自然语言可以采用文本或语音的形式,机器学习可用于以文本和语音的形式解决涉及人类自然语言的问题。这被称为自然语言处理,它已经有许多迷人的现实世界应用程序。
非结构化文本,例如文章、新闻、评论或评论,是自然语言数据的常见来源。必须从非结构化数据中检索有用的信息。为了检索这些有用的数据,我们必须完成一系列步骤。
在本文中,我们将使用自然语言工具包 (NLTK)、一个 Python 包以及 Jupyter 笔记本来演示我们需要采取的常规程序来提取这些有用的数据。Anaconda 软件包预装了这些软件包,因此您可以安装它。
这些步骤包括:
1. 分词
这是将多个短语或段落分解为更小的组件(例如单个句子或单词)的过程。要执行这一步,我们需要导入 NLTK 库并下载punkt
import nltk |
然后导入发送的标记器和单词标记器以分别生成句子和单词标记。我们将使用它来标记一个句子,结果如下所示:
from nltk.tokenize import sent_tokenize, word_tokenize |
使用的示例文本是:
'Mary had a little lamb. Her fleece is white as snow'
text = 'Mary had a little lamb. Her fleece is white as snow' |
句子标记器的结果如下所示:
['Mary had a little lamb.', ' Her fleece is white as snow' ] |
在同一个句子上使用单词分词器:
words = word_tokenize(text) |
word tokenizer的结果如下图:
['Mary', 'had', 'a', 'little', 'lamb', '.', 'Her', 'fleece', 'is', 'white', 'as', 'snow' ] |
2. 停用词去除
句子被标记化后,停用词将被删除。停用词是用于结构和语法目的但不为文本提供意义的词。此类词的示例是“is”、“for”等。除此之外,要删除停用词,我们需要下载 nltk 中的停用词。一个例子如下所示
# Downloading the stop words |
# sentence to remove stop words from |
上面代码的结果如下图所示:
['Mary','little', 'lamb', 'Her', 'fleece','white','snow' ] |
从结果中,我们可以看到诸如had, a, is, 和等词as没有被包含在结果中,因为它们没有为句子增加意义而是为结构增加了含义。
3. N-GRAMS
这需要确定一组一起找到的术语。例如,在一篇关于“劳斯莱斯”的文章中,“Rolls Royce”和 "Rolls" 与"Royce" 这两个词几乎肯定会一起出现。如果将“Rolls Royce”保留为一个单一的实体,则可能会从该语言中衍生出更多的含义。单词集合中单词的数量以 n-gram 为单位,可以是 bi-gram、tri-gram 等。下面显示了一个 n-gram 的例子。
from nltk.collocations import * |
# Bi-grams |
结果:
使用tri-grams:
find = TrigramCollocationFinder.from_words(words_without_stopwords) |
结果:
4. 词干
具有相同基本含义的单词可能会因使用时的时态和上下文结构而不同。关闭、关闭和关闭是此类术语的示例。词干提取是将所有这些词返回到它们的根词并让计算机对它们一视同仁的过程。为了说明词干提取,我们将使用不同的句子和 lancaster 词干提取器,如下所示
# New text to be used |
词干提取的结果如下所示,我们可以看到单词“closed”、“close”和“close”返回到词根“clos”,因此计算机将以相同的方式对待它们。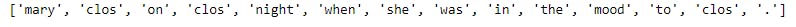
5. 部分语音标签
计算机如何确定短语中的单词是名词、动词、代词还是词性的其他部分。为了说明这一点,我们将使用 NLTK 下载“averaged_perceptron_tagger”,如下所示
nltk.download('averaged_perceptron_tagger') |
结果如下所示,众所周知,Mary 是专有名词,闭合动词等,因为它们已被标记
5. 词义歧义
这就是计算机如何根据使用的上下文来解释单词的含义。有些词根据情况有不同的含义。根据上下文,“洋流”一词既可以指海洋的流动,也可以指现代的任何事物。为了说明这一点,我们将使用 nltk 下载 wordnet,我们将使用 wordnet 来检查单词“bass”的含义
nltk.download('wordnet') |
从下面显示的结果来看,bass 一词有多种含义,从“音乐范围的最低部分”到“Serranidae 科咸水鱼的瘦肉”
我们将举例说明wordnet能否根据上下文判断单词的意思
from nltk.wsd import lesk |
输出如下所示,wordnet 能够根据上下文确定单词的含义
显示另一个例子
sense_2 = lesk(word_tokenize('This sea bass was really hard to catch.'), 'bass') |
这些结果如下所示
这些是在训练自然语言处理模型之前执行的 5 项常见活动。
本文的代码可以在我的 Github 存储库中找到
如果您有任何疑问,请随时发送邮件至[email]olayemibolaji1@gmail.com[/email]