了解流式数据基础结构的使用和滥用很重要。Apache Kafka是一个消息代理,在过去几年中迅速普及。消息代理中间件已经存在了很长时间。它们是一种数据存储,专门用于在生产者和使用者系统之间“缓冲”消息。Kafka之所以流行,是因为它是开源的并且能够扩展到大量消息。
消息代理通常用于使数据的生产者和消费者分离。例如,在Fivetran中,我们使用类似于Kafka的消息代理来缓存客户生成的Webhook,然后将它们批量加载到您的数据仓库中:
在这种情况下,消息代理将提供持久的事件存储,这些事件是客户发送的事件,然后Fivetran将事件加、载到数据仓库。
但是,Kafka偶尔被描述为不仅仅是一个更好的消息代理。支持该观点的人将Kafka定位为一种全新的数据管理方式,其中Kafka取代了关系数据库作为已发生事件的确定记录。无需读写传统数据库,而是将事件追加到Kafka,然后从代表当前状态的下游视图中读取。这种体系结构已被描述为“将数据库从内向外转换”。
原则上,能够用同时支持读取和写入的方式来实现这种类似数据库的体系结构。但是,在此过程中,您最终将面临数据库管理系统数十年来所面临的每一个难题。您将或多或少必须在应用程序代码中编写完整的DBMS。而且您可能做得不好,因为数据库需要花费数年的时间才能正确完成。您将不得不处理草率读取,幻像读取,写入歪斜以及仓促实现的数据库的所有其他症状。
ACID
使用Kafka作为主要数据存储的根本问题是它没有提供隔离(ACID中的I代表隔离)。
隔离意味着,在全局范围内,所有事务(读和写)都沿着某个一致的历史记录发生。Jepsen 提供了隔离级别的指南(隔离意味着该系统将不会遇到某些异常)。
让我们考虑一个为什么隔离很重要的简单示例。假设我们正在运行一个在线商店。用户结帐时,我们要确保他们所有的物品实际上都在库存中。这样做的方法是:
- 检查用户购物车中每个项目的库存水平。
- 如果商品不再可用,请中止结帐。
- 如果所有项目都可用,请从库存中减去它们并确认结帐。
假设我们正在使用Kafka来管理此过程。我们的架构可能看起来像这样:
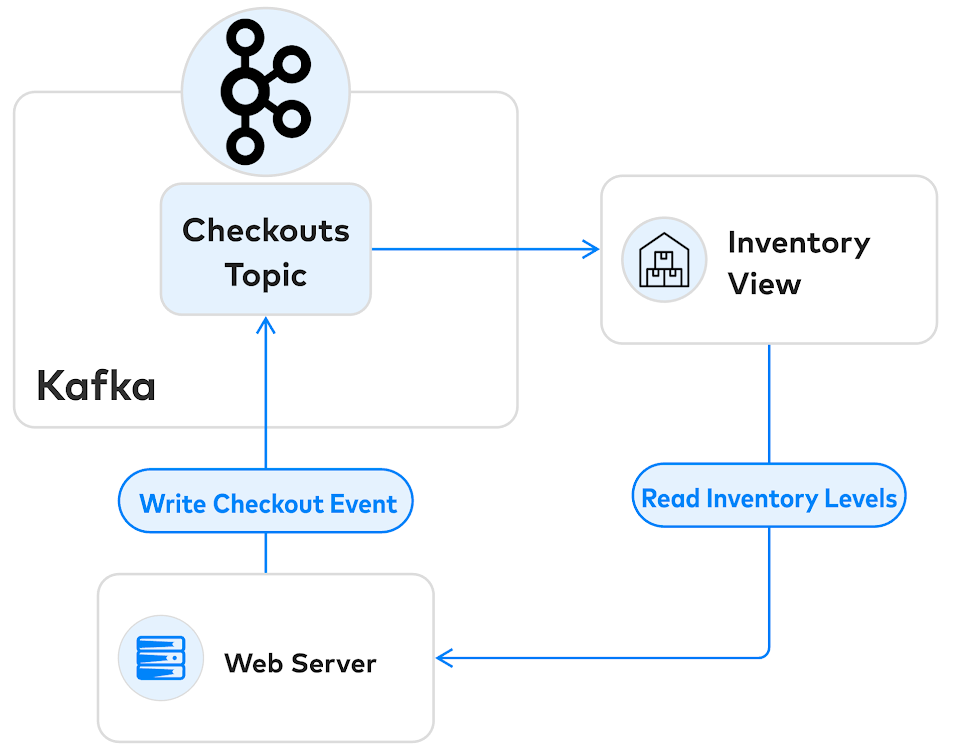
Web服务器从Kafka下游的视图读取库存(Inventory Level),但是它只能向上游Kafka的checkouts Topic提交结账事务。问题是并发控制之一:如果有两个用户竞相购买库存最后一件商品,则只能有一个成功。我们需要检查库存视图,并立即在某个时间点确认结账。但是,在当前这种体系结构中无法做到这一点。
我们现在遇到的问题称为写偏斜write skew。在处理结帐事件时,我们从库存视图中读取的数据可能已过期。如果两个用户几乎同时尝试购买同一商品,那么他们都会成功,而我们将没有足够的库存来满足他们的需求。
像这样的事件溯源架构受到许多的这种隔离异常影响,需要用户用户小心不断提供“时间旅行”的旅行检查。更糟的是,研究表明,这种异常允许这种架构创建彻底的安全漏洞,允许黑客窃取数据,覆盖这个优秀的博客文章对这一研究论文。
与数据库一起使用Kafka
如果将Kafka用作传统数据库的补充,则可以避免这些问题: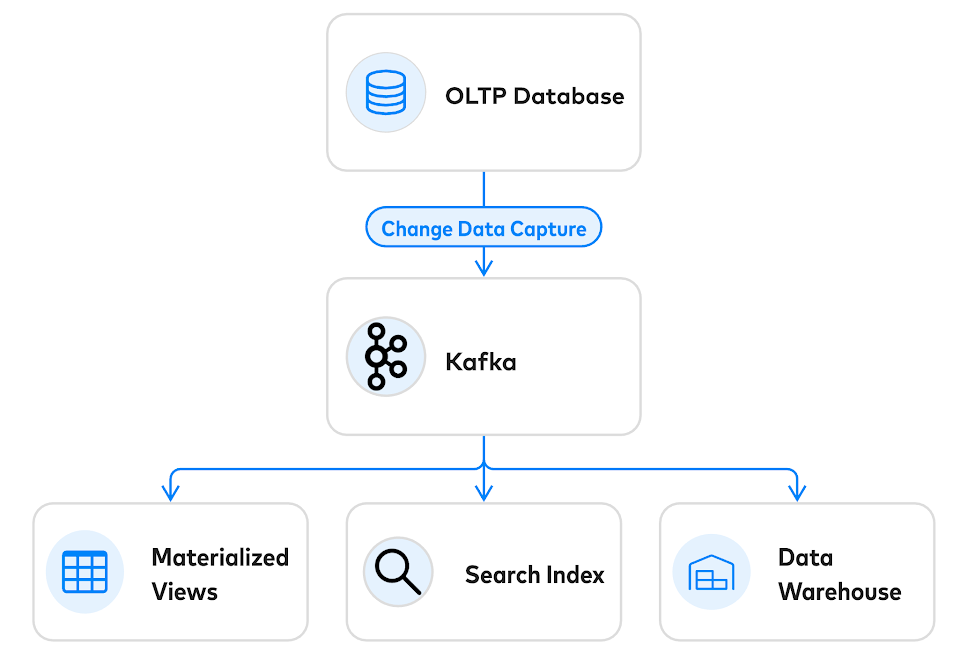
OLTP数据库可以实现一项消息代理不太适合的关键任务:事件的准入控制。相比消息代理作为“发送并忘记”事件机制,OLTP数据库将事件模式强制为“意图模式”,数据库可以拒绝发生冲突的事件,从而确保仅发出一致的事件流。OLTP数据库确实擅长于此核心并发控制任务:每秒扩展到数百万个事务。
使用数据库作为写入的入口点,从数据库提取事件的最佳方法是通过流式传输change-data-capture。有许多很棒的开放式CDC框架,例如Debezium和Maxwell,以及现代 SQL 数据库中的本机CDC 。变更数据捕获还建立了一个优雅的操作案例。在恢复方案中,所有内容都可以在下游清除,并从(非常持久的)OLTP数据库中重建。
请勿误建数据库
数十年来,数据库社区已经学习(并重新学习了)一些重要的经验教训。这些课程中的每一个都是以数据损坏、数据丢失和大量面向用户的异常情况的高昂代价获得的。您要做的最后一件事是发现自己在重新学习这些课程,因为您不小心误建了一个数据库。
实时流消息代理是管理高速数据的绝佳工具。但是您仍然需要传统的DBMS来隔离事务。最好的参考架构是使用OLTP数据库进行事件的准入控制,使用CDC进行事件生成,并将数据的下游副本建模为实例化视图。