一家商店的老板最近发现了惊人的入店行窃率。他开发了一种机器学习模型,该模型可以预测客户是否入店行窃,并且准确率高达95%!他部署了该模型,但一个月后却没有发现任何扒手。
为什么?
在我们解决这个问题之前,重要的是要了解什么是准确性。准确度是您正确预测某事物的次数除以您实际预测该事物的次数。
如果仔细查看数据集,您会注意到进入商店的10,000名客户中,当月只有500名是入店行窃者。一些快速的数学运算将告诉您,95%的顾客不是扒手,而另外5%是。
如果您判断这些人都不是扒手,那么100例案例中有95例是正确的,这就是模型所做的。在其他5例情况下,您可能会错,但是谁在乎呢?我们仍然有95%的准确率。
但这显然不是我们想要的:在数据严重偏斜的“不平衡”数据集中会发生此问题。
要么有扒手,要么没有,两者中前者在数据集中的存在明显更多。我们的模型找到了提高准确性的捷径。
故事的寓意:准确性不适用于数据偏斜的情况。
那么,我们该如何解决这个问题呢?
使用不同的指标评估模型,让我们看一下查全率率recall和精度,但是首先,了解一些术语很重要。
这是一个混淆矩阵,它向您显示模型预测与基本事实的所有可能情况。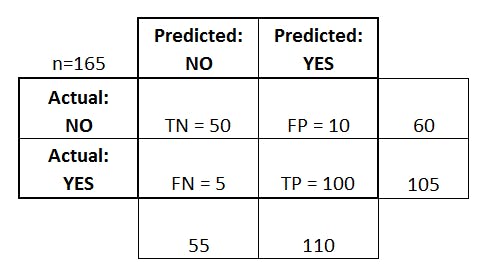
这个解释更好,混淆矩阵向我们展示了模型对基础事实的预测:它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。
让我们将其与入店行窃的案例联系起来:
- 情况1:我们的模型预测某人实际购物时入店行窃(TP-真实肯定)
- 情况2:我们的模型预测某人在不购物时就入店行窃(FP-误报)
- 案例3:我们的模型预测某人在购物时没有购物(FN-False Negative)
- 情况4:我们的模型预测某人没有购物时就没有入店行窃(TN-真否定)
正式而言,“查全率”是使用此公式定义的。

- 该指标的主要作用是告诉我们:模型在识别相关样本方面的表现如何。
或者
- 我们的模型在捕捉实际的入店行窃者方面有多好?
现在,如果模型没有将任何人归类为入店行窃者,那么查全率将为0。另一方面,如果我们将每个人都标记为“入店行窃者”,查全率为100%,该怎么办?
准确性
有一个度量标准确实在乎对客户的虚假指控,即准确性。,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP).
在前面查全率的分母中,用假阳性FP来代替假阴性FN。
- 在我们正确预测的所有正类中,实际上有多少是正的。
或者
- 我们的模型在不进行虚假指控方面有多好?
至此,您可能已经猜到了,如果我们仅针对模型中的高精度进行优化,将会遇到什么问题。
该模型可以认为:每个人不是扒手,并且精度很高。
recall查全率和精度是相关的,高精度会导致查全率低,而精度低会导致查全率高。
我们显然希望两者都尽可能高,是否有将精度和查全率结合在一起的指标?
F1分数
F₁分数是精确度和查全率的加权调和平均值:

现在,如果我们优化模型以使其具有F₁分数,则可以具有较高的精度和召回率。这转化为我们的模型能够抓住入店行窃者,同时又不会错误地指责无辜的顾客。
该模型可以确定,当它抓住一个扒手时,实际上是一个扒手,并且这个故事结束了。