用于现实世界应用程序的机器学习不仅仅是设计花哨的网络和微调参数。事实上,您将花费大部分时间来策划一个好的数据集。让我们一起来完成这个过程的步骤: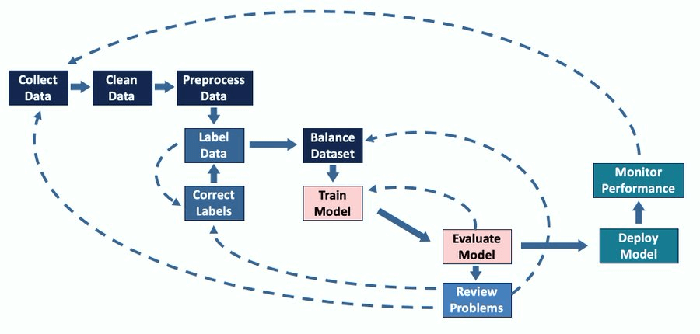
收集数据
我们需要尽可能准确地表示现实世界。如果某些情况下代表性不足,我们将引入抽样偏差。采样偏差很糟糕,因为我们的测试精度很高,但我们的模型在部署时会表现得很差。
让我们建立一个模型来识别自动驾驶汽车的交通灯。我们需要收集不同的数据:
- 光照条件
- 天气条件
- 距离和视点
- 奇怪的变体 :如果我们只采样,垂直交通灯我们将无法检测到横向红绿灯
数据清理
现在我们需要清理所有损坏和不相关的样本。我们需要删除:
- 曝光过度或曝光不足的图像
- 不相关情况下的图像
- 错误的图像 将它们留在数据集中会损害我们模型的性能!
预处理数据
大多数 ML 模型都喜欢它们的数据很好地标准化和适当缩放。糟糕的归一化也可能导致更糟糕的性能
- 裁剪和调整所有图像的大小
- 归一化所有值(通常为 0 均值和 1 标准差。)
数据标签化
手动标签是昂贵的。尽量聪明和自动化:
- 从输入数据生成标签
- 离线使用缓慢但准确的算法
- 在收集过程中预先标记数据
- 开发好的标记工具
- 使用合成数据?
总会有错误 - 人类会犯错误。回顾和迭代!
- 抽查以发现系统问题
- 改进标签指南和工具
- 检查测试结果并修复标签
- 多次标记样本
麻省理工学院最近的一项研究发现,10 个最流行的公共数据集平均有 3.4% 的标签错误(ImageNet 为 5.8%)。这甚至导致作者选择错误的(和更复杂的)模型作为他们最好的模型!
平衡数据集
现实世界的数据集通常是不平衡的——某些类在您的数据中出现的频率比其他类要高得多。您的 ML 模型可能会学习仅预测占据主导类别的数据。
训练和评估模型
这是机器学习课程通常涵盖的部分。现在是尝试不同功能、网络架构、微调参数等的时候了。
迭代过程
在大多数实际应用中,瓶颈不是模型本身,而是数据。有了第一个模型后,我们需要检查它的问题所在并返回:
- 收集和标记更多数据
- 更正标签
- 平衡数据
部署
模型 在生产中部署模型会带来一些额外的限制:
- 速度
- 成本
- 稳定性
- 隐私
- 硬件可用性和集成
我们必须在这些因素和准确性之间找到一个很好的权衡。
监控
随着时间的推移,模型的性能将开始下降,因为世界在不断变化:
- 概念漂移 - 现实世界的分布变化,我们需要一种方法来检测我们有问题的收集数据、标记和重新训练我们的模型。
- 数据漂移 - 数据的属性变化 我们需要检测到这一点,重新训练并再次部署。
总结
这就是现实世界应用程序的典型 ML 管道的样子。请记住这一点:管理
- 一个好的数据集是最重要的事情
- 数据集管理是一个迭代过程
- 监控对于确保长期的良好性能至关重要