当我们在Cloudflare审查设计文档时,我们总是在寻找单点故障(SPOF)。消除这些问题是构建您有信心的系统的必要步骤。具有讽刺意味的是,当您设计具有内置冗余的系统时,您会花费大量时间来考虑冗余失败时系统的功能运行是否正常。
2020年11月2日,Cloudflare发生了一个事件,该事件在6小时33分钟内影响了API和仪表板的可用性。在此事件期间,对我们的API的查询成功率定期下降至75%,并且仪表板体验比正常情况下慢80倍之多。尽管Cloudflare的优势已在全球范围内广泛分布(并且一直保持正常运行),但Cloudflare的控制平面(API和仪表板)由大量的在两个区域冗余的微服务组成。对于大多数服务,支持这些微服务的数据库一次只能写在一个区域中。
Cloudflare的每个控制平面数据中心都有多个服务器机架。这些机架中的每个机架都具有两个成对工作的开关-通常都处于活动状态,但是如果一个发生故障,则另一个可以继续处理负载。
Cloudflare通过在机架之间分布最关键的服务来解决机架级故障。每个硬件都有两个或多个电源不同的电源。每台存储关键数据的服务器都使用RAID 10冗余磁盘或存储系统,它们可以在不同机架中的至少三台计算机之间(或同时在这两者之间)复制数据。我们需要审查和要求每一层都有冗余。那么-怎么会出错?
在这篇文章中,我们介绍了发生的事情的时间表,以及称为拜占庭式故障的困难故障模式如何在一系列事件中发挥了作用。
2020-11-02 14:43 UTC:部分交换机故障
在时间14:43时,网络交换机开始行为异常。警报开始触发有关ping无法到达的开关。设备处于部分运行状态:LACP和BGP等网络控制平面协议仍可运行,而vPC等其他协议则未运行。
vPC链接用于在多个交换机之间同步端口,以使它们在连接到与它们相连的服务器时显示为一台大型聚合交换机。同时,数据平面(或转发平面)未处理和转发从连接的设备收到的所有数据包。
由于LACP的负载平衡特性,每个服务器只能看到部分流量问题,因此这种故障情况对于连接的节点是完全不可见的。如果交换机完全失败,则所有流量都将故障转移到对等交换机,因为连接的链路将完全断开,并且端口将从转发LACP捆绑包中退出。
六分钟后,切换恢复,无需人工干预。但是这种奇特的故障模式导致了进一步的问题,这些问题在交换机恢复到正常操作后持续了很长时间。
2020-11-02 14:44 UTC:etcd错误开始
交换机行为异常的机架在我们的etcd集群中包含一台服务器。每当我们需要在多个节点之间可靠的高度一致的数据存储时,我们都会在核心数据中心大量使用etcd。
如果集群领导者发生故障,etcd将使用RAFT协议保持一致性并建立共识以提升新领导者。在RAFT协议中,假定群集成员可用或不可用,并且仅提供准确的信息或根本不提供任何信息。当计算机崩溃时,这可以很好地工作,但并不总是能够处理群集中不同成员具有冲突信息的情况。
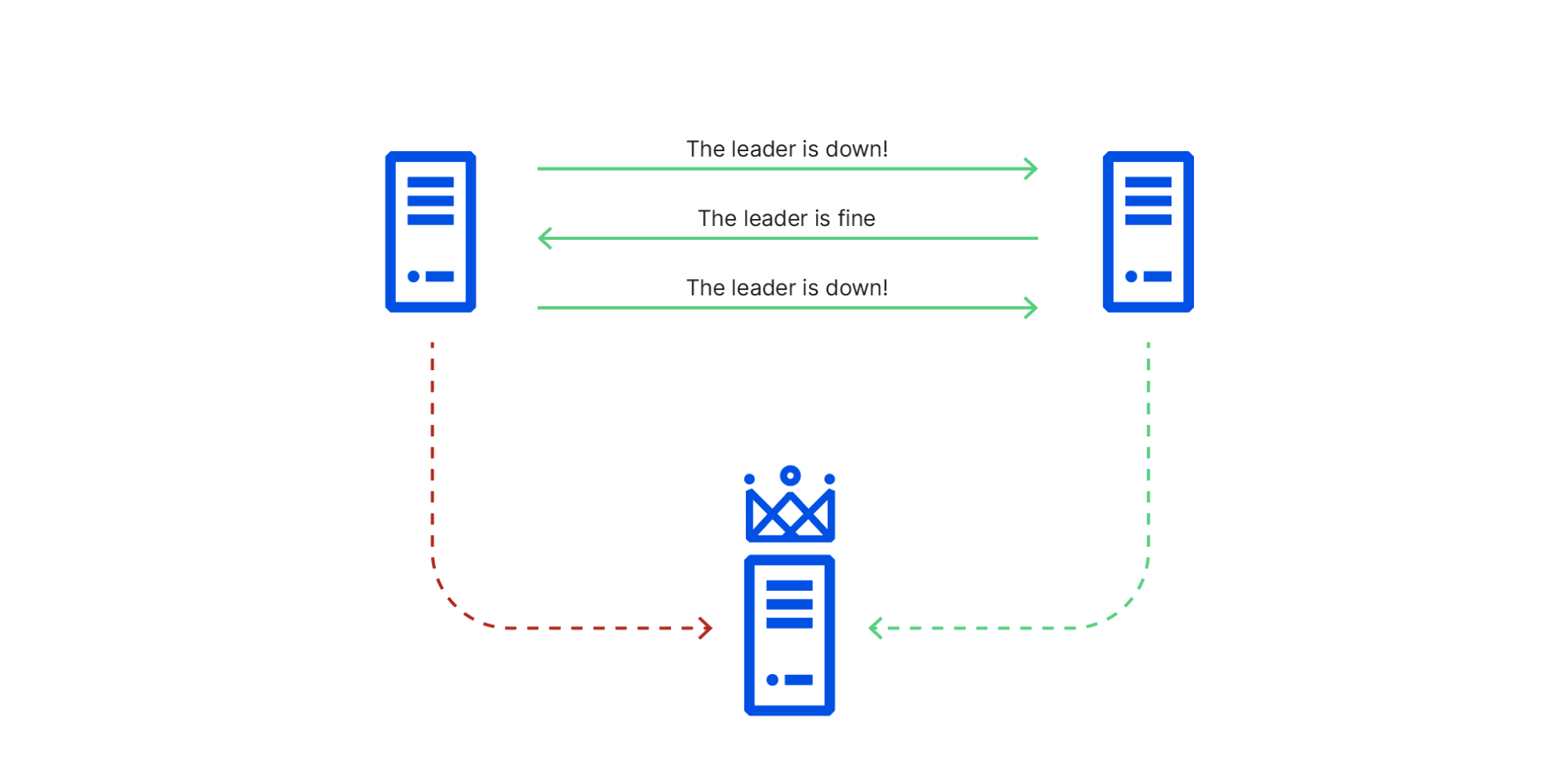
在这种特殊情况下:
- 节点1(在受影响机架中)和节点3(领导者)之间的网络流量正在通过处于降级状态的交换机发送,
- 节点1和节点2之间的网络流量正在通过其工作对等方,并且
- 节点2和节点3之间的网络流量不受影响。
这导致集群成员对现实存在冲突,这在分布式系统理论中被称为拜占庭断层。由于此冲突的信息,节点1反复发起了领导者选举,为自己投票,而节点2反复投票了仍可以连接到的节点3。这导致它绑定到了节点1无法访问的领导者。
RAFT领导者的选举具有破坏性,阻止所有写入,直到它们被解决为止,因此这使群集变为只读,直到故障交换机恢复并且节点1可以再次访问节点3。
.....
拜占庭容错(BFT)是一个热门的研究主题。解决方案自1982年以来就广为人知,但是必须在各种工程设计之间做出选择,包括安全性,性能和算法简单性。大多数通用集群管理系统选择完全放弃BFT,而使用基于PAXOS的协议,或者使用PAXOS的简化版本(例如RAFT),其性能优于BFT共识协议。在许多情况下,已知一种易受罕见故障模式影响的简单协议比难以正确实施或调试的复杂协议更安全。
BFT共识的最初用途是在安全关键型系统中,例如飞机和航天器控制系统。这些系统通常具有严格的实时延迟约束,这些约束要求将共识与应用程序逻辑紧密耦合,从而使这些实现不适用于etcd等通用服务。关于BFT共识的当代研究主要集中在跨越信任边界的应用程序上,这些应用程序需要防御恶意集群成员和故障集群成员的攻击。这些设计更适合于实现诸如etcd之类的通用服务,我们期待与研究人员和开源社区合作,使其适合生产集群管理。
评论:
不能确定者就是拜占庭式失败,但可能反映出Raft相对于传统Paxos较差的活跃特性
我确实认为拜占庭需要积极的不诚实行为,但是根据Wikipedia的定义,这是“向不同的观察者呈现不同症状的任何错误”。
人们通常将故障分为故障停止行为(例如崩溃)或拜占庭行为(其他所有因素)。
裂脑是拜占庭式攻击。这是当您对一个方说一件事而对另一方说另一件事时。
prevote是一种(部分)改善Raft活跃性的方法。默认情况下,etcd可能没有实现prevote。
早在2015年,我就用Raft强调了这些问题,但被告知我的示例场景是人为设计的,并且在现代数据中心中部分网络故障是不现实的。现在,这些人为造成的情况之一就是6个小时Cloudflare中断的根源。
的确如此-太多的开发人员将这种“冗余交换机架对”的思维模型作为魔术框图组件。
这些年来,分布式计算的谬论仍然成立。结合从CAP中获得的经验教训,忽略在“现代”环境中人为造成的和不可能的明显问题永远是不明智的。
局部网络故障很少见,但可能会造成灾难性的后果。我担心它们在我们复杂的数据中心中会越来越普遍。基于超时的正确性和活跃性是一个令人担忧的问题。
您可以通过多种方式使选举成为非抢先。还需要确保客户对可能失去与当前领导者联系的特定成员不粘接在一起。