,该深度是嵌套最多的元素(例如depth[“payload.nested1.nested2.product_id”] = 4)。
自然,可以将数据模型的宽度定义为给定字段的最宽扇出。例如,如果数据模型中的某个字段可以是N种不同的类型,则该字段的宽度将是N(具有N个子节点的节点)。
从经验角度来看,您希望设计信封的深度和宽度尺寸不要太小或太大。包含一个组织中所有事件的信封(宽度为数千个)可能不是最容易使用的,就像在关系数据库中有一个具有数千个列的表中通常不是最佳的设计方法。
信封在域中的位置越多,深度和宽度尺寸越好,可以更好地代表开发人员的经验和可维护性,以及共享信封字段的相关性和数量。通常有多个信封定义按某个参数分组,例如部门,域或团队。
- 深信封
深层信封方法试图将某些共同点引入顶层(即信封字段),例如事件ID或用户ID。就重新定义这些字段而言,这减少了N个有效载荷之间的重复,并且还允许下游使用者使用信封元数据执行更高级别的操作,例如路由和分组。请注意,上面的公共字段仅是示例。实际上,它们取决于您的域和用例。
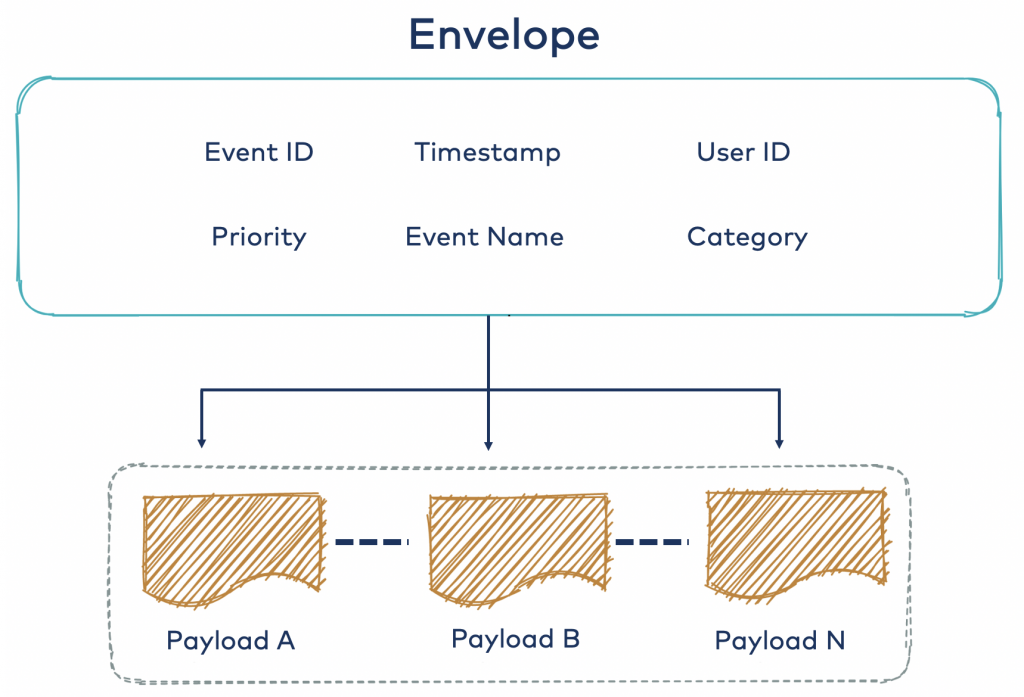
现在让我们看一下这种方法的优点:
- 通过在顶层定义有效负载模式,可以减少模板字段的数量
- 标准化的信封字段允许完成路由而无需查看附加了哪些有效负载以及重复数据删除,优先级处理等
- 模式很深,可以在编译和发布时进行兼容性检查
- 使用正确范围的信封,该模型会提供有关定义的明确性质的允许发送内容和不能发送内容的指南
- 鼓励就包络和有效载荷的定义进行协作。
然而,这种方法并非没有缺点:
- 在有效负载(意图)和任何尝试发出或处理事件的人之间添加一个额外的层。当填写某些公共字段与特定有效负载字段时,这增加了错误和错误解释的空间。
- 由于深度和宽度的原因,此方法的范围可能不合适,从而导致可维护性差和开发人员体验差。
- 如果没有更高级的数据治理工具和流程,则很难在团队和部门之间实施和管理这种方法。
- 仅查看信封,即使您不想处理事件,也需要反序列化。
当域是众所周知的且易于理解时,此方法效果很好,并且允许通用处理器“查看”有效负载,并且在发布之前也进行了强大的兼容性检查。
- 浅信封
较浅的信封允许将任何可能的有效载荷附着到信封,就像现实生活中的信封一样。无论是帐单还是浪漫的情书,对信封本身都不重要。就像关系数据库中的BLOB数据类型一样:“我稍后会解决”,或者更好的称为“读取架构”方法。
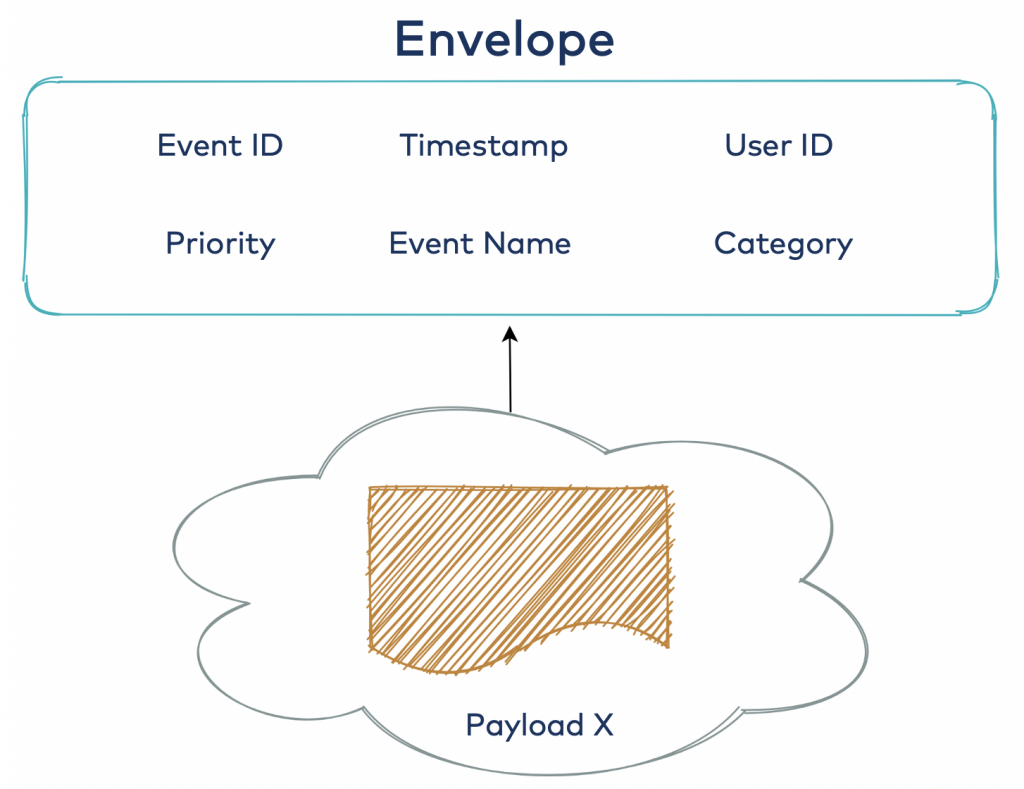
这些是优点:
- 缺少严格的耦合将提供最大的灵活性,并且不需要您在出现新的有效负载时更新信封的定义。这样无需更新模型即可快速推向市场。
- 您只能对信封执行浅层反序列化,这意味着仅用于处理信封而不用于处理有效载荷的资源较少。
- 当您不知道可能要预先生成的数据或仍在摸索中的情况下,这种方法是理想的选择。
这些是缺点:
- 由于模型未定义可以附加到信封上的内容,因此在编译和发行时无法进行兼容性检查。这为运行时上下文带来了风险。
- 由于没有与事件关联的绑定模型,因此您不得不显式地编写逻辑代码以“解压缩”任意有效负载。这导致跨应用程序的代码重复和跨软件生态系统的代码漂移。需要将事件定义手动重新定义为所选编程语言的层次越多,中断和错误的风险就越高。
- 该模型的任意有效负载表达式不能很好地自我记录。换句话说,“剧本”更有可能是为某些领域和服务编写的,通过“共享理解”实施有效地模仿了一个深层的信封。
- 这种方法的宽度是无限的,并且可以占用任何有效负载,如果连接了错误的有效负载,这可能会很昂贵。
当信封更加通用时,通常是在需要封装大量有效载荷时,最终方法会很好地工作。如果您可以在应用程序级别上进行额外的验证工作以确保连接正确的有效负载,或者您的应用程序是数据资产的代理并且仅需要包装和标记流经的数据,则它是完美的。
结论
某些方法鼓励协作,例如深层信封,而其他方法则鼓励自主,独立的思考。作为组织的领导者,您有责任灌输业务所需的文化类型,一直到表达事件的方式。
点击原文可见使用Protobuf实现这几种邮件信封的代码。