如今人工智能研究和人类大脑研究相互促进,本文提出一种理性模型事关每个人的幸福,如果你理解了,你就会释然:人类大脑是将原始经历(如感觉、记忆)与上下文(如先验、期望、其他相关的感觉和记忆)结合起来产生感知。大白话:人类感知=原始经历(raw experience/evidence )+上下文(先验priors),本文是围绕这两个部分比重不同展开的。中国有句谚语:一朝被蛇咬,十年怕草绳,本文提出“被困先验”模型解释这种心理现象以及形成偏见和固执的原因:
一般人的认知方式是一种正常的贝叶斯推理:假设您住在加利福尼亚州的一个普通郊区,而您的朋友说她在上班途中看到了土狼。你能相信她 :您的原始经历(朋友说的这句话,未经分析的经历,原始经历,raw experience)和您的上下文背景(土狼在您所在的地区很丰富)加起来好像是那么一回事;但是,假设您的朋友说她在上班途中看到一只北极熊。现在,您就对此怀疑了;原始经历(朋友说的这件事)是相同的,但是上下文(先验是加利福尼亚出现北极熊的概率很低)使其变得难以置信。
正常认知的贝叶斯推理举例
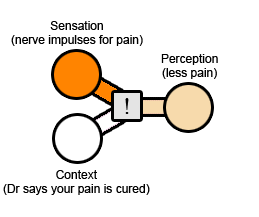
安慰剂作用几乎同样道理:您很痛苦,所以您的医生给您开了一个“止痛药”(您不知道这确实是一种糖药)。原始经历是神经发出的疼痛冲动与以前一样多。上下文是您刚吃了一颗药,医生保证您会得到改善。结果:您的痛苦减轻了。
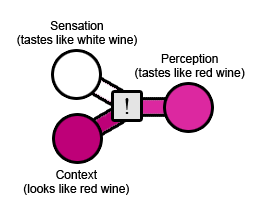
下图感叹号的灰色框,代表“加权算法”。有时,算法会将几乎所有的精力都放在原始经历上,最终结果将都是原始经历,只需要根据上下文对其进行少量调整。在其他时候,它将几乎全部放在上下文上,最终结果将几乎完全不依赖于原始经历。或者这个算法的权重为50-50。这里的因素非常复杂,我希望即使我将灰色框也视为黑色框,您仍然可以找到帮助。
案例2:如果将白葡萄酒染成红色,很多人会说它的味道像红酒。原始经历是:葡萄酒本身的味道,就是白葡萄酒。但实际情况上下文是您喝的是红色液体。结果:它的味道像红酒。(这里权重多数倾斜在了上下文)
什么是被困先验
有很多关于老鼠的习惯研究:敲响铃铛,然后给老鼠电击。在您执行了足够的次数后,他们会害怕钟声-听到它们后便会畏缩(一朝被蛇咬,十年怕草绳)。然后,您切换为响铃,不触电。刚开始时,老鼠仍然不怕钟声。但是过了一会儿,他们意识到钟声再也不会伤害他们了。他们会像对待其他噪音一样进行调整。他们失去了恐惧-他们习惯了。
人类也会发生同样的事情。也许当您还很小的时候,一只大狗在向您咆哮,有一阵子您怕狗了。但是随后您遇到了许多友好的可爱幼犬,您意识到大多数狗并不可怕,并且您得出了一些合理的结论,例如“长大的大狗很可怕,但可爱的幼犬却并不可怕”。
有些人却永远无法做到这一点。他们会感到恐惧,对狗的病理恐惧(一朝被蛇咬,十年怕草绳)。在其最初的技术用途中,恐惧症是一种强烈的恐惧,无论您有多少次接触狗而没有发生任何不好的事情,您都会保持恐惧。为什么?
在过去,心理学家会通过向患者灌输恐惧对象来治疗恐惧症。我们会将您放在一个巨大的罗威纳犬的房间里,锁上门,等到您出来时,也许您将不再怕狗了。听起来野蛮?也许是这样,但更重要的是它实际上并没有起作用。您可以和罗威纳犬一起呆在房间里整整一整天,罗威纳犬可以入睡或舔脸,或者做一些其他足以使您相信它并不可怕的事情,而等到您离开时,您就会比您进门时更怕狗。
现在是通过这种办法解决:首先,让您从看狗的图片开始,如果您的情况足够严重,甚至这些图片也会使您有些紧张。一旦您看了成千上万张照片,就习惯了看它们。然后,我们将把您放在一个大房间里,关着一只可爱的小狗在笼子里。您不必靠近小狗,也不必抚摸小狗,只需坐在房间里就不会抓狂。一旦您完成了无数次的尝试并失去了所有的恐惧,直到您被罗威纳犬锁在房间里为止。
有道理的是,一旦您与狗接触一百万次并且一切正常,一切都会好起来的,您会失去对狗的恐惧-这是正常的习惯。
但是现在我们回到了最初的问题:为什么我们不能只从罗威纳犬开始呢?
常识性的答案是,只有当与狗的经历最终变得安全无事时,您才会习惯。但是和罗威纳犬一起呆在房间里真是太恐怖了。这不是安全的好经历。
表面上看:习惯化需要一种安全感,但是(像其他所有感性一样)其实这种所谓习惯还是取决于原始经历和上下文的结合。
原始经验:罗威纳犬平静地摇着尾巴,看起来不吓人。但是一旦被狗吓坏之后,就有一个非常强烈的原始经历,结果:罗威纳犬令人恐惧。以后你做的任何上下文的更新将倾向于狗是可怕的,而不是相反!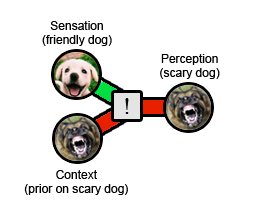
这就是被困的先验。
它被困是因为无论您得到什么新证据,最终感知都永远不会更新。您可以连续拥有一百万条与狗有关的好经历,而每条狗只会使您更深地担心狗。您先前对狗的恐惧决定了您目前的经历,而这反过来又成为了以后相遇时的精神错乱。
被困先验的高级版本
上面的部分描述了被困先验的简单认知情况。它根本没有带来情感的想法:如果使用相同类型的贝叶斯推理算法实现计算机程序,那么无情感的威胁评估计算机程序可能会理想地解决相同的问题。但是,当人们情绪激动时,就会发现自己更容易产生偏见。为什么?
Van der Bergh等人建议,当原始经历太不能忍受时,您的大脑会减少“原始经历”通道上的带宽,以保护您免受创伤性情绪的影响。这就是为什么某些创伤受害者对其创伤的描述通常很短,不详细且不切实际的原因。这样可以保护受害者,使其不必在所有血腥细节中都受到可怕的刺激和负面情绪的影响。但这也确保上下文(而不是原始经历本身)将在确定他们对事件的感知中起主导作用。
您无法更新有关这只狗很友善的感知,因为您的原始经历带宽变得非常狭窄。你最终认知是几乎完全基于你对狗有什么原生经历。
有人称其为母狗吃饼干,当您处于被虐待或其他可怕关系中。您的伴侣给了您充分的理由来憎恨他们。即使看到他们吃饼干的看似无辜的事情,也会让您很生气。从理论上讲,与伴侣的互动中,他们只是吃薄脆饼干而不会以任何方式打扰您,这应该会产生一些习惯,这只是很小的证据,表明它们并不总是那么糟糕。实际上,这只会使您更讨厌它们。在这一点上,您对它们不好的原始经历之所以如此之高,以至于每一次交互,无论它如何进行,都会使您更加讨厌它们。您被之前认为它们不好的东西困住了,产生了偏见。
这种模型表明:越来越多的证据只会使您更加确定自己的既定信念也就是原始经历,而不论它是否可能否定了你的原始经历,这些都是被困先验的悲哀,这些人好像命中注定了。(偏见、固执己见一生无法醒悟)
更多点击标题见原文,原文后有非常热烈的长篇讨论,因为这种模型理论事关每个人的幸福。